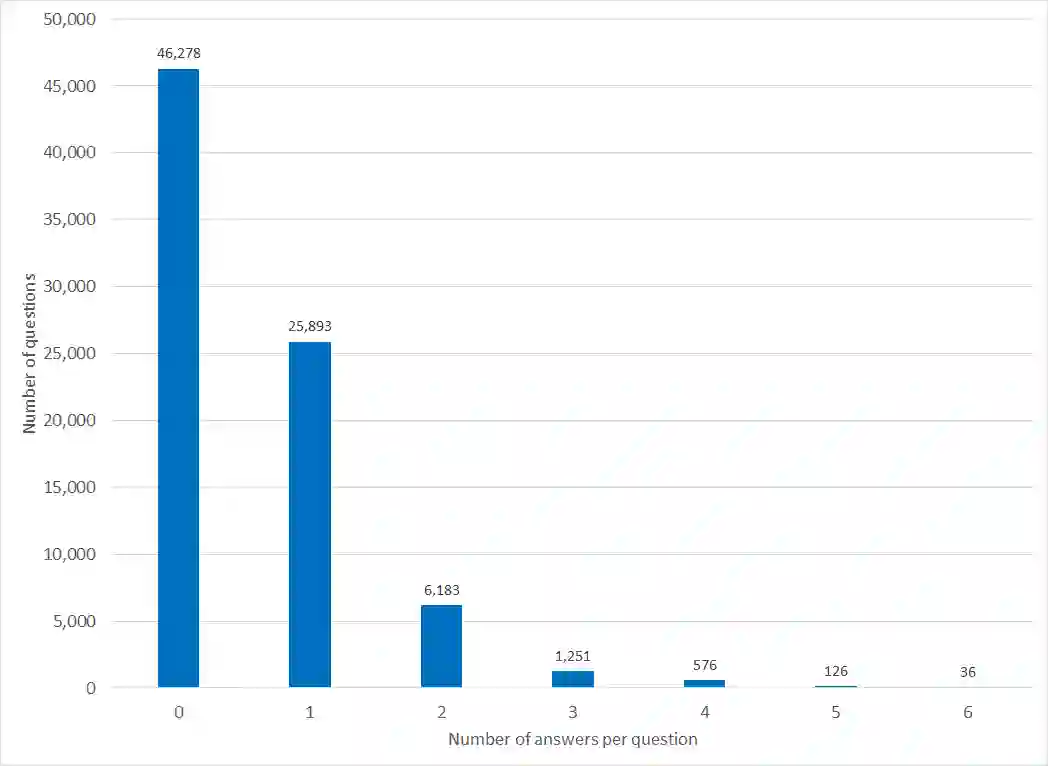
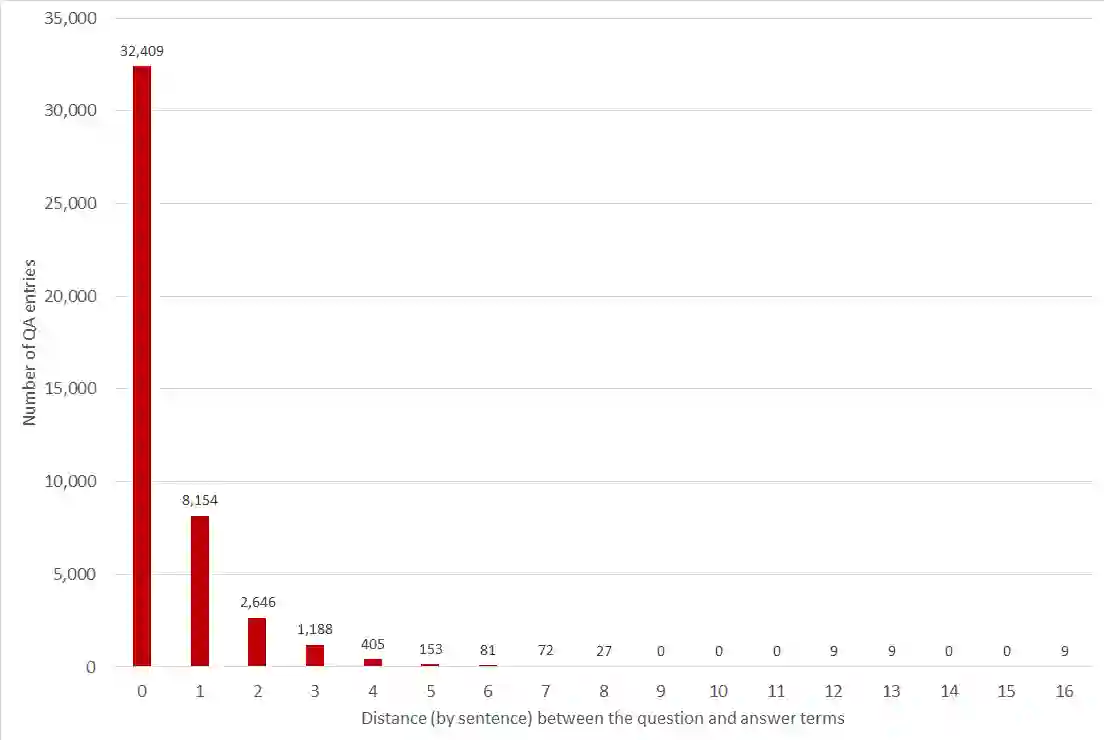
Objectives Create a dataset for the development and evaluation of clinical question-answering (QA) systems that can handle multi-answer questions. Materials and Methods We leveraged the annotated relations from the 2018 National NLP Clinical Challenges (n2c2) corpus to generate a QA dataset. The 1-to-0 and 1-to-N drug-reason relations formed the unanswerable and multi-answer entries, which represent challenging scenarios lacking in the existing clinical QA datasets. Results The result RxWhyQA dataset contains 91,440 QA entries, of which half are unanswerable, and 21% (n=19,269) of the answerable ones require multiple answers. The dataset conforms to the community-vetted Stanford Question Answering Dataset (SQuAD) format. Discussion The RxWhyQA is useful for comparing different systems that need to handle the zero- and multi-answer challenges, demanding dual mitigation of both false positive and false negative answers. Conclusion We created and shared a clinical QA dataset with a focus on multi-answer questions to represent real-world scenarios.
翻译:为开发和评估临床问答系统创建一套能够处理多答问题的数据集。我们利用了2018年国家NLP临床挑战(n2c2)中附加注释的关系来生成QA数据集。1至0和1至1至N的药物理性关系形成了无法回答和多答的条目,这些条目代表了现有临床问答数据集所缺乏的具有挑战性的情景。结果 RxwisQA数据集包含91 440 QA条目,其中一半是无法回答的,21%(n=19 269)的应答对象需要多个答案。数据集符合社区审读的斯坦福问答数据集(SquAD)格式。 RxwiceQA有助于比较不同系统,这些系统需要处理零和多答挑战,要求双管齐下的正反答案。结论我们创建并共享一个临床QA数据集,重点是多答问题,以代表现实世界情景。