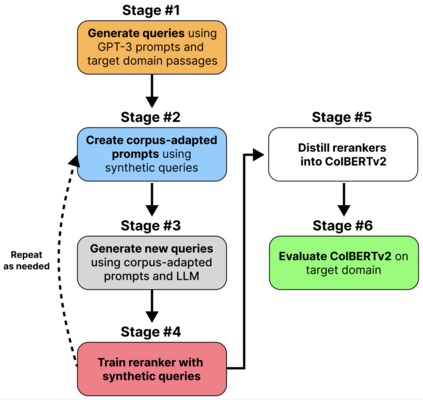
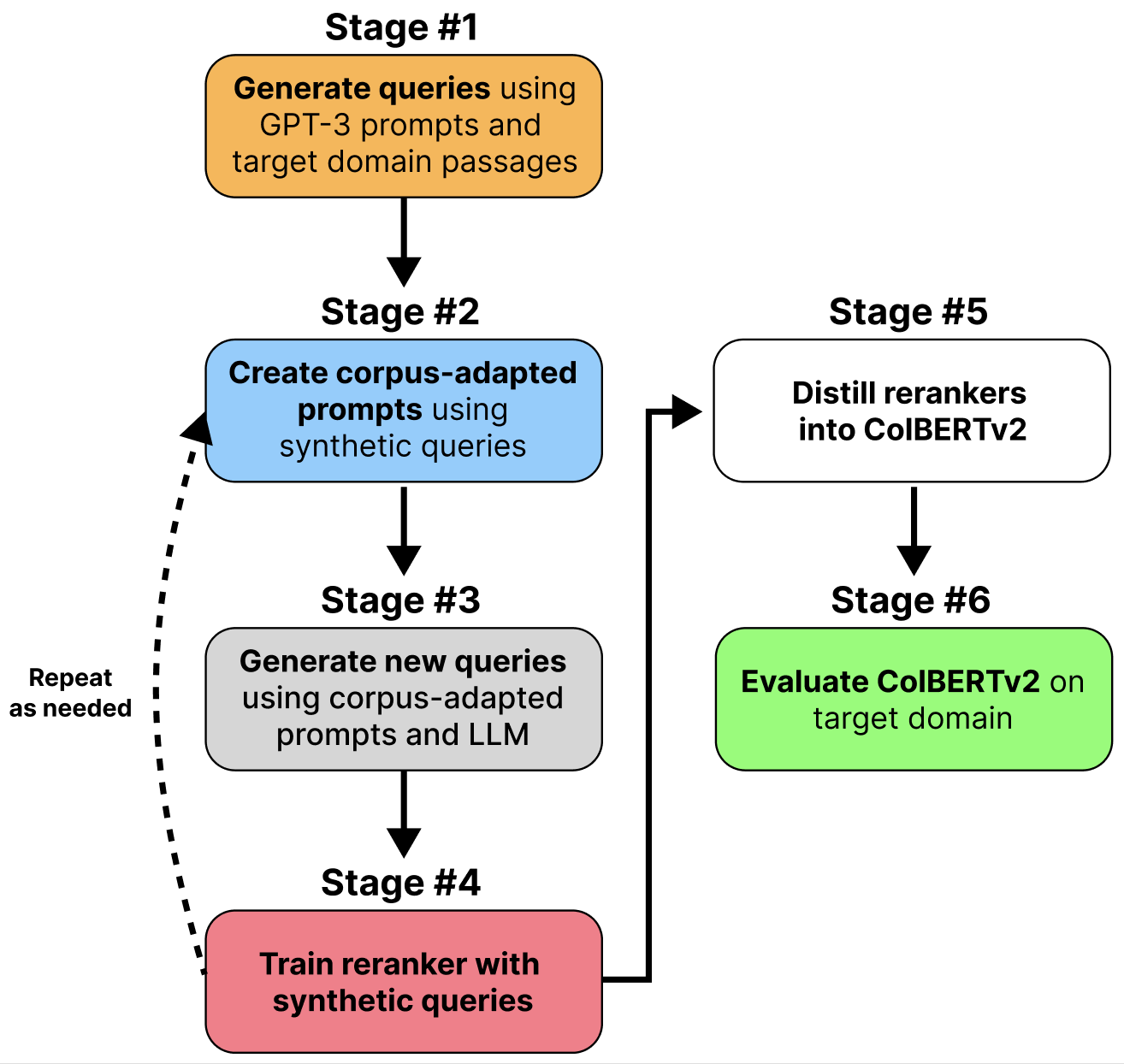
Many information retrieval tasks require large labeled datasets for fine-tuning. However, such datasets are often unavailable, and their utility for real-world applications can diminish quickly due to domain shifts. To address this challenge, we develop and motivate a method for using large language models (LLMs) to generate large numbers of synthetic queries cheaply. The method begins by generating a small number of synthetic queries using an expensive LLM. After that, a much less expensive one is used to create large numbers of synthetic queries, which are used to fine-tune a family of reranker models. These rerankers are then distilled into a single efficient retriever for use in the target domain. We show that this technique boosts zero-shot accuracy in long-tail domains, even where only 2K synthetic queries are used for fine-tuning, and that it achieves substantially lower latency than standard reranking methods. We make our end-to-end approach, including our synthetic datasets and replication code, publicly available on Github: https://github.com/primeqa/primeqa.
翻译:暂无翻译