让预训练模型学习知识:使用多学习器增强知识建模能力

论文标题:
K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters
论文作者:
Ruize Wang, Duyu Tang, Nan Duan, Zhongyu Wei, Xuanjing Huang, Jianshu ji, Cuihong Cao, Daxin Jiang, Ming Zhou
论文链接:
https://arxiv.org/abs/2002.01808
近年来,预训练模型取得了巨大成功,然而它们还是缺乏知识建模的能力。
为了增强预训练模型的语言知识建模能力,本文提出K-Adapter,用不同的学习器去学习不同的知识型任务,从而缓解知识遗忘的问题。
本文方法在实体分类、问答等任务上取得了显著的效果提升。
预训练模型的知识建模能力
近年来,大规模的预训练模型在NLP各类任务上大放异彩,如大家喜闻乐见的BERT及其变体。
这些预训练模型的基本思路是:将文本中的部分内容抹去,让模型通过上下文预测被抹去的部分。
这样的过程完全是无监督的,所以得以利用大规模的语料进行训练,从而增强下游各任务的效果。
注意到这个过程可以看成是一种“完形填空”的过程:从上下文推定缺省处的词。
就像我们做完形填空一样,如果模型也能非常准确地填出空白处的词,那么我们说模型就具备一定的语言知识建模能力(无论是“记住”这些知识还是“推理”这些知识)。
然而,当前有很多文献表明,单纯的预训练模型不具备这种能力。比如在我们之前的文章当下主流的预训练语言模型推理能力对比中介绍的那样,大多数模型不具备“否定推断”能力,不具备“数字推导”能力,也不具备“比较”能力等等。
增强预训练模型的语言知识建模能力,对于促进NLP模型在实际生活中的应用大有裨益。
为此,本文提出K-Adapter,在预训练模型的基础上使其更好地学习各类语言知识。
不同于之前直接在预训练模型上训练的方法(这会导致过去学习的知识的遗忘),本文把预训练模型固定,然后分别独立学习不同的知识,从而缓解“知识遗忘”的问题,增强模型的语言知识建模能力。
总的来说,本文贡献如下:
提出K-Adapter,可以持续地将语言知识融入到预训练模型中;
为不同的任务使用不同的学习器,从而缓解“知识遗忘”问题;
在分类、问答等任务上取得了显著的效果,并且具备一定的知识建模能力。
K-Adapter模型
下图是多任务学习模型(a)和K-Adapter模型(b)示意图。可以看到,多任务学习是直接在预训练的模型上训练、学习,从而,学习的先后就会导致模型参数的更新,就造成了“知识遗忘”问题。
而K-Adapter为每个任务单独配置一个Adapter(学习器),在该任务的学习只更新相关的学习器,且整个过程中预训练模型参数是固定的,这样就有利于避免“知识遗忘”问题。下面来具体看K-Adapter的结构。
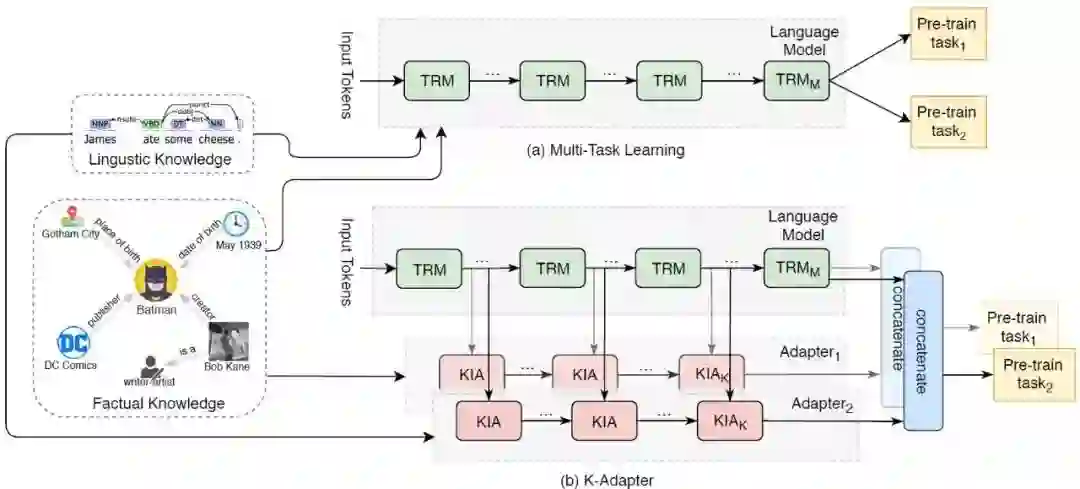
每个学习器由K个学习层组成,每个学习层由一个全连接层、N个Transformer层和最后一个全连接层组成(下图所示)。注意,这里的Transformer层是来自预训练模型中的,目的是为了融合二者。
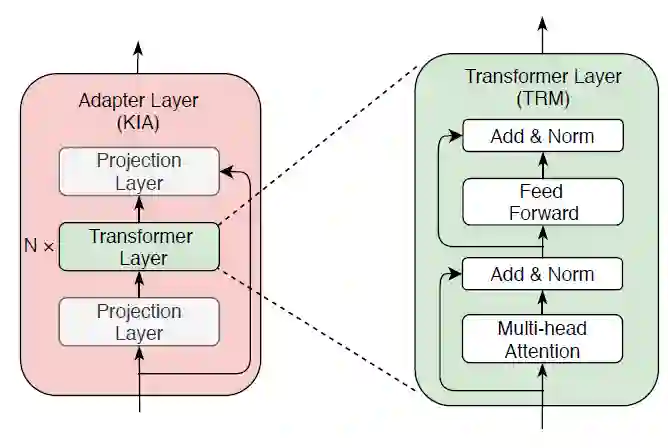
最后,只需要把学习器的最后一层的特征和预训练模型最后一层的特征拼接起来,送入下游任务训练即可。有几个任务,就用几个独立的学习器。
本文使用了两种任务,事实性任务(Factual Adapter)和语言学任务(Linguistic Adapter)。
对事实性任务,本文从关系抽取数据集T-REx中抽取出一个子集,包含50个实体对和430个关系。
对于语言学任务,本文用Book Corpus中选取1M个实例,并用Standford Parser构造依存关系数据。
K-Adapter方法简单,那么它效果如何呢?本文将RoBERTa作为预训练模型来检验K-Adapter的实际效果。
实验
实体分类
实体分类指给定实体及其上下文,要求判断实体的类型。我们在数据集Open Entity和FIGER上实验。
下表是实验结果,RoBERTa+Multitask指在RoBERTa上用多任务学习的方法学习。
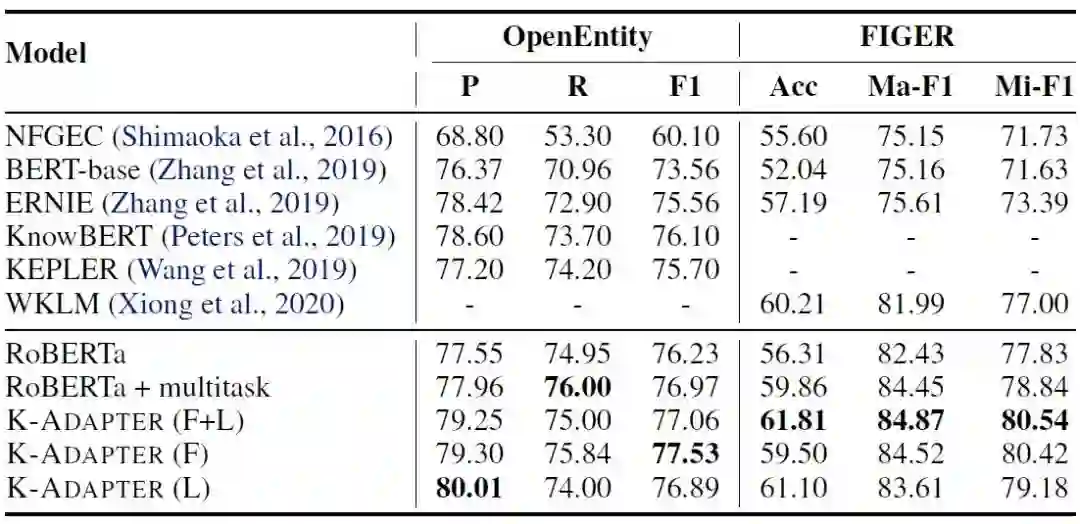
和之前的最好结果相比,K-Adapter的方法能取得显著的效果提升,而和Multitask的方法比,也有较大的涨幅。
问答
下面再在问答任务上实验。我们在常识推理问答数据集CosmosQA和开放领域问答数据集Quasar-T和SearchQA上实验。下表是实验结果:
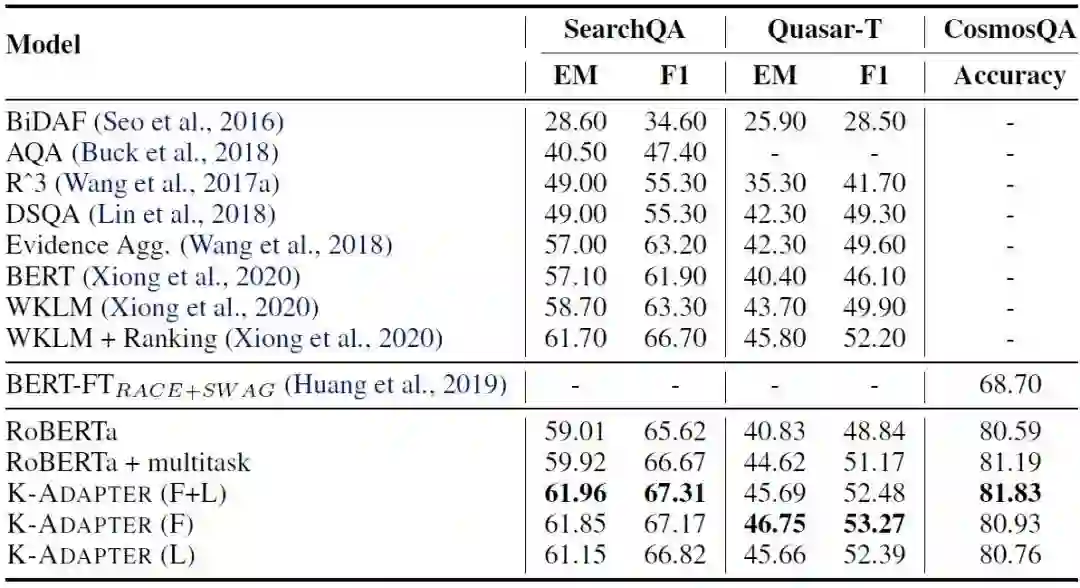
从常识推理来看,K-Adapter的最好结果是显著优于Multitask的;在开放领域问答上,K-Adapter更是好于Multitask,尤其是在数据集Quasar-T上。
知识建模能力
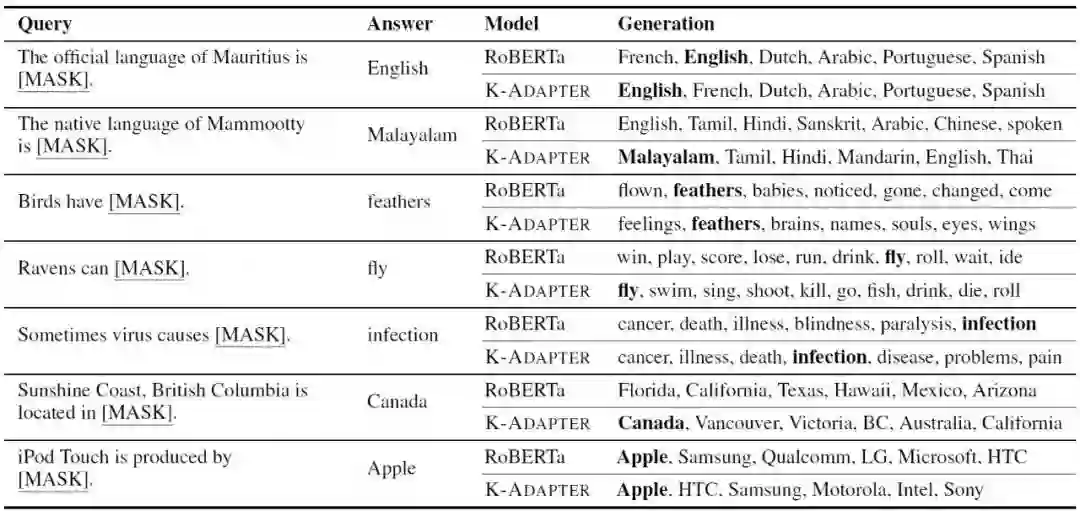
最后,我们来检验各模型的知识建模能力。这个任务类似完形填空,即要预测句子中空缺的词,比如“Simon Bowman was born in [MASK]”。
我们在数据集LAMA-Google-RE和LAMA-T-REx上实验。下表是实验结果:

可以看到,K-Adapter比RoBERTa具有一些优势,然而却弱于BERT。
这是因为,BERT使用的是字符级别的BPE编码,而RoBERTa使用的是Byte级别的BPE编码,这会导致一些词汇会被切分为若干bytes,不利于知识的学习。
最后来看看一些例子,如下图所示。从这些例子可以看到,k-Adapter可以预测得更加准确。
小结
本文提出一种方便简单的用于增强预训练模型知识建模能力的方法——K-Adapter。
在训练的时候,为不同的任务设置不同的、独立的学习器,并且固定预训练模型的参数,这样一来,不同任务的学习都可以同时融合到语言模型中。
本文在实体分类、问答等任务上取得了较为显著的效果提升,在知识建模能力任务上也有一定的进步。
正如我们在开篇讲的那样,目前预训练模型的一大不足就是知识建模能力十分欠缺,如果增强其知识建模能力、使得文本和知识完全贯通,是未来NLP发展的一大研究点所在。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





