机器翻译中的强化学习:优点、缺点以及不足
作者:Tobias Lee
知乎专栏:NLPer 的成长之路
原文链接,可点击文末"阅读原文"直达:
https://zhuanlan.zhihu.com/p/101324828
本文译自 RL in NMT: The Good, the Bad and the Ugly,作者是海德堡大学的 PhD Julia Kreutzer,翻译已获得作者授权,并且她欢迎大家对文章提出反馈,可以邮件和她交流(PS:作者非常 nice)。
在这篇文章中,我会向大家介绍在神经机器翻译(NMT)中使用强化学习(RL)的三个方面:
优点:能够和传统的极大似然估计(MLE)方法结合
缺点:需要使用一些 tricks
不足:在使用 RL 的时候忽略了一些最近提出的方法
希望这篇文章能够帮助 NMT 的研究者们提升他们模型的 BLEU 分数。
除了这三个方面以外,这篇文章还希望能够对最近的 NMT 研究中一些受 RL 启发得到的一些目标函数进行批判性的思考。我们将会首先回顾一下 NMT 中的 RL 训练方法,接下来会根据 Wu 等人的一些研究来讨论以下三个问题:
如何将 NMT 和 RL 更好地结合?
为什么能够在监督学习中从 RL 目标函数获得好处?
目前这个领域的挑战在哪里?
背景回顾
这一节中,我们会介绍 RL 用以整合 reward。
MLE
极大似然估计(Maximum Likelihood Estimation,MLE)是 NMT 中常用的目标函数,我们经常会利用它来训练一个参数为 


期望奖赏
怎么把 RL 加入进来呢?一个想法就是是引入奖励(reward)以鼓励模型产生一个能够获得较高 reward 的输出,而不仅仅是最大化 reference 的概率,而后者是和 MLE 是等价的。实际应用的时候,这个 reward 可以是被模拟产生的,典型的就是 Sentence-Level 的 BLEU 分数,这样,获得较高 reward 就意味着更高的 BLEU 分数。你可能会问,这是唯一的办法吗?问得好,我们马上就要讨论这个问题。先假设存在 

Policy Gradient
和 MLE 方法最大的不同的就是,RL 方法对于参数 

这样,我们就可以通过诸如蒙特卡洛采样的方法来估计梯度并且利用随机梯度下降的方法来训练模型了。这就是著名的 REINFORCE 算法。REINFORCE 旨在利用一个样本来为每个输入估计其梯度:

这和 RL 的联系之处在哪呢?在 RL 中,更准确地说是在 policy search 中,我们可以把 

Training
NMT 的实际应用之中,我们会对模型输出进行 softmax 得到一个的词表概率分布,然后通过采样或是 beam search 的方法来得到输出,进而来估计梯度。典型的训练方法有两种:一是依次或者交替训练两个目标函数,比如在 RL 之前利用 MLE 对 NMT 模型进行预训练;二同时训练两个目标,例如通过线性插值来得到一个混合的目标函数。
Recent Trends of RL in NMT
如果我们只关心 BLEU 分数的话,那么单独的 RL 是无法起到作用的
在 EMNLP 2018 的一篇文章 A Study of RL for NMT 之中,作者观察到一个现象:基于 RL 提出的的目标函数已被证明可以提高 NMT 的质量,但通常是在使用了大量的 trick 并且 baseline 非常弱的情况下得到的。他们提出了一个问题:将这些技巧的各种变体与从单语语料中学习结合起来,那么 RL 还能够继续 work 吗?
为了解决这个问题,他们研究发现,使用 RL 可以在调好的 baseline 模型上带来些微(marginal)的提升,同时结合 MLE 和单语语料。但是,最大的改进来自利用附加的单语数据(这不是什么大新闻了)。但是这里评估的受 RL 启发的方法缺乏与更先进技术的比较,并且假定可以使用参考翻译。让我们来仔细看看!
RL Tricks
降低方差
之前提到的梯度估计方法,可能有比较大的方差,那么这就会给模型优化带来困难,比如会降低收敛速度甚至无法收敛。这篇文章考虑使用两个基于 baseline 的方法来缓解这一问题:
对 reward 求平均作为 Baseline:在 reward 中减去平均的 reward 来降低方差
直接学习一个 baseline:利用一个其他模型的输出来作为 baseline,比如一个回归模型
这里的 baseline(译者注:和前面的 baseline 不是一个哦)实际上在一开始的 REINFORCE 论文中就已经提出,可以解释为加性控制变量 (Ross 2013)。Actor-Critic(AC)方法更进一步,用一个可训练的 critic 模型来替换掉 reward,简单来说,就是由一个 critic model 负责给出这个 reward,也已经有一些工作尝试将其应用到了 NMT 中,比如 Bahdanau et al. 2017, Ngyuen et al. 2017。尽管在实验上被证明非常地有效,但是 Greensmith et al. 2004 证明以上的方法不是最优的,并且实际上可以学习到具有最小方差的最优 baseline。
另外,有一个很重要的点被目前的研究所忽略,那就是用于估计梯度的蒙特卡洛采样的数目对于方差有着决定性的影响。如果 reward 是模拟出来的(比如根据 reference 计算 sentence-bleu),那为什么不多次采样并且在一个子集上对梯度进行平均呢?你可能对这个想法感到熟悉,因为这就是 minimum risk training 所作的(Shen et al. 2016)。
在 Wu et al. 2018 中实验结果表明,使用学习的 baseline 没有观察明显的效果,这与例如 Bahdanau 和 Kreutzer 等人的经验相矛盾。不过,Wu 等人提出从“经济角度”来看没有必要设立奖励基准的结论可能有点过于笼统。
Reward Shaping
如果我们要等到句子完成之后(译者注:一般是产生 <EOS> 后认为句子已经生成完整),我们才能够得到 reward 的话,那么模型从何得知究竟是哪里出了问题呢?这个问题称之为 credit assignment,并且常常通过 reward shaping (Ng et al. 1999) 来解决。
Wu et al. 2018 研究了Bahdanau et al. 2017 的实现:对于输出中的每个元素,其 reward 是当前输出的 reward 和除去这一元素的部分输出的 reward 的差值: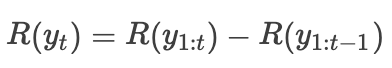
但是这真的解决了 credit assignment 的问题吗?这个问题的本质在于我们需要等到句子完成之后才能够从环境获得 reward。只要 reference 被用来计算 reward,那么我们就不可避免地接收到有所延迟 reward。另外一种方法,逐个比较每个输出和 reference 的单词然后得到一个 token-level 的 reward。Petrushkov et al. 2018 就基于此,为每个 token 提出了一种简单的二值 reward。
正如前面提到的,使用 reference 来计算 reward 其实是在逃避真正的问题。如果没有 reference,我们无法为任何一个部分完成的翻译计算 BLEU,那该怎么办?为此,Ngyuen et al. 2017 采用了 advantage-actor critic(A2C)。其核心是利用一个 Critic 网络来预测每个 token 未来可能获得的 reward,尽管这个 reward(在这里,我们指的是 BLEU)要到句子结束才能够计算。然而,这个研究没有和 reward shaping 做一个比较,这或许是它的一个缺点。
所以 Reward Shaping 有用吗?Wu 的研究中发现实际的提升非常之小,这让这成为了一个悬而未决的问题。
使用单语语料
目标端语料:使用单语语料来提升机器翻译的效果最近非常流行,因为简单的方法也能起到很好的效果。如果有额外的目标端语料的话,back-translation 是一个非常好用的机制,Sennrich et al. 2016 展现了这一点。需要做的额外工作就是训练一个反方向的翻译模型,在这基础之上我们能够和目标端语料构建一个伪平行语料(pseudo-parallel corpus),然后用这个语料进行训练,无论是否使用 reward 都可以。
源端语料:Wu et al. 2018 提出源端的额外语料同样可以带来提升的效果。考虑目前的一些 self-training 的技术,核心思想还是构建伪平行语料,让其先生成一部分目标语言的句子,来提升自己的性能。当然,我们需要假定生成的目标句子足够的好,从而能够为模型训练带来帮助。实践之中,常常会使用 beam search 来生成相比采样或者 greedy search 更高质量的句子。
那么,伪平行语料的质量重要吗?如果他们作为 RL 的目标函数,那么他们只是用来模拟 reward,本身 reward 就带有一定的 noise,所以语料中的 noise 或许会被“吸收”掉一些。此外,在有监督的 MLE 训练中,Wu 把伪平行语料加入到了一个更大的原始平行语料之中,所以这一部分的 noise 显得格外的微不足道。然而,这个问题还没有被系统的研究过。
NMT as an RL problem
我们目前只(误)用了 RL 中的一小部分方法
目前 NMT 中的 RL 的使用,局限在使用 policy gradient(pg) 来 fine-tune 一个已经 train 好的模型。那么其他的 RL 算法呢?很多 RL 研究者早在几十年前就提出了目前的算法,并且已经设计出相比 pg 更加复杂的训练算法,比如 Trust Region Policy Optimization(TRPO)以及 Proximal Policy Optimization (PPO),这些算法可以另起一篇文章来讨论。但是,目前只有 policy gradient 和 actor-critic 在结构化预测任务中被广泛使用,那么有什么问题在阻止我们使用新的 RL 算法呢?
实际上,将 NMT 问题,或者更 general 的结构化预测问题,转化成一个标准的 MDP 问题(译者注:马尔科夫决策过程,RL 的基础)是非常复杂的。首先,我们需要定义什么是 environment, state,以及 reward 从何而来。比较一下 Wu et al. 2018, Ngyuen et al. 2017 和 Bahdanau et al. 2017 三者工作中对这一问题的定义,可以发现研究者们目前还没有一个一致的看法。实际上,也许将 NMT 转换成更简单的 contextual bandit problem,又称 bandit structured prediction 更为合适 (例如,Sokolov et al. 2016, Kreutzer et al. 2017, Daumé III et al. 2018),如 HalDauméIII 在他关于结构化预测和 RL 的博客文章中所述的那样:我们可以将 NMT 问题视作是 one-state MDP 问题。
目前一致认可的一个观点是,在 NMT 问题中,我们需要考虑的是巨大并且结构化的 action space,其中的 action 是离散的,且 reward 非常的稀疏(并且经常延迟的)还有可能是 noisy 的。这就需要一个特殊的算法来针对性地解决这些问题,然而目前的 REINFORCE 和 AC 算法都不是很能胜任。并且,从头使用 RL 目标函数来 train NMT,又称冷启动 RL,目前还没有一个成功的案例(除了 Xia et al. 2016)。
RL to the rescue?
RL 能够提升 NMT 是因为其解决了标准目标函数的一些问题。
MLE 训练对于 NMT 有什么问题吗?Ranzato et al. 2016 在提出 MIXER 算法(混合 policy-gradient 和 MLE 目标函数来更新模型) 的时候,他们认为 MLE 存在以下的问题:
Exposure bias: 训练阶段 reference 被喂给模型作为输入(teacher-forcing ),然而在 inference 阶段缺少这样的输入来校正,这里存在一个 training-inference 的不匹配。
Token-level 的目标函数(又称 ”loss-evaluation" 不匹配):在标准的自回归 NMT 模型中,序列级别的 log-likelihood 被分解为 token-level 的 log-likelihood 之和。因此,训练过程旨在优化给定前面真实的的 token,最大化下一个 token 的概率。在 inference 阶段,然而,我们是在使用序列级别的 metric (例如 BLEU score)来衡量生成的结果。
像 scheduled sampling(Bengio et al. 2015 )、DAgger(Ross et al. 2011) 以及 DAD (Venkatraman et al. 2015) 等算法已经被提出来解决 exposure bias 的问题,核心的思路就是在训练过程之中逐渐让 model 适应 inference 阶段的模式(类似 imitation learning)。
将 policy gradient 加入到训练的目标函数之中(例如 MIXER 和 MRT),也能够缓解这一问题,因为 policy 的梯度更新是基于模型自身的输出。此外,使用其他一些不可微分的目标函数也能有所帮助,比如利用对抗训练 (Wu et al. 2017, Yang et al. 2017)。或者可以直接使用目标函数,来实现你希望模型做到的一些事情(不仅仅是生成和 reference 接近的翻译结果),比如让模型学会从输入中复制单词(Pham et al. 2018)。
在 domain shift 场景下,使用 RL 能够带来很大的提升,相对于未在评估域上微调的基准模型(例如,Kreutzer et al. 2017, Petrushkov et al. 2018)或与经典的目标函数结合时(例如,Wu et al. 2016, Ranzato et al. 2016)。这些论文的讨论表明,如果没有这些因素的限制,预期的提升效果将会变得微乎其微。
常见的一种范式是在 reference 可用的情况下,并能够模拟 reward 的有监督环境下,RL 被用作解决明显的 MLE 问题的第一手段。为什么不使用(或至少与之比较)其他更适合NMT的训练策略,例如 Edunov et al. 2018b, Shen et al. 2016 和 Norouzi et al. 2016 等人提出的方法,来解决上述问题呢?
Beyond Supervised Learning
在 NLP 中应用 RL 的挑战在监督学习之外。
如何更加实际地来使用 RL 方法呢?比如在一些场景下,我们无法模拟 reward,亦或是没有一个明确定义好的 reward function ,又或是无法为输出提供任意数量的 reward?在 NLP 中,这几点在以下的几种场景之中显得格外突出:
准确且标准的 label(在翻译中,就是准确的平行语料)不是随处可得的,因为其需要大量具备专业背景的人力。更加弱的信号诸如人类对于输出质量的评判可能更加易得并且需要较少的专业知识。这是 semantic parsing (Lawrence at al. 2018) 和机器翻译中经常面临的问题 (Kreutzer et al. 2018b)。
在交互式的场景下,系统能够直接和人类进行交互,那么人类的回复可以被视作是一种较弱的信号,能够用来提升系统的性能。典型的例子就是对话系统,人类的 feedback 可以被用来训练系统,例如 small-talk(Serban et al. 2017) 以及 task-oriented dialogue(Su et al. 2016)。
需要根据用户或是 domain 进行客制化的系统。用户偏好或者是评分(通常能够比较容易获得)可以用来调整系统。在工业界,大范围的收集用户反馈意见被应用在个性化新闻推荐 (Li et al. 2010) 或是电子商务推荐系统之中(Kreutzer et al. 2018a)。
在这些场景之中,之前提到的模拟方式只能够解决部分问题,并且与人类的交互又带来了新的挑战。人类因素和 RL 流行的模拟方式存在着若干的差异:首先,人类的奖赏信号并不是一个 well-defined 的函数,而是一个复杂并且不一致(主观)的型号;其次,人类不可能为无数的输出提供反馈信号。摆在我们面前的,是一系列诸如收集可靠的反馈、提升系统鲁棒性以对抗 adversarial 反馈,更公平的评估指标以及 off-policy learning 等一系列挑战(“RL is hard”)。
所以,别再问“怎么用 RL 来提升 BLEU score”了,而是考虑一下“当我们需要 reward 的时候,如何利用 RL 来学习一个”。
本文由作者授权AINLP原创发布于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。
推荐阅读
Meta-Learning:Learning to Learn and Applications
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




