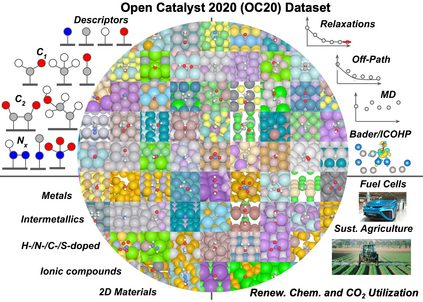
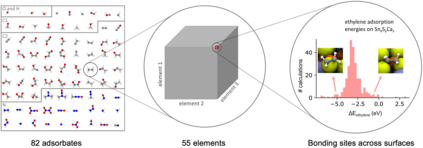
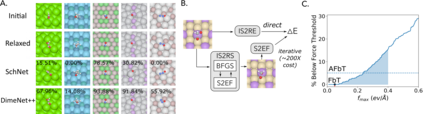
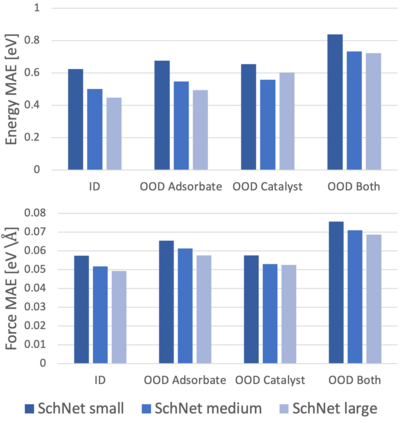
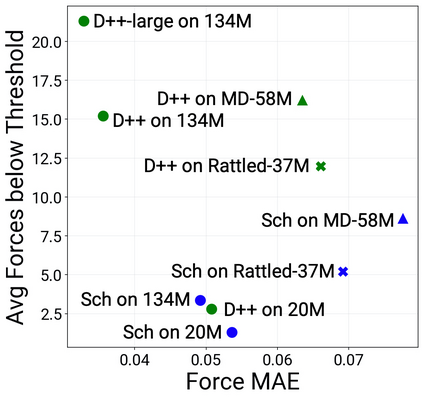
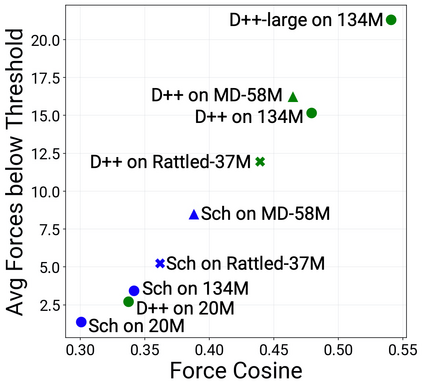
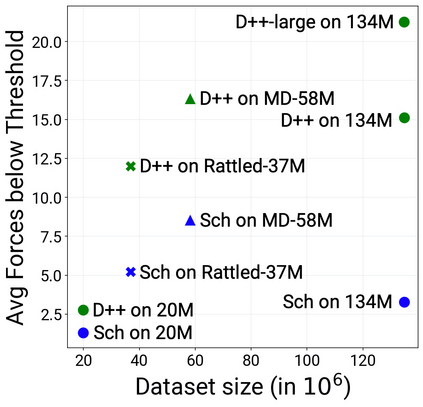
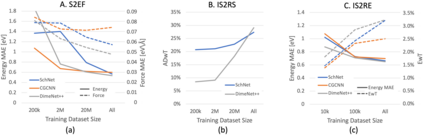
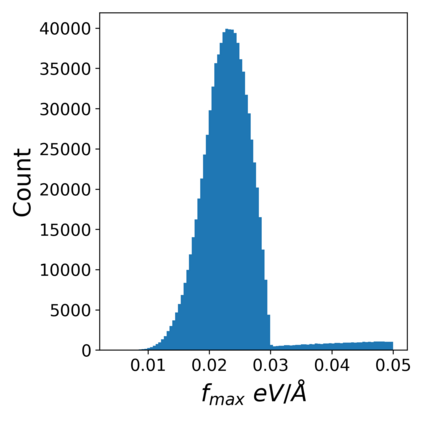
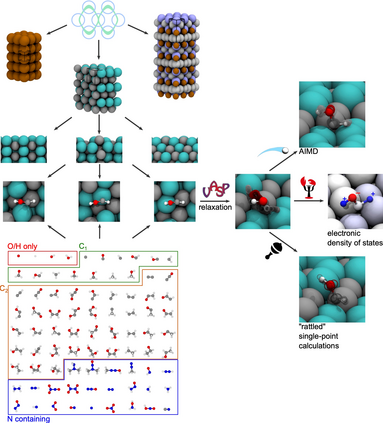
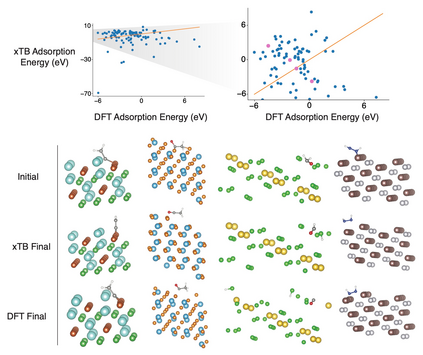
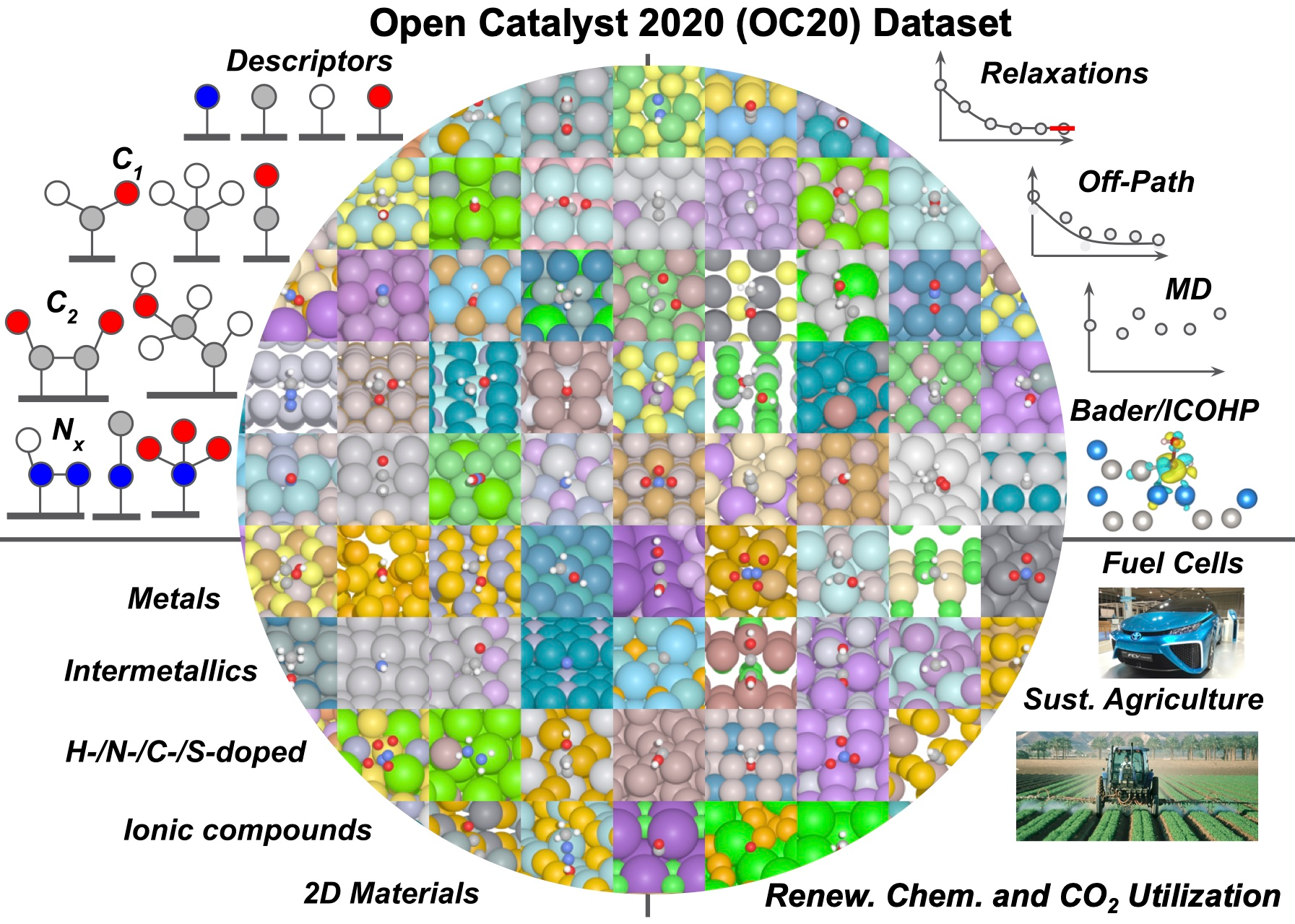
Catalyst discovery and optimization is key to solving many societal and energy challenges including solar fuels synthesis, long-term energy storage, and renewable fertilizer production. Despite considerable effort by the catalysis community to apply machine learning models to the computational catalyst discovery process, it remains an open challenge to build models that can generalize across both elemental compositions of surfaces and adsorbate identity/configurations, perhaps because datasets have been smaller in catalysis than related fields. To address this we developed the OC20 dataset, consisting of 1,281,040 Density Functional Theory (DFT) relaxations (~264,890,000 single point evaluations) across a wide swath of materials, surfaces, and adsorbates (nitrogen, carbon, and oxygen chemistries). We supplemented this dataset with randomly perturbed structures, short timescale molecular dynamics, and electronic structure analyses. The dataset comprises three central tasks indicative of day-to-day catalyst modeling and comes with pre-defined train/validation/test splits to facilitate direct comparisons with future model development efforts. We applied three state-of-the-art graph neural network models (CGCNN, SchNet, Dimenet++) to each of these tasks as baseline demonstrations for the community to build on. In almost every task, no upper limit on model size was identified, suggesting that even larger models are likely to improve on initial results. The dataset and baseline models are both provided as open resources, as well as a public leader board to encourage community contributions to solve these important tasks.
翻译:催化发现和优化是解决许多社会和能源挑战的关键,其中包括太阳能燃料合成、长期能源储存和可再生肥料生产。尽管催化界在计算催化剂发现过程应用机器学习模型方面做出了大量努力,但在建立模型方面仍是一个公开的挑战,这些模型可以覆盖表层和吸附体的元素构成,或许是因为在催化方面数据集比相关领域要小。为了解决这个问题,我们开发了OC20数据集,其中包括1,281,040 Density 功能 Thetory(DFT)放松(~264,890,000个单一点评价),在广泛的材料、表面和粘索贝(硝基、碳和氧化学化学)过程中应用机器模型,我们用随机的扰动结构、短期分子动态动态和电子结构分析来补充这一数据集。 数据集由三个核心任务组成,表明日常催化剂模型的建模,并配有事先确定的火车/鉴定/测试分解(DFT)放松(~264,890,90,000个点的单点评价) 放松(~264,890,000个初步评估) 社区对材料、表面和表面的单点评估模型做出直接比较(Nexorate) 贡献) 贡献。我们将这些数据作为每个模型的模型的建模的模型的模型的模型中,这些模型的建模都提供这些模型的建成了一个可能的模型,这些模型是用于每个模型的建模模的建模的建模的建模的建于每个模型。