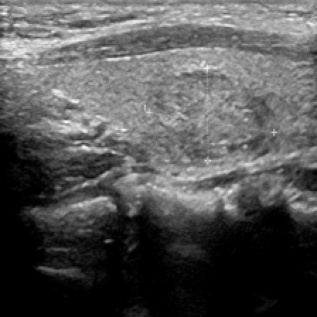
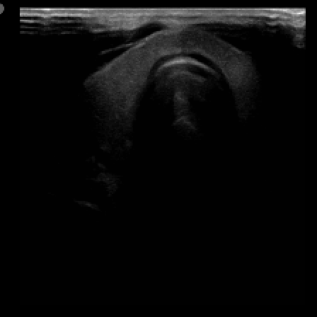
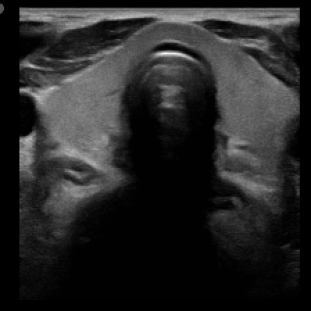
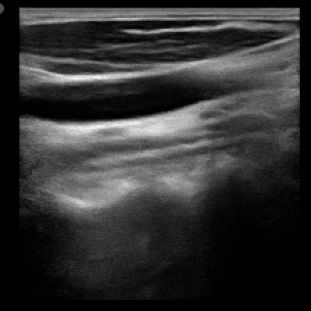
We propose a novel approach that adapts hierarchical vision foundation models for real-time ultrasound image segmentation. Existing ultrasound segmentation methods often struggle with adaptability to new tasks, relying on costly manual annotations, while real-time approaches generally fail to match state-of-the-art performance. To overcome these limitations, we introduce an adaptive framework that leverages the vision foundation model Hiera to extract multi-scale features, interleaved with DINOv2 representations to enhance visual expressiveness. These enriched features are then decoded to produce precise and robust segmentation. We conduct extensive evaluations on six public datasets and one in-house dataset, covering both cardiac and thyroid ultrasound segmentation. Experiments show that our approach outperforms state-of-the-art methods across multiple datasets and excels with limited supervision, surpassing nnUNet by over 20\% on average in the 1\% and 10\% data settings. Our method achieves $\sim$77 FPS inference speed with TensorRT on a single GPU, enabling real-time clinical applications.
翻译:暂无翻译