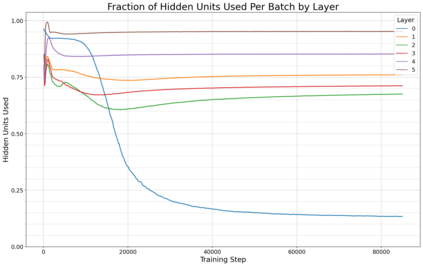
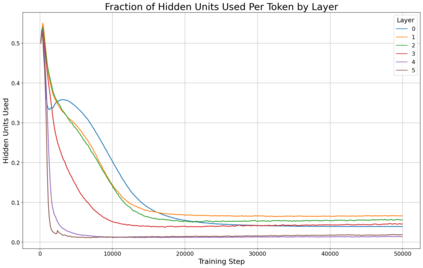
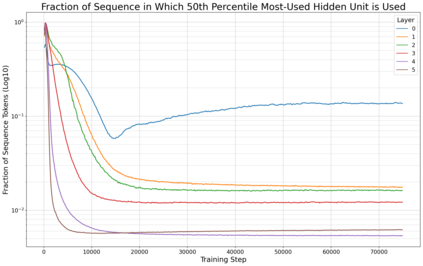
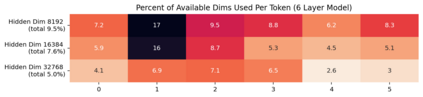
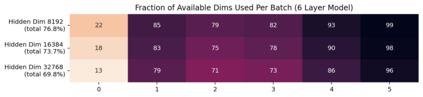
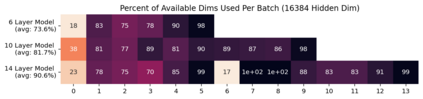
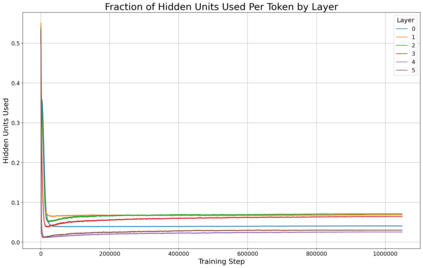
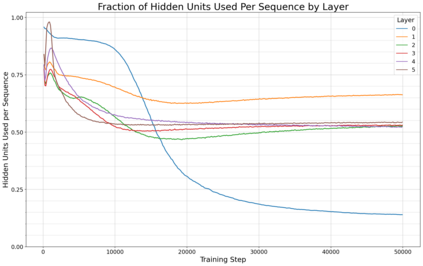
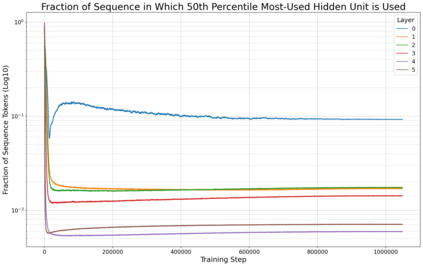
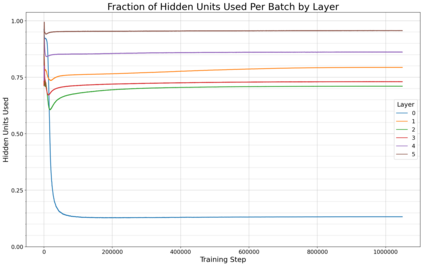
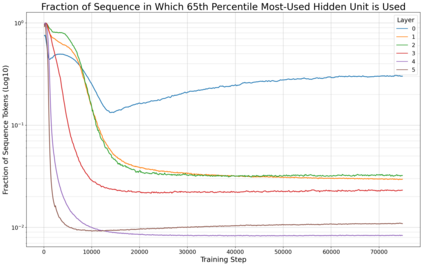
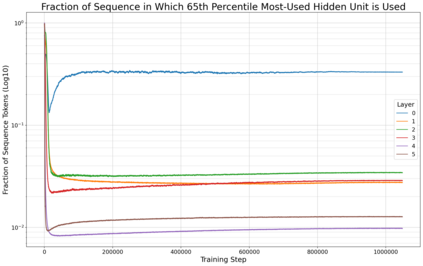
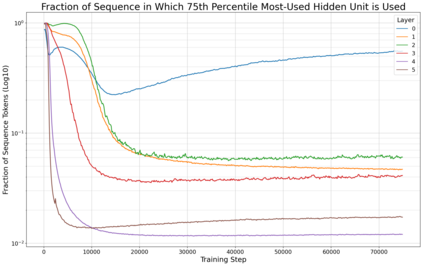
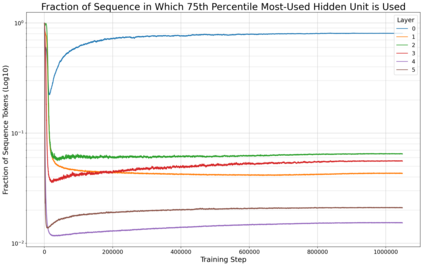
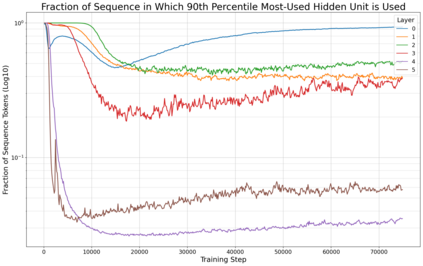
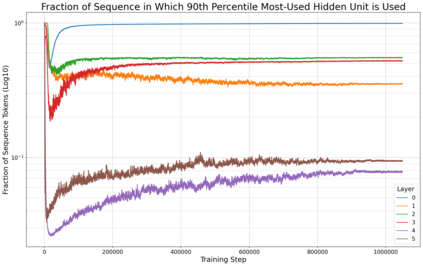
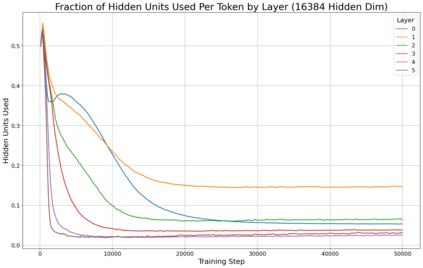
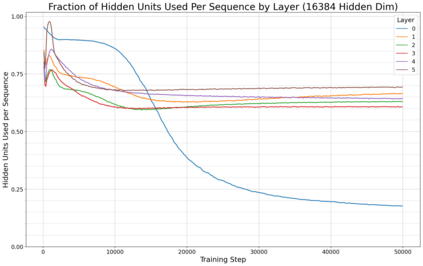
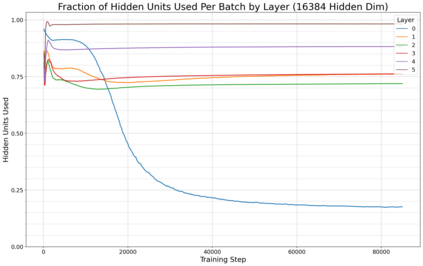
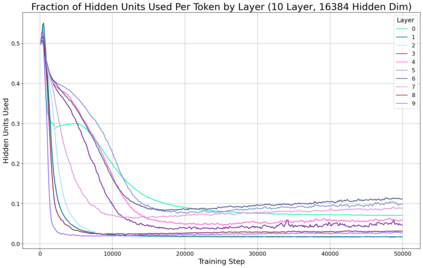
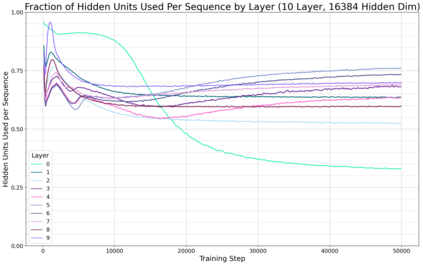
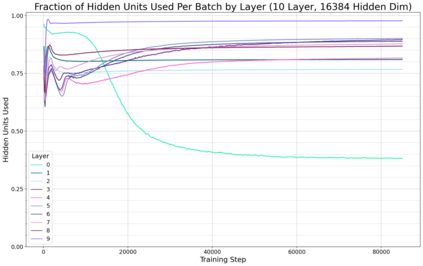
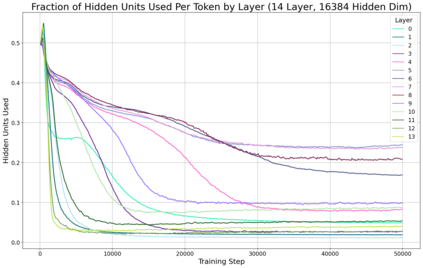
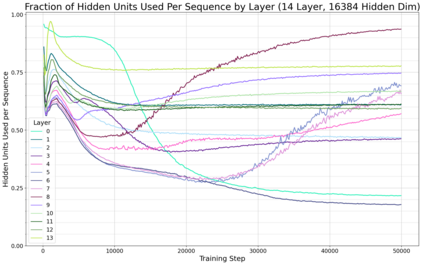
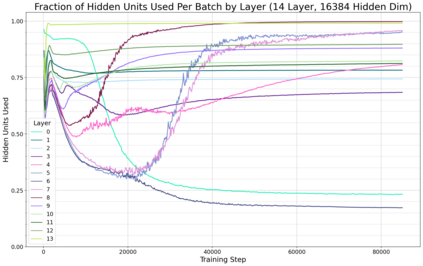
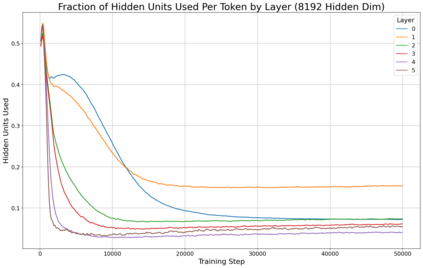
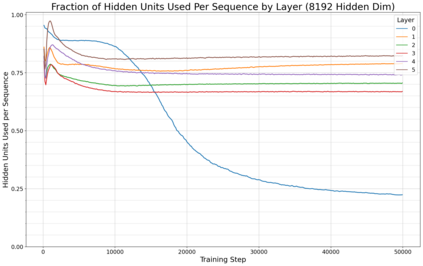
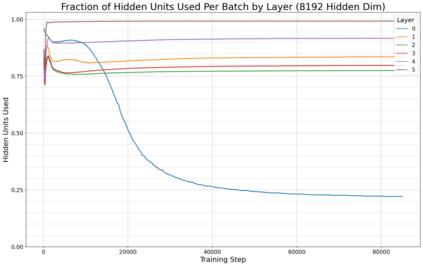
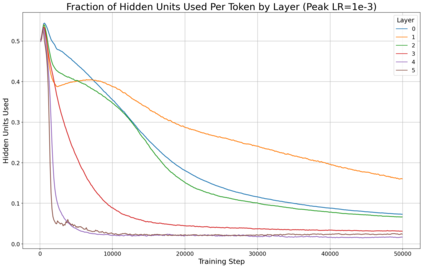
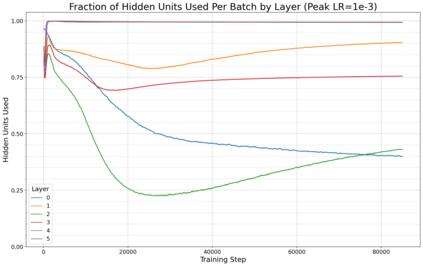
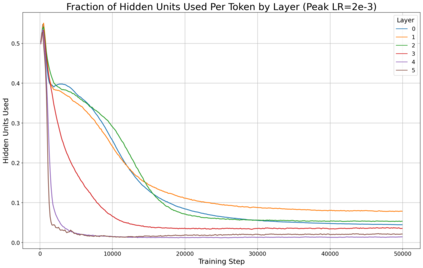
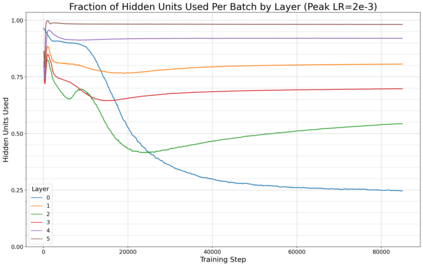
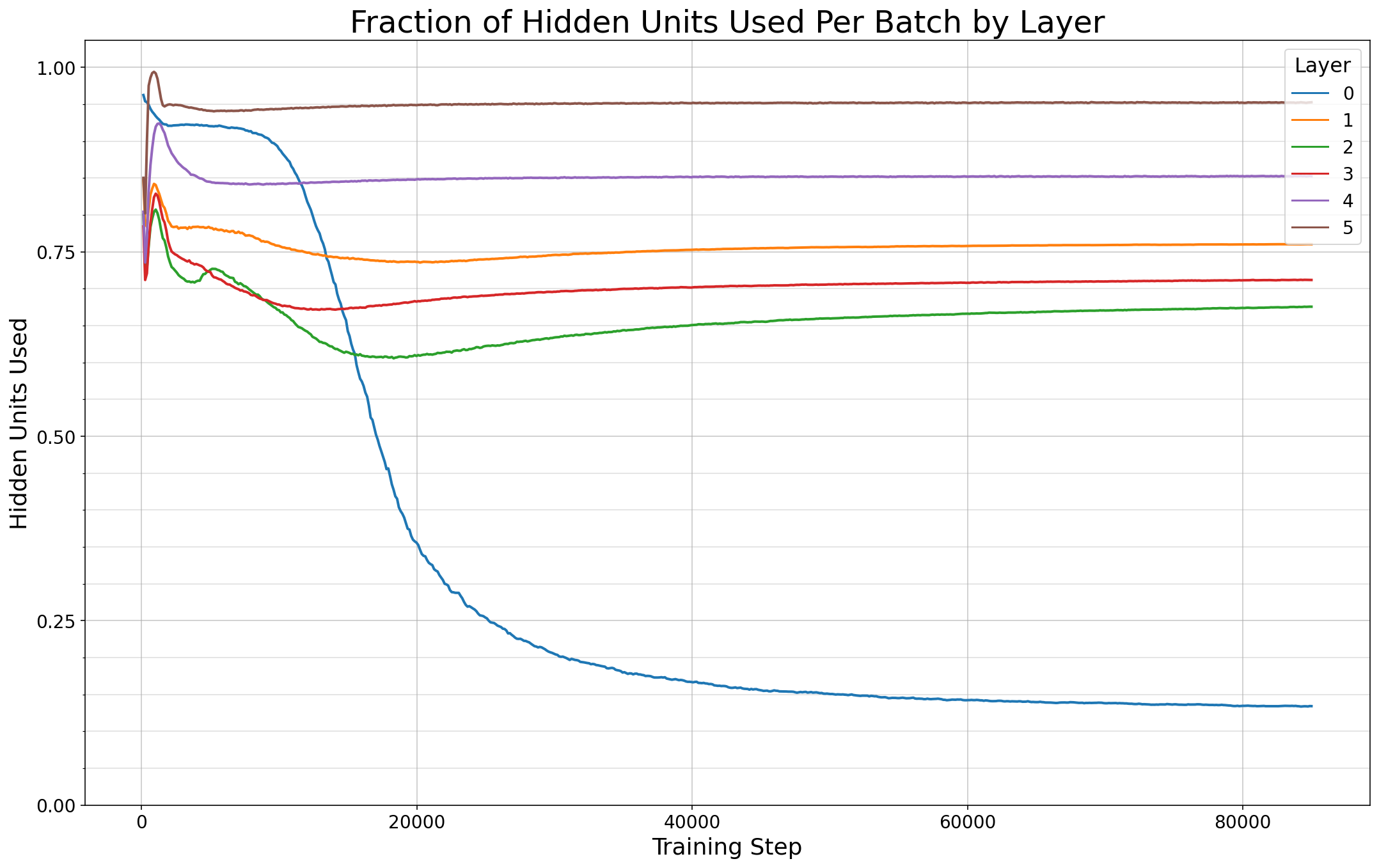
Previous work has demonstrated that MLPs within ReLU Transformers exhibit high levels of sparsity, with many of their activations equal to zero for any given token. We build on that work to more deeply explore how token-level sparsity evolves over the course of training, and how it connects to broader sparsity patterns over the course of a sequence or batch, demonstrating that the different layers within small transformers exhibit distinctly layer-specific patterns on both of these fronts. In particular, we demonstrate that the first and last layer of the network have distinctive and in many ways inverted relationships to sparsity, and explore implications for the structure of feature representations being learned at different depths of the model. We additionally explore the phenomenon of ReLU dimensions "turning off", and show evidence suggesting that "neuron death" is being primarily driven by the dynamics of training, rather than simply occurring randomly or accidentally as a result of outliers.
翻译:暂无翻译