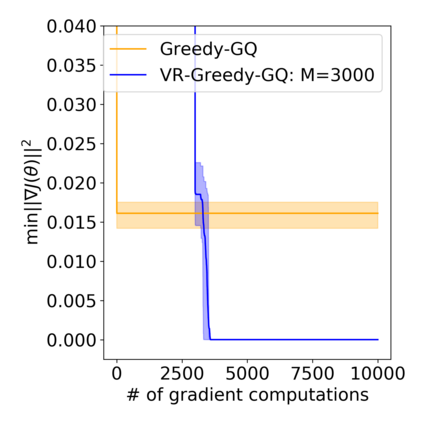
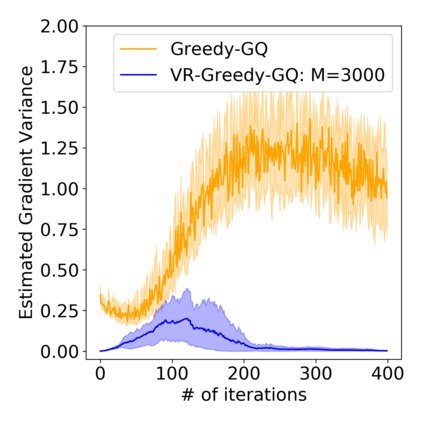
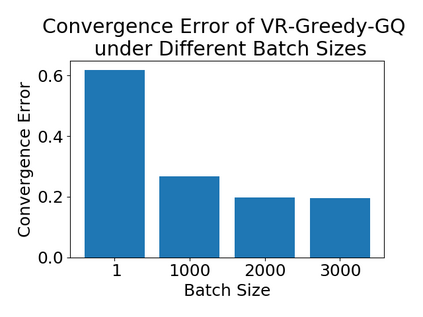
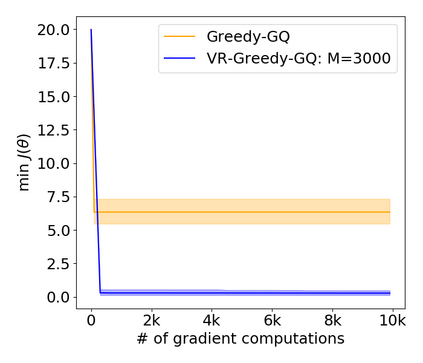
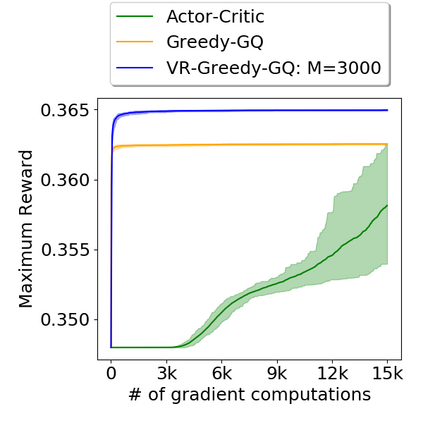
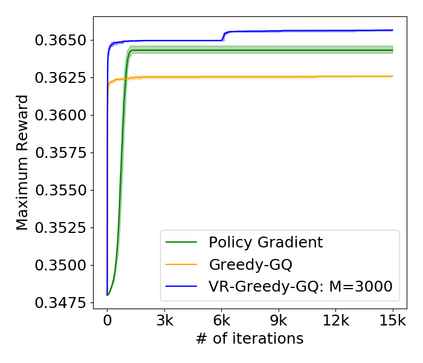
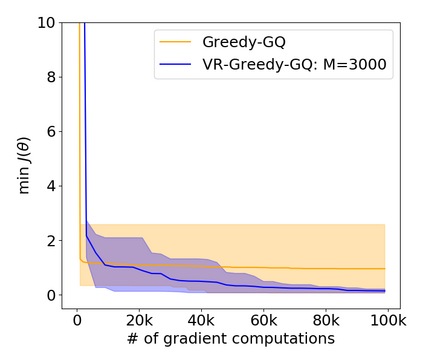
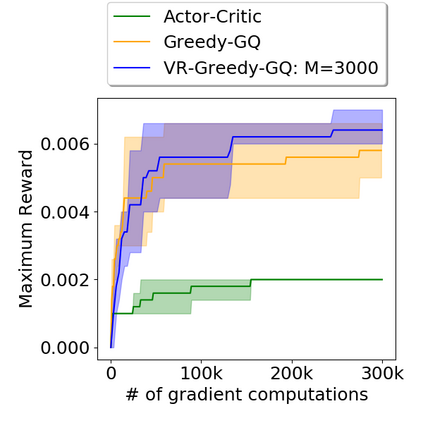
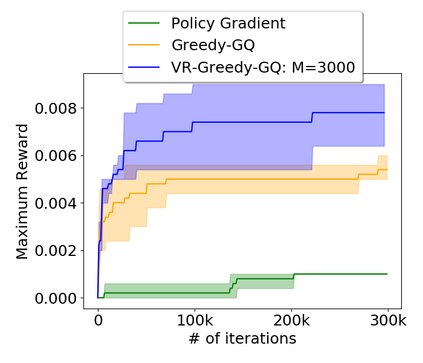
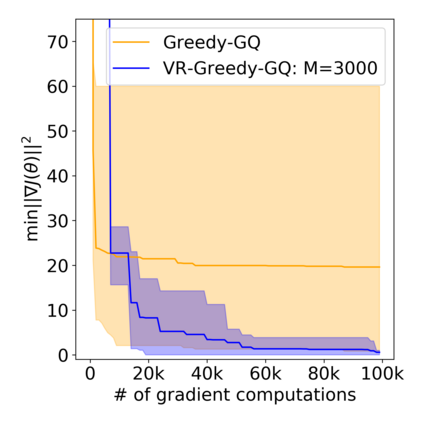
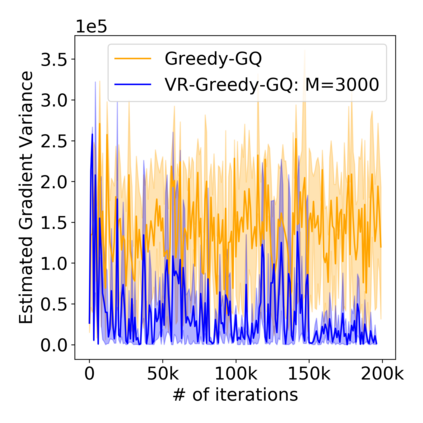
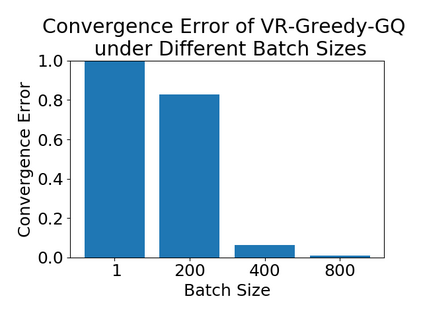
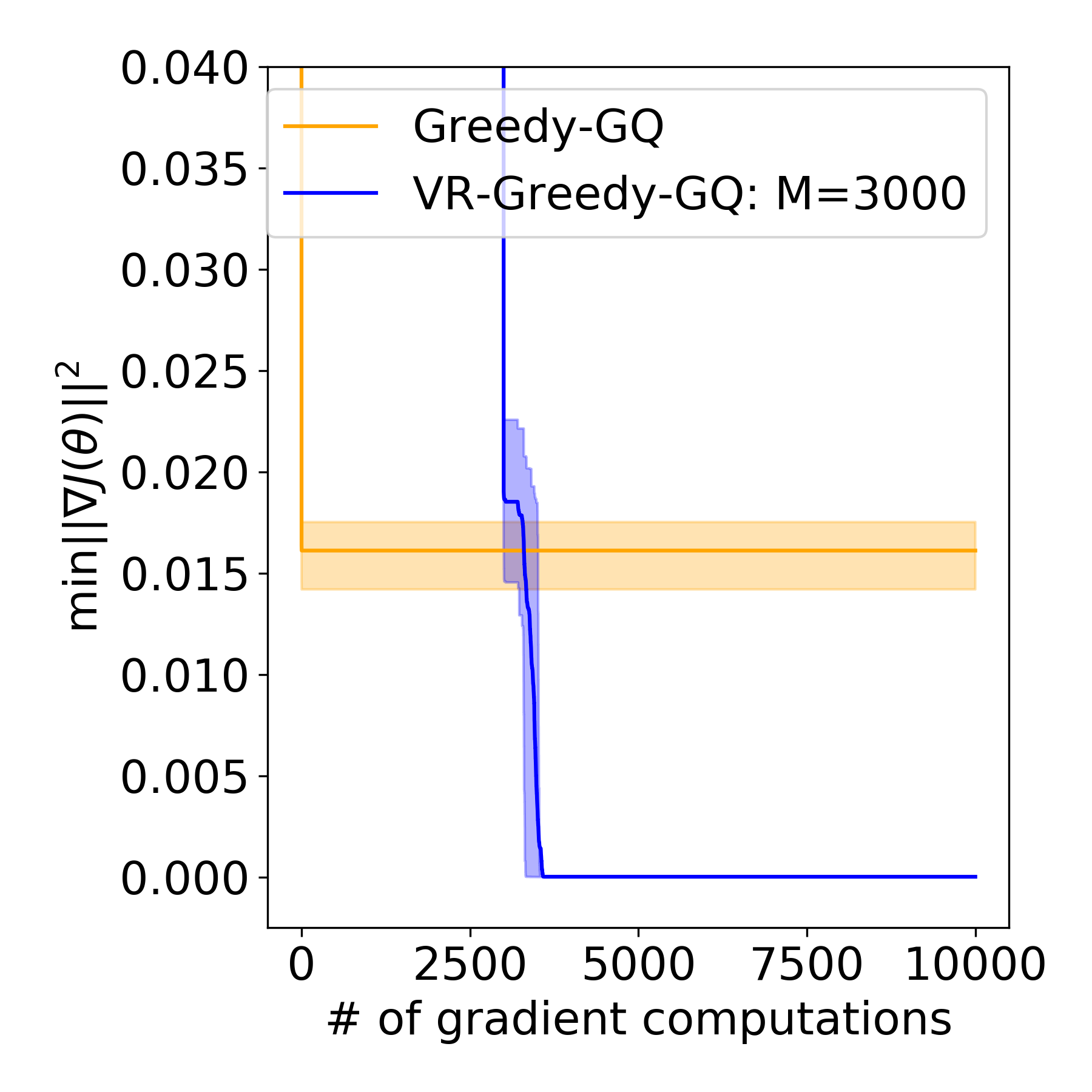
Greedy-GQ is a value-based reinforcement learning (RL) algorithm for optimal control. Recently, the finite-time analysis of Greedy-GQ has been developed under linear function approximation and Markovian sampling, and the algorithm is shown to achieve an $\epsilon$-stationary point with a sample complexity in the order of $\mathcal{O}(\epsilon^{-3})$. Such a high sample complexity is due to the large variance induced by the Markovian samples. In this paper, we propose a variance-reduced Greedy-GQ (VR-Greedy-GQ) algorithm for off-policy optimal control. In particular, the algorithm applies the SVRG-based variance reduction scheme to reduce the stochastic variance of the two time-scale updates. We study the finite-time convergence of VR-Greedy-GQ under linear function approximation and Markovian sampling and show that the algorithm achieves a much smaller bias and variance error than the original Greedy-GQ. In particular, we prove that VR-Greedy-GQ achieves an improved sample complexity that is in the order of $\mathcal{O}(\epsilon^{-2})$. We further compare the performance of VR-Greedy-GQ with that of Greedy-GQ in various RL experiments to corroborate our theoretical findings.
翻译:贪婪- GQ 是一种基于价值的强化学习( RL) 算法, 以优化控制。 最近, 对贪婪- GQ (VR- Greedy- GQ) 的有限时间分析是在线性功能近似和Markovian 样本导致的巨大差异导致的。 在本文中, 我们提议了一种差异性偏差- GQ (VR- Greedy- GQ) 算法, 用于非政策性最佳控制。 特别是, 算法应用基于 SVRG 的变差减少方案, 以降低两次时间尺度更新的随机偏差。 我们研究VR- Greedy- GQ 在线性功能近似和Markovian 抽样下的定时性趋同, 并显示算法比最初的Greed- GQQ(VR- GQQQ) 更准确的偏差和变异性GGQQQ 。 特别是, 我们证明V- G- GLQQ 的变异性变变的变GQ。