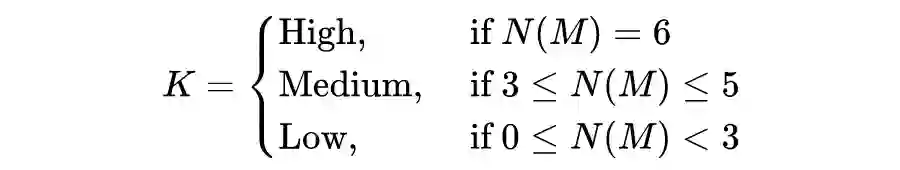©PaperWeekly 原创 · 作者|孙裕道
学校|北京邮电大学博士生
研究方向|GAN图像生成、情绪对抗样本生成
论文标题: Quantifying (Hyper) Parameter Leakage in Machine Learning
论文链接: https://arxiv.org/abs/1910.14409
AI 模型广泛应用于各种多媒体应用中,在云计算上作为一种按需查询付费的黑盒服务提供给用户。这样的黑盒模型对对手具有商业价值,所以会对专有模型进行反向工程,从而侵犯模型隐私和知识产权。对手会通过侧信道泄漏提取模型架构或超参数,在合成数据集上训练重构架构来窃取目标模型的功能。
本文提出了一种新的概率框架 AIRAVATA 来估计模型抽取攻击中的信息泄漏。该框架抓住了由于实验的不确定性提取精确的目标模型是困难的事实,同时推断模型的超参数和随机性质的训练窃取目标模型的功能。
本文使用贝叶斯网络来捕捉在基于主观概率概念的各种提取攻击下目标模型估计的不确定性。该论文提供了一个实用的工具来推断有关提取黑盒模型的可操作细节,并帮助确定最佳攻击组合,从而最大限度地从目标模型中提取(或泄漏)知识。
AIRAVATA框架
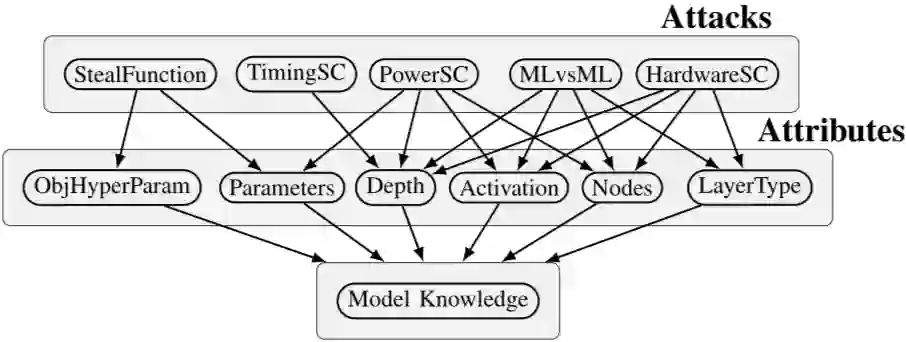
本文所提出的 AIRAVATA 框架将各种攻击和推断的模型属性表示为具有因果关系的随机变量。如果对手选择了攻击,那么攻击变量与贝叶斯网络中推断出的相应属性之间存在联系。AIRAVATA 框架的有效性分析在现实中具有一定的适用性。
下图显示了 AIRVATA 框架的细节,攻击节点位于顶层,然后是推断属性,最后是对手提取的目标知识。模型知识(最后一层)是假设变量,其值与我们的问题有关。攻击节点(顶层)是被观测到的信息变量,并影响假设变量的概率分布。信息变量通过代表推断属性的中间变量(中间层)与假设变量相连。
3.1 攻击变量
AIRAVATA 框架下的模型根据攻击需求(对手模型)和推断属性的相似性将攻击分成不同的随机变量。
“StealFunction” 节点捕获这些攻击,并能够推断学习目标中使用的超参数以及估计模型参数的值。给定大量的输入输出对
,根据已知变量求解未知变量的超定方程组,从目标函数中估计正则化超参数,而且所有的攻击在使用主动学习或对合成数据的模型进行再训练属于功能窃取范畴。
3.1.2 ML vs ML
机器学习模型可以训练成根据输入输出预测模型的属性。由于攻击使用 ML 模型,因此在正确预测模型属性时存在不确定性和误差。这些攻击被抽象到贝叶斯网络中的 MLvsML 节点中,并推断出层的数目、激活的类型、每层的参数数目和层的类型。
对于不了解目标模型的弱对手,可以通过计算网络的总执行时间来推断层数。该攻击基于在一个层中的所有节点被并行计算的思想,而所有层都是按顺序计算的,因此总的执行时间与层的数目密切相关。在该框架中,这种攻击被捕获在节点 “TimingSC” 中,并且只推断神经网络的层数。
3.1.4 HardwareSC
对硬件进行物理访问的对手可以在模型在硬件上执行期间监视内存访问模式(内存侧通道),并利用进程之间的共享资源提取进程详细信息(缓存侧通道)。
其他硬件详细信息(如硬件性能计数器、缓存未命中和数据流)显示了重要的内部模型详细信息。所有这些攻击抽象为“硬件”节点,有助于推断层数、激活类型、每层参数数和层类型。这与 “MLvsML” 相似,但是由于更强的对手模型,推断出的信息更细粒度和更准确。
3.1.5 PowerSC
在硬件上执行神经网络的过程中,一个强大的对手可以访问目标硬件的物理地址,可以监视消耗的功率来提取有关应用程序的信息。给定功耗轨迹,攻击者使用差分功率分析、相关功率分析和水平功率分析等算法推断目标黑盒模型细节。
这在框架内被建模为 “PowerSC” 节点,并在成功执行后,帮助对手推断每层中的参数数目、参数值、总层数和激活函数的类型。
神经网络有一个很大的超参数空间,每个超参数可以取不同范围的可能值。神经网络的结构细节在决定性能方面起着重要的作用。
ObjHyperParam:训练神经网络的目标函数需要学习速率和动量等多个超参数来控制参数的更新,而权值衰减则可以提高泛化能力。损失函数的选择和优化技术决定了模型的性能。
Depth:神经网络越深,性能就越高,因为 ML 社区一直致力于将神经网络扩展到大量的层。
Nodes:每层参数的个数和模型深度影响神经网络的复杂度,进而影响网络的性能。
Activation:激活函数的类型 ReLU、Sigmoid 或 Tanh 将每个节点的个中间矩阵向量计算映射到一个输出值范围。
LayerType:卷积层、maxpool 层或全连通层在决定计算复杂度和性能方面起着重要作用。
3.3 提取模型知识
对于不同的攻击,所提出的模型需要捕获的知识提取程度不同。模型属性为
,其中
,攻击变量为
,其中
。目的是推断假设随机变量,即知识提取度 K。最终的知识估计
是给定了了攻击的手段
情况下,假设随机变量
的概率。
在选择不同的攻击变量时,根据影响或关联的属性数
将最终提取的知识分为三类。
这些是在推断目标模型的不同属性时,根据搜索空间范围而选择的主观阈值。攻击变量反过来影响中间信息变量(模型属性)的概率分布,影响“模型知识”的最终概率分布。
通过变量消去法进行推理后估计出的假设变量的合成概率,来评估不同的攻击组合,可以利用所获得的知识来概率推断模型信息泄漏。
实验结果
4.1 Adversary 1
假设贝叶斯网络模型捕捉了随机变量之间的联合概率分布,根据提取到的知识的可信度,对模型进行查询,以判断不同攻击的有效性。在对手 1 的情况下,假设对手很弱,并且只能对目标模型的远程 API 访问。
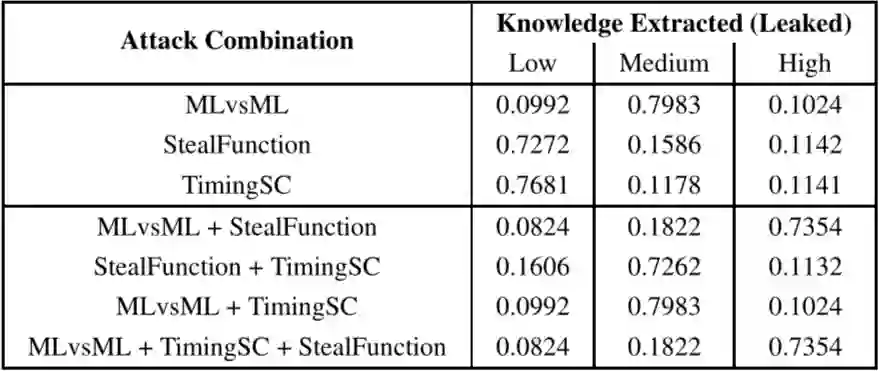
对手可以向目标模型发送查询(输入图像)并得到相应的输出预测。对手只能依靠远程执行攻击,包括:TimingSC、MLvsML 和 StealFunction 攻击,这些攻击可以根据各自的威胁模型进行远程部署。
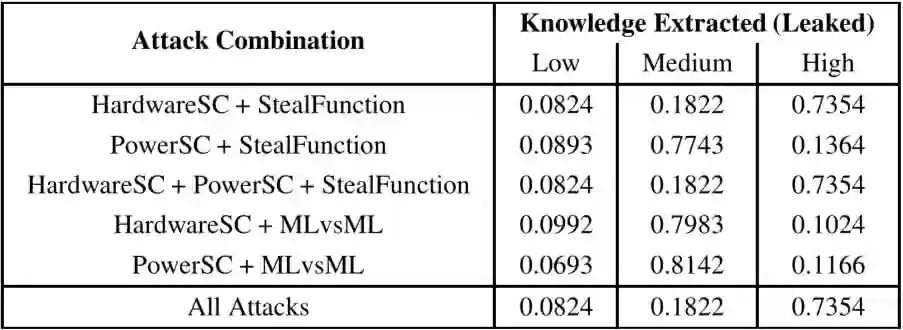
对应于对手 1 的远程黑盒设置提取的知识概率如上表所示,与 MLvsML 相比,TimingSC 和 tealFunction 攻击所推断的属性更少,相应的提取“低”知识的置信度分别为 0.7681 和 0.7272。而对于像 MLvsML 这样的强黑盒攻击,所提取的知识被归类为“中等”,其信念得分为 0.7983。
StealFunction 攻击通常是在推断目标模型属性以获得近似体系结构之后执行的。对于第 2 行(表 1)中的单个攻击的具体情况,考虑的是由对手选择的随机架构。
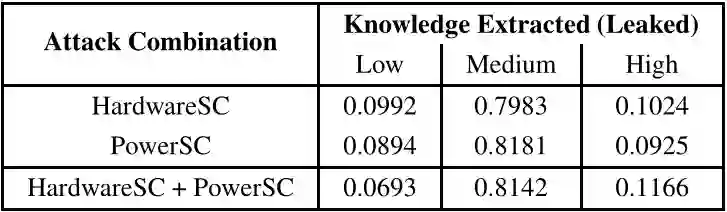
在对手 2 中假设一个更强的对手可以物理访问执行神经网络的硬件。然而,对手没有 API 访问权限来查询模型,因此可以分析基于边信道的超参数推断攻击。对手可以通过监视硬件在执行神经网络期间消耗的功率来执行基于硬件的侧信道攻击,例如缓存侧信道、存储器访问模式和功率侧信道。
与独立执行攻击相比,使用 HardwareSC 和 PowerSC 相结合的信念改善并不显著。从这一点可以推断,这两种攻击在从目标模型中提取知识方面同样强大。
然而,结合这两种攻击,会发现对“高”知识的总体信念从 0.1024 增加到 0.1166。与 HardwareSC 和 MLvsML 攻击相比,PowerSC 对于“中等”知识提取(0.8181 到 0.7983)有更高的信念。
4.3 Adversary 3
第三个设置是 AIRAVATA 框架的一部分,对手有物理访问硬件和远程 API 查询模型。这个假设的设置允许将来自上述两个设置的攻击结合起来,以估计提取目标模型知识的总体信念。
如上表所示,将不同的攻击组合在一起,对目标模型提取“高”知识的最大置信度为 0.7354。通过选择其他攻击的仔细组合,可以推断出相同的知识水平。
[1] M. S. Alvim, K. Chatzikokolakis, C. Palamidessi, and G. Smith, “Measuring information leakage using generalized gain functions,” in 2012 IEEE 25th Computer Security Foundations Symposium, June 2012, pp.265–279.
[2] X. An, D. Jutla, and N. Cercone, “Privacy intrusion detection using dynamic bayesian networks,” in Proceedings of the 8th International Conference on Electronic Commerce.
[3] E. T. Axelrad, P . J. Sticha, O. Brdiczka, and J. Shen, “A bayesian network model for predicting insider threats,” in 2013 IEEE Security and Privacy Workshops, May 2013, pp. 82–89.
[4] L. Batina, S. Bhasin, D. Jap, and S. Picek, “Csi neural network: Using side-channels to recover your artificial neural network information,” Cryptology ePrint Archive, Report 2018/477, 2018, https://eprint.iacr.org/2018/477.
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。