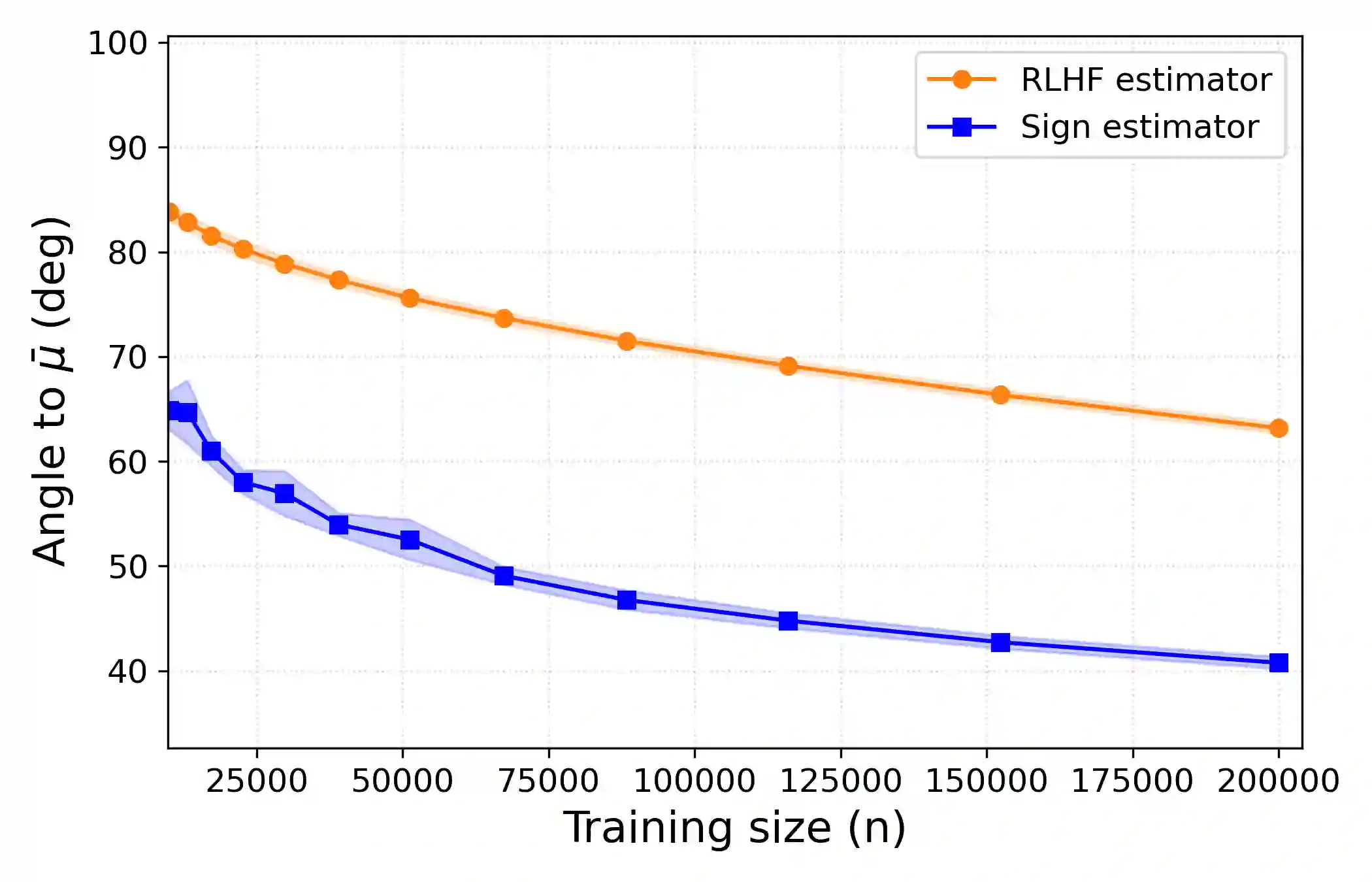
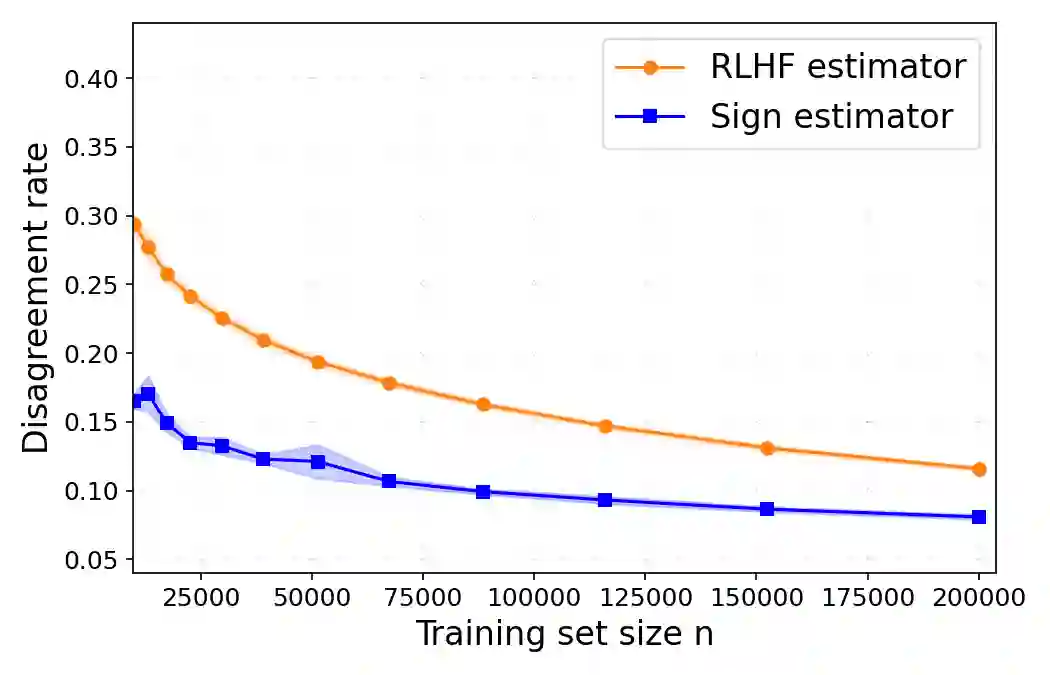
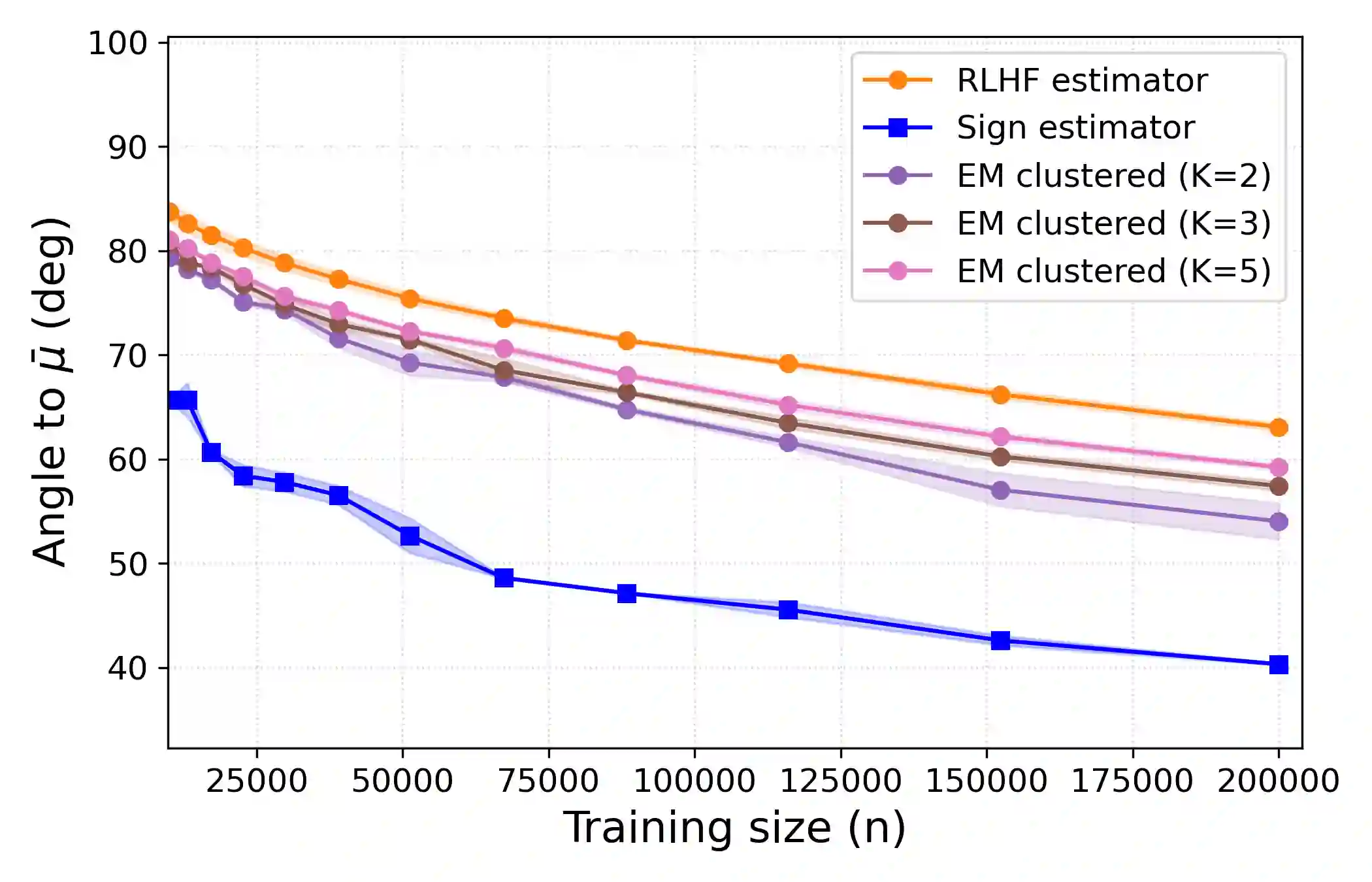
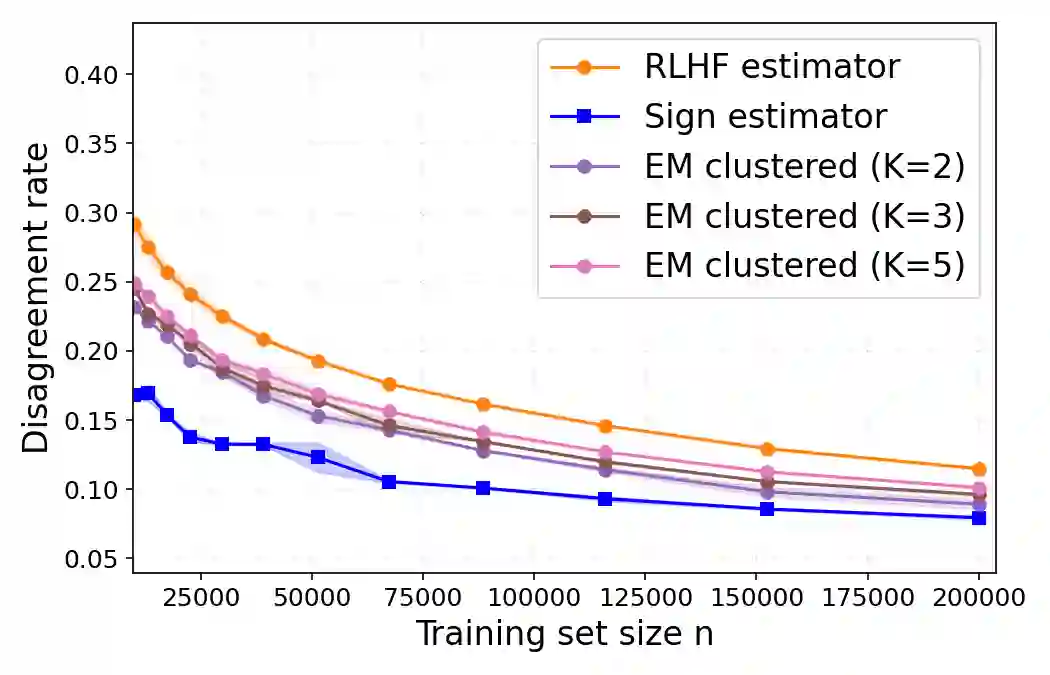
Traditional LLM alignment methods are vulnerable to heterogeneity in human preferences. Fitting a na\"ive probabilistic model to pairwise comparison data (say over prompt-completion pairs) yields an inconsistent estimate of the population-average utility -a canonical measure of social welfare. We propose a new method, dubbed the sign estimator, that provides a simple, provably consistent, and efficient estimator by replacing cross-entropy with binary classification loss in the aggregation step. This simple modification recovers consistent ordinal alignment under mild assumptions and achieves the first polynomial finite-sample error bounds in this setting. In realistic simulations of LLM alignment using digital twins, the sign estimator substantially reduces preference distortion over a panel of simulated personas, cutting (angular) estimation error by nearly 35% and decreasing disagreement with true population preferences from 12% to 8% compared to standard RLHF. Our method also compares favorably to panel data heuristics that explicitly model user heterogeneity and require tracking individual-level preference data-all while maintaining the implementation simplicity of existing LLM alignment pipelines.
翻译:传统的大语言模型(LLM)对齐方法易受人类偏好异质性的影响。对成对比较数据(例如针对提示-补全对)拟合一个朴素概率模型,会导致对群体平均效用的估计不一致——这是衡量社会福利的经典指标。我们提出了一种新方法,称为符号估计器,通过在聚合步骤中用二元分类损失替代交叉熵损失,提供了一种简单、可证明一致且高效的估计器。这一简单修改在温和假设下恢复了一致的有序对齐,并在此设置中首次实现了多项式有限样本误差界。在使用数字孪生模拟LLM对齐的现实仿真中,符号估计器显著减少了模拟人物面板上的偏好失真,与标准的RLHF相比,将(角度)估计误差降低了近35%,并将与真实群体偏好的不一致性从12%降至8%。我们的方法也优于那些显式建模用户异质性且需要追踪个体层面偏好数据的面板数据启发式方法——同时保持了现有LLM对齐流程的实现简洁性。