香港科技大学教授冯雁:How to Build Empathetic Machines
主讲人:冯雁 | 香港科技大学
屈鑫 整理编辑
量子位 出品 | 公众号 QbitAI
本文为冯雁教授8月18日于北京创新工场的分享实录整理,分享主题为《How to Build Empathetic Machines》。
冯雁现为香港科技大学电子及计算机工程系教授,主要研究领域包括语音理解、机器翻译、多语种处理及音乐信息检索等。
冯雁教授1988年于英国伍斯特理工学院获得电机工程学士学位,1993及1997年于美国哥伦比亚大学分别取得电脑科学硕士及博士学位。
2015年,因人机互动领域所作出的突出贡献而获颁IEEE院士荣誉,曾经担任IEEE Transactions on Audio、Speech and Language Processing、IEEE Signal Processing Letter、ACM Transactions on Speech and Language Processing,以及Transactions on Association for Computational Linguistics等国际期刊的副主编,同时也是ACL SIGDAT的主席及董事会成员。

△ 冯雁教授
大家下午好,非常感谢李开复博士的邀请。今天我的分享主题是:How to Build Empathetic Machines,如何让机器人更有同理心。

为什么会提到这个主题呢?因为现在在人工智能方面,大家会看到很多商机,但是除了商机以外,我们还需要看见未来,比如5年后10年甚至20年后人工智能会发展成怎样。
所以现在有几个大的问题,我们自己需要反省:
人工智能是不是只是一个单纯的工程的东西。人工智能跟别的机器是不一样的,它里面很重要的一点是“人”,所谓“人工智能”里面的“人”。
如果做一个技术是来为人类服务的,那么这个技术是不是需要有“同理心”,即它是不是需要有情商,不能只有智商。
这个机器,有没有正确的价值观。前两年微软上线了一个Chatbot,上线之后不久被下线了,就是因为讲了一些不适当的话。这只是一个Chatbot,那如果是在做客户服务的时候,这个系统就需要很明确该说什么话不该说什么话。
机器所服务的对象是人,而人是各种各样的,有不同的性格和不同的情绪,那这个机器能不能帮助我们,检测到我们心理的问题。
另外还有两个问题稍后会说到:人工智能能不能有幽默感和审美感。

首先我想让大家觉得情感很重要,不是只是好玩而已。用信号处理的方法,改变声音的情感色彩,这样听见的声音的意义就会不一样。
下面讲一讲什么叫“同理心”,英文叫做“empathy”:The action of understanding, being aware of, being sensitive to, and experiencing the feelings, thoughts, and experience of another. 意思就是说我能感同身受旁边人的想法和感觉。
那么这个empathic communication就是有同理心地沟通,这是在人和人沟通中很重要的一部分。平常可能不会有太大的感觉,但是当你跟电脑沟通的时候,没有“同理心”,就会产生沟通的障碍。
我们说的自然语言理解,在AI里是一个很大的领域,我们现在提出的“Natural Language Empathy ”,就是在自然语言理解里加入了情感、意向的识别,还有它的回答。
那这个跟创业有什么关系呢?跟目前所能看到的人工智能市场有哪些关系呢?

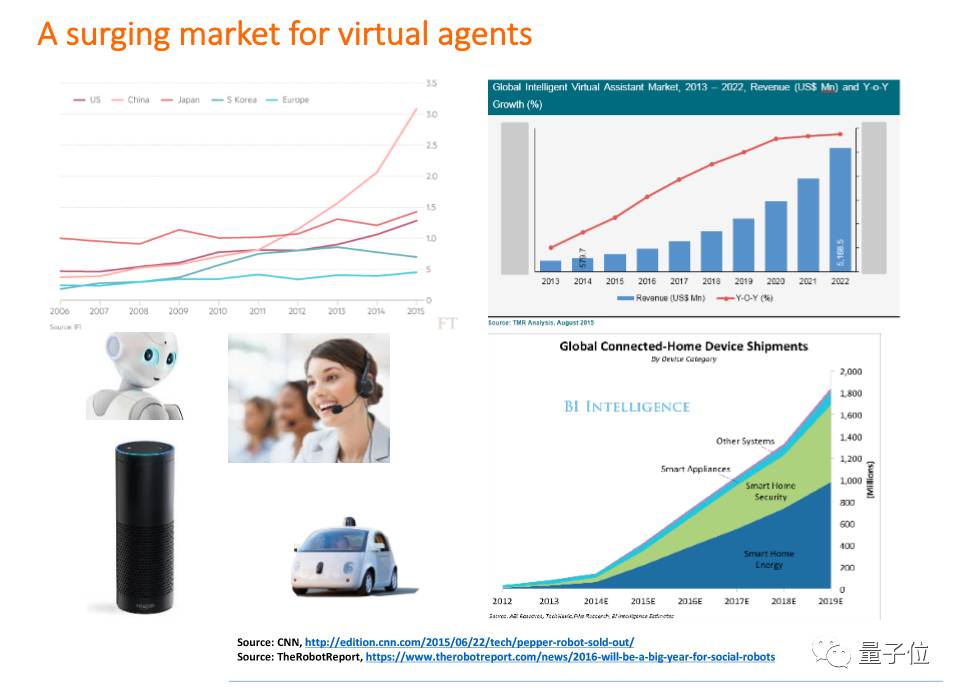
首先讲一讲virtual agent:虚拟助手,它的市场。
我们现在可以看到有很多需要虚拟助手的场景,比如机器人客服。从现在到未来的十五年,我们可以看到家庭机器人、服务机器人这些市场的重心都会移到中国、亚洲,而不是在欧美。所以机器人如果是来帮助人,为人做服务,非常需要一个软件来理解人的需求。现在的客户服务这些工作,可以用机器来代替,但这个机器需要明白人需要什么。比如无人驾驶,车本身就成为了人的助手,需要人来告诉它我们的需求;另外就是智能家居,现在的发展方向就是人机交互。
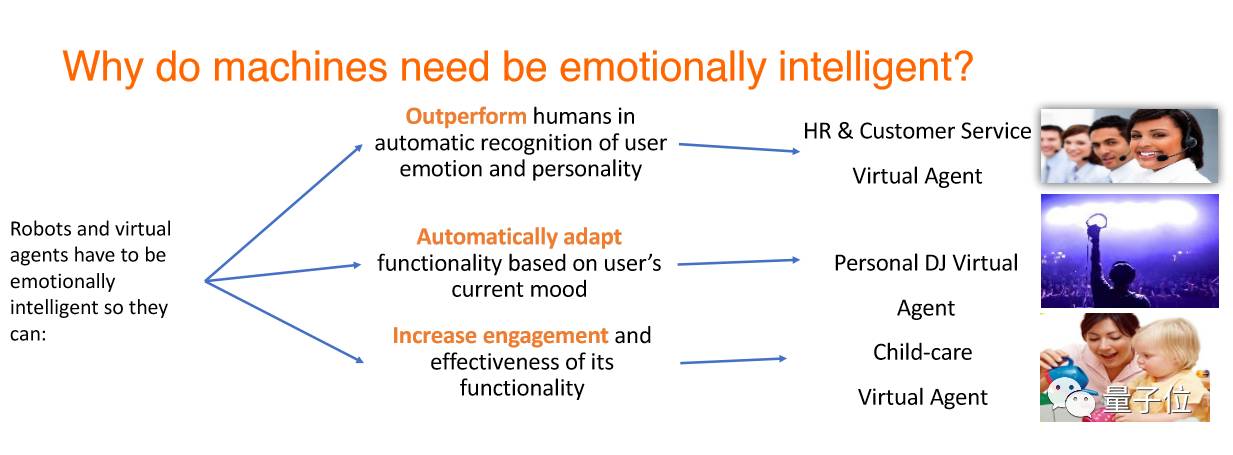
为什么机器需要情商呢?因为机器有三个很大的优势:
机器有了情商之后,可以比人工作得更好,更精准地识别人的情绪,因为现在的数据集是能够让机器来学习,在某个领域比人更厉害。
机器可以快速自动适应用户现在的情绪,能够准确理解当前状况下人的情绪。
使用户的粘合性增加。增加用户的粘合性不只是需要精确度,现在精确度已经能够做到很高,但语音识别之后,我们需要机器来理解我们意图,明白我们在说什么。
那如何让人机交互更加有同理心呢?其实在做研究的时候就发现有几点很重要:
大部分人不会频繁使用类似Siri这种无实体的手机助手,因为没有具体的形象会让人觉得跟它没有实质性的关联,所以一个系统需要有一个具体的形象。在对话中我们希望对方有具体形象,说话有趣,能够理解我的表情,我的语气,明白我的意向,而所有的这些都要求机器有实时的反应。
现在的研究是可以做到实时的,也是现在的一个方向:做有同理心的理解。

另外一点就是,在很多研究里发现:人类喜欢人形象的机器人。所以我们实验室设计了一个具象的机器人——Zara。Zara跟siri的原理和功能都差不多,不同点在于我们是Task-Oriented Dialog System。
对话系统分两种:Chatbot和Task-Oriented Dialog System。Chatbot比如小冰,目标是能够循环对话。Task-Oriented Dialog是指需要完成一个任务,比如帮你做投资,帮你订票或者订餐厅。
Task-Oriented Dialog里面是分前端处理、语音识别、对话服务(自然语言处理、对话管理、自然语言的生成),最后是语音合成,这是一个传统的做法。现在提出的是在中间加一个同理心的模块,那这个模块就会识别人的情感、性格,甚至识别人的心理问题。

下面讲一下语音和语言怎么去做情感识别。
第一部分是怎样在音频和语音上直接抓取情感的讯息。

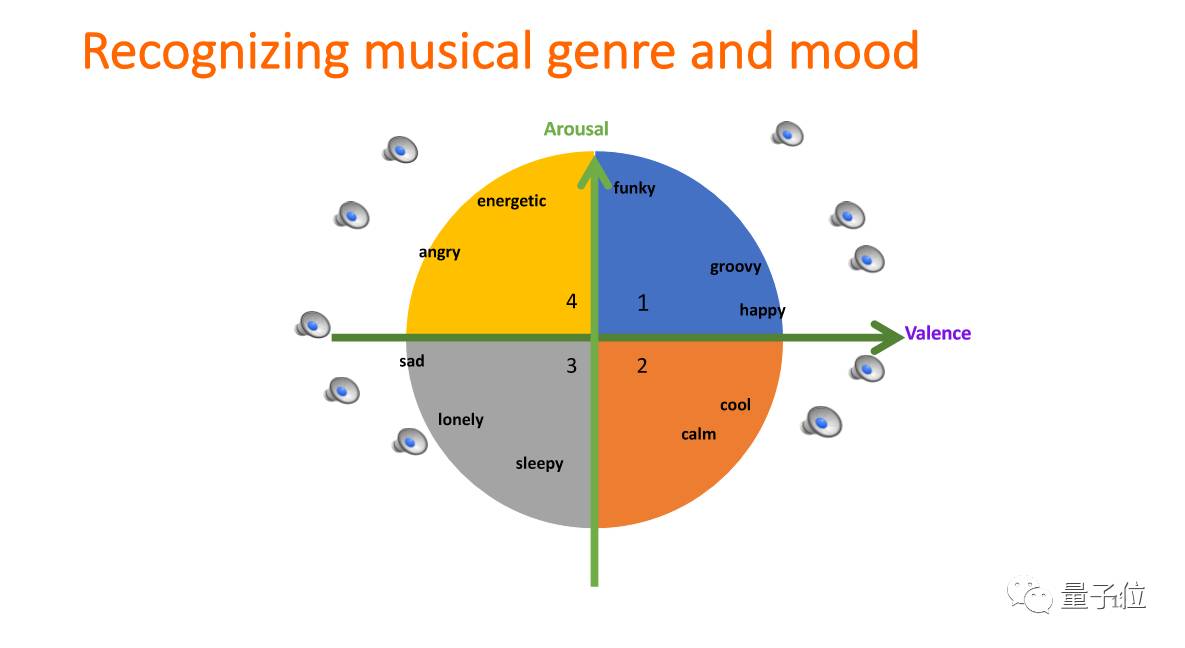
首先想说一下对音乐的分析。之所以做音乐,是因为音乐本身就是表达情感的。下图的横轴是valence,表示人的高兴程度;竖轴arousal表示人的激动程度。音乐和人的情感是同一个plan。所以我们在做音乐分析的时候,想看能不能用机器学习的方法,直接把音乐的风格区分开。
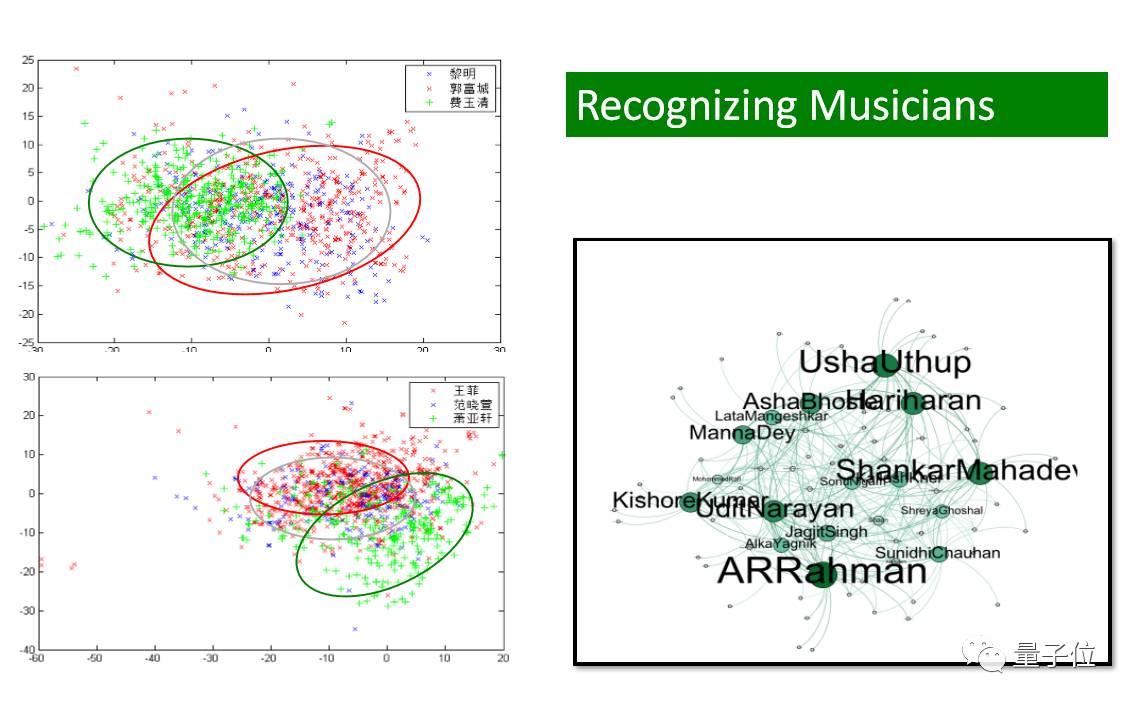
我们几年前的方法是直接做特征提取,提取了1000-2000的特征,每一首音乐都由特征来代表。有特征的好处就是:可视化。
比如我们能看到三个歌手,把他们所有的歌曲放到一个二维度,我们就能直观地看见红色的歌手和蓝色的歌手曲风比较接近。右边也是一个方法,寻找的是宝莱坞的音乐家之间的互相影响关系。这对音乐推荐来说是一个很重要的事情。

那这其中有个问题就是,特征提取非常慢。如果要识别人的情感的话,需要实时,而特征提取是无法实现实时的。后来就出现了deep learning。
Deep learning的好处就是机器自动提取。那我们后来就把音乐做成一个样本以后,不做任何处理,直接放进去,看它能不能自己提取特征。
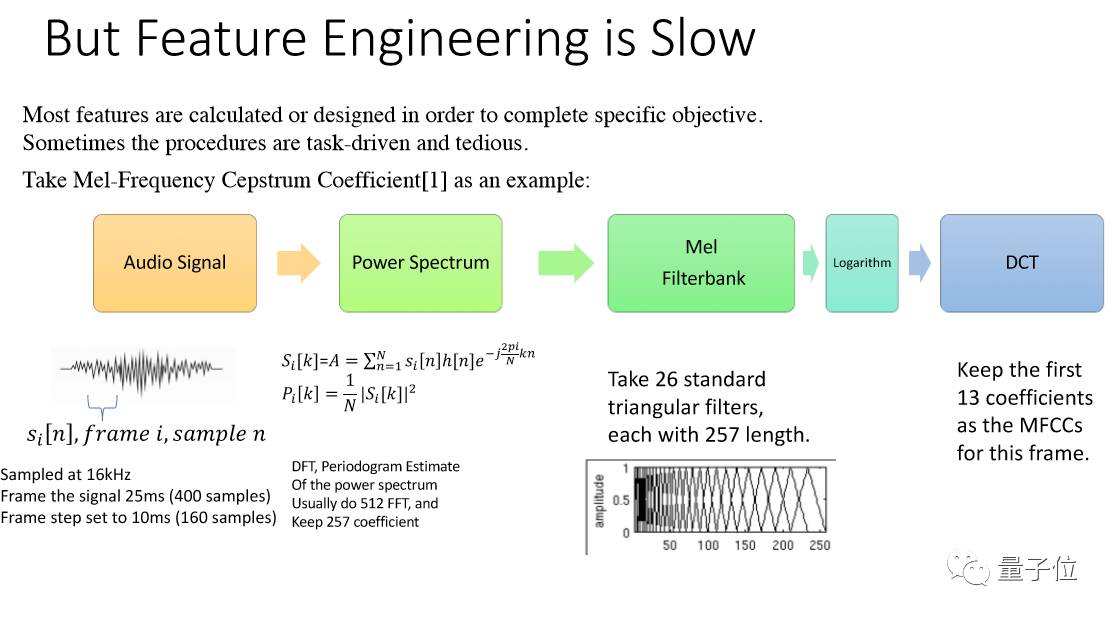

后来发现这种方法是可行的。最重要的是,机器非常快,是以前6倍的速度,这样就能实现实时了。这就发现在音频的情感识别上用DNN的方法是可以做到实时的。
可以看看它的效果,这是在2016年,它的效果和传统的SVM差不多,而SVM是需要提取1000-2000个特征。下图是音乐曲风的识别。

下图是音乐情感的识别。我们是用几千首专家标识过的音乐来训练CNN,发现它速度和结果都很好。也就是说现在不用打标签,直接就能识别音乐的曲风和情绪。
另外一个就是人说话的时候的情绪,那么这个是怎么识别的呢?
我们刚才说的用CNN来识别音乐的算法,就直接把它应用到人的情绪识别上。然后发现CNN比原来的特征提取更好,速度更快结果更佳。主要是识别人的主要情绪,高兴、伤感、生气、平静这些主要情绪,后面还有十几个second emotion,包括幽默、看不起人等等。
这些比较难,但是用CNN的好处就是数据多了,后来会越来越准。在这一点上机器是可以超过人的,因为人来做的话,每个人的同理心不一样,标准就会不一样。
在识别十几个second emotion的过程会发现比原来用SVM做的要好,但有的情绪容易识别有的不容易,整个平均是60%,所以在这方面还有很多工作要做:需要更多的大数据;算法需要优化。
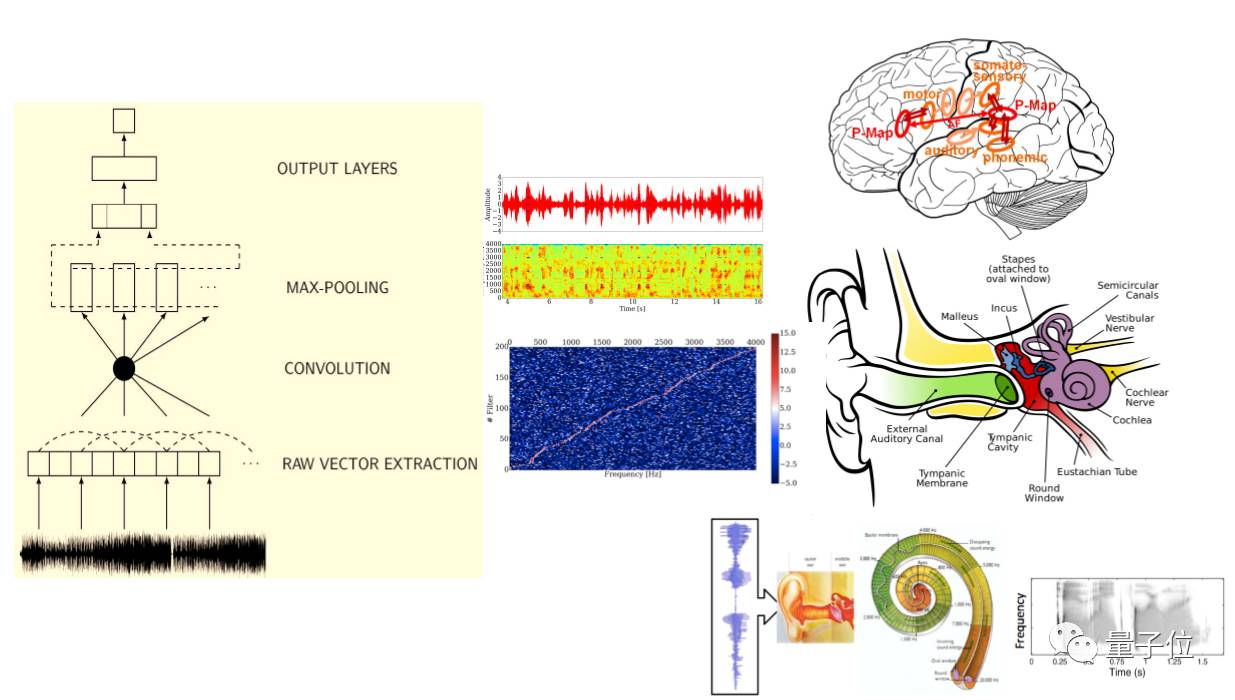
然后是CNN的结构。CNN的第一层是在做信号处理,在高层后会越来越抽象。

CNN的每个level跟我们的耳朵的听觉系统是有关系的。
我们看的更深刻一点是:就是没有做过信号处理的音频需要看什么。还有个问题是:情感识别是不是用英文训练的情感识别系统也能识别中文的情感。那么我们就需要知道的是整个CNN,它的每一个层次到底在处理什么。
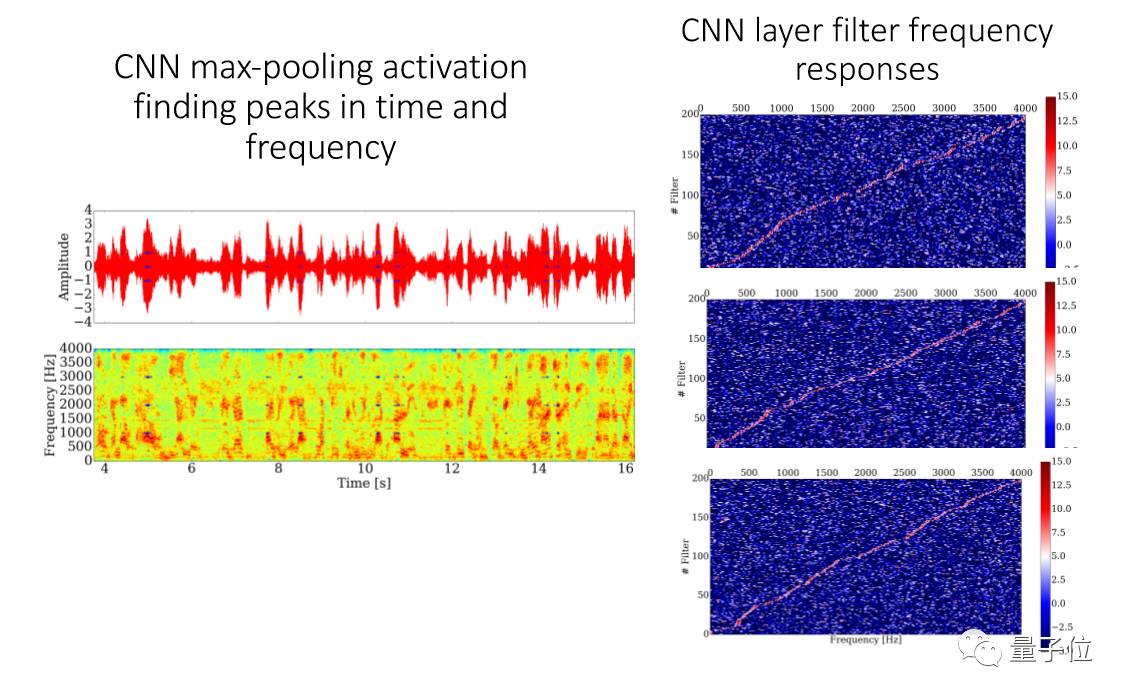
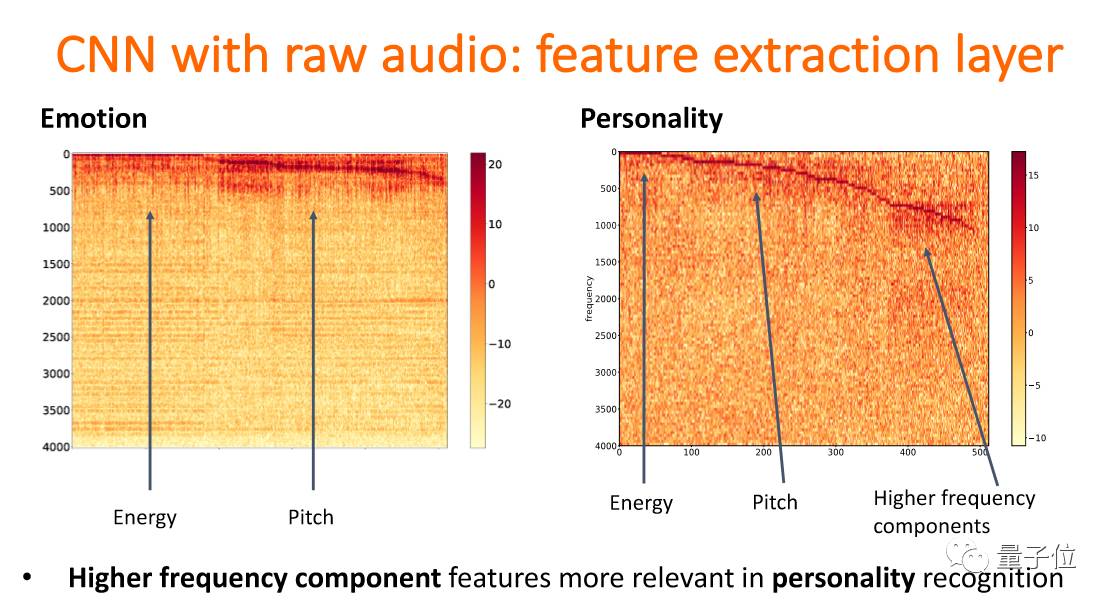
这是一个层次,emotion和personality。从低频到高频,发现在第一层开始的时候是在抽取energy、pitch、frequency等信息。

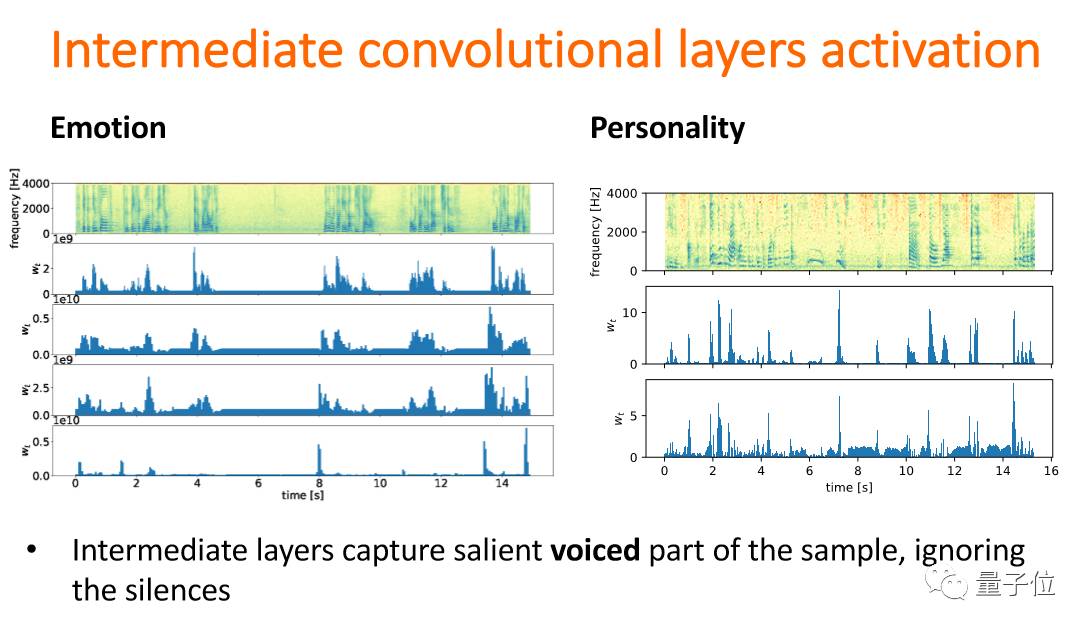
往后就有不同的activation,它能分辨哪里有声音,哪些声音比较激昂。
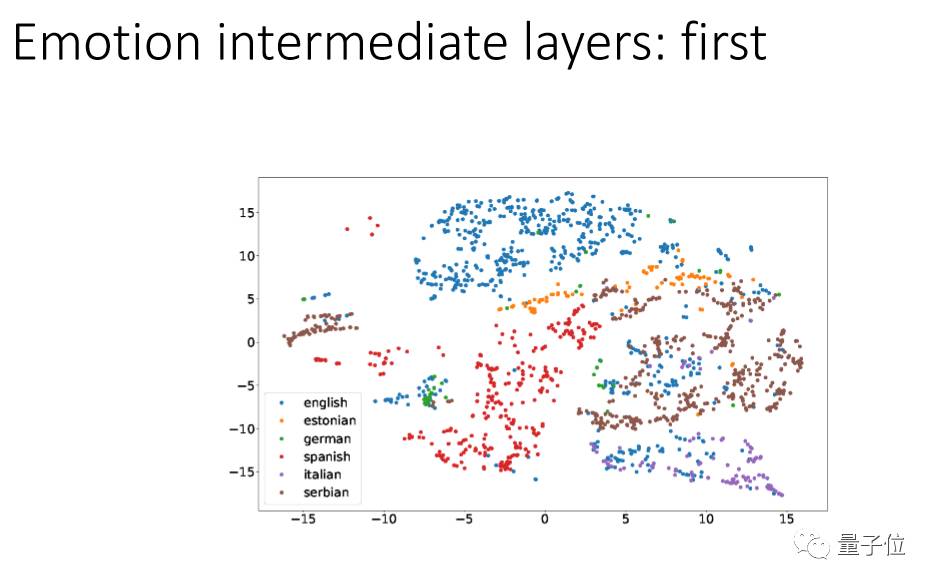
我们用一个方法叫:t-SNE,把它的每个层次的点投射出来看,把不同的语言用不同的颜色来代表。

我们可以看到第一层里面经过信号处理后每个语言还是混杂在一起的,CNN越往上,每个语言就越能分离出来,到最后基本上就完全分开。现在的deep learning,最低的是language dependent,越往上越是有language information,这跟我们人的特点很像。
这是我们的data base。
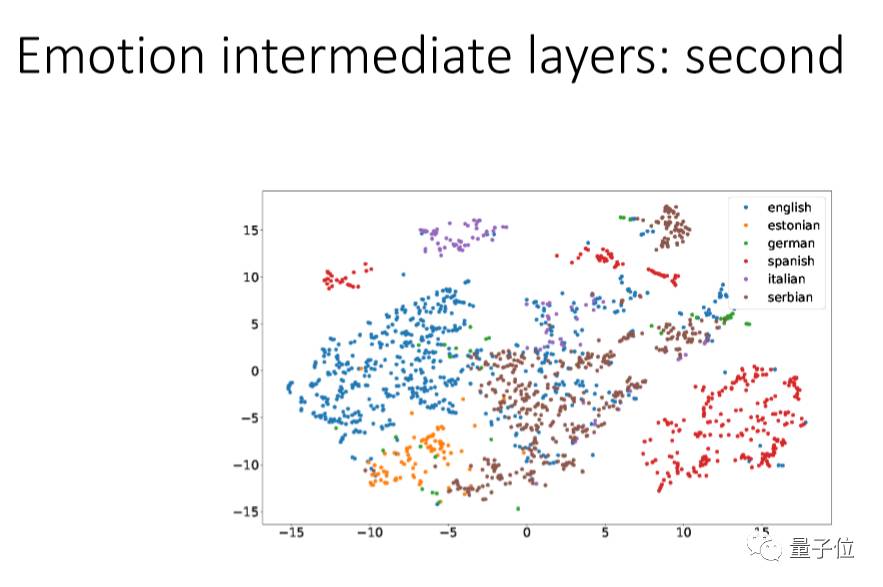
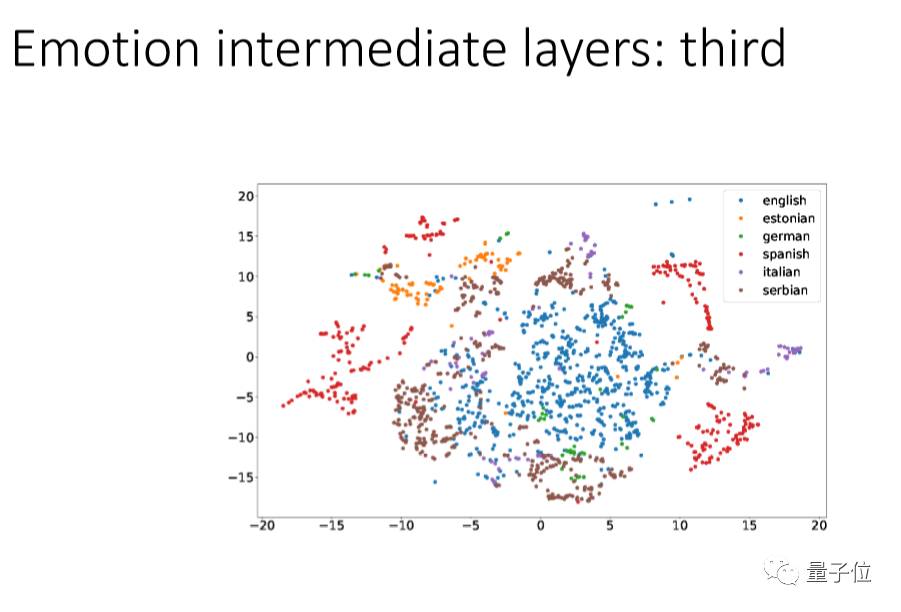
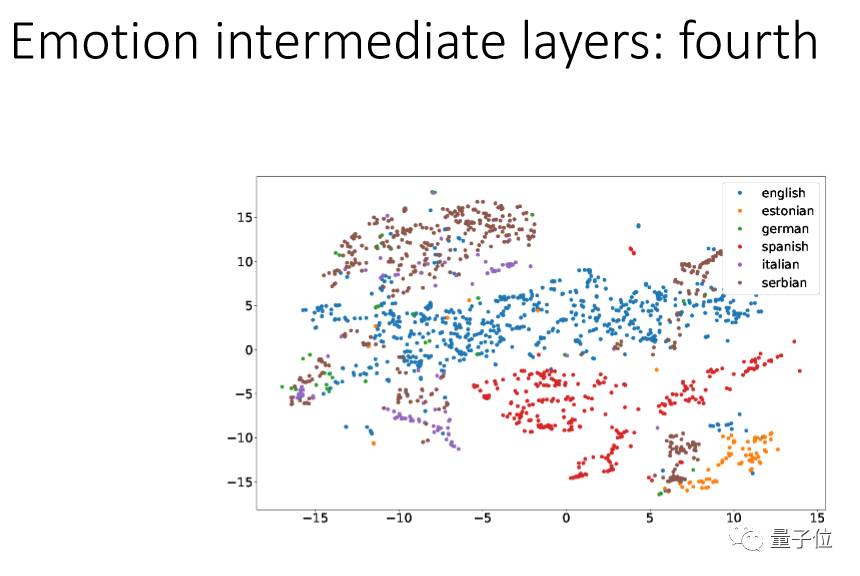
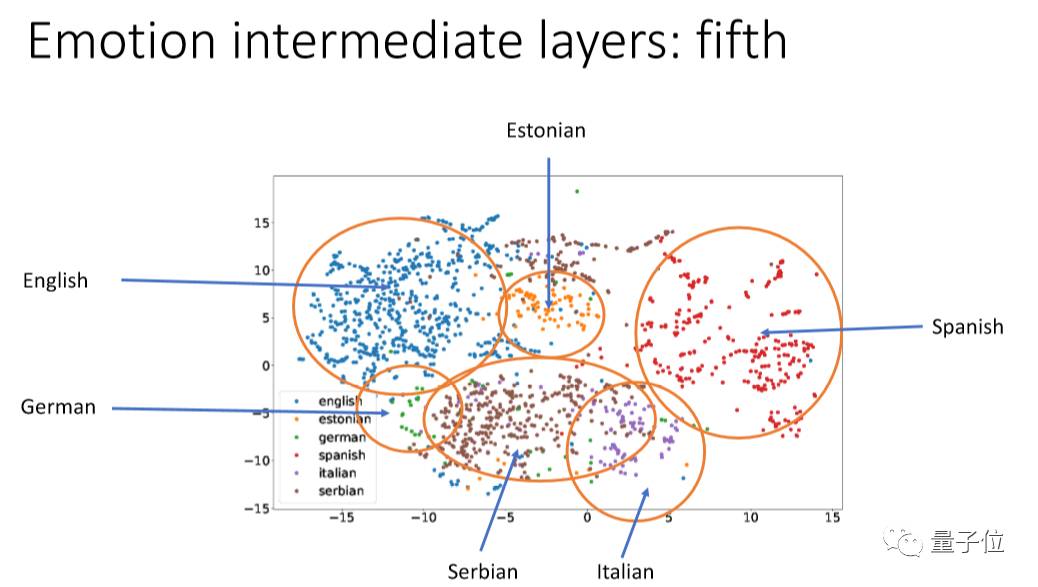

这个结果想告诉大家:在情感识别上,第一层如果用很多种语言来训练它,这种方式是好的,越到上层语言会分离。
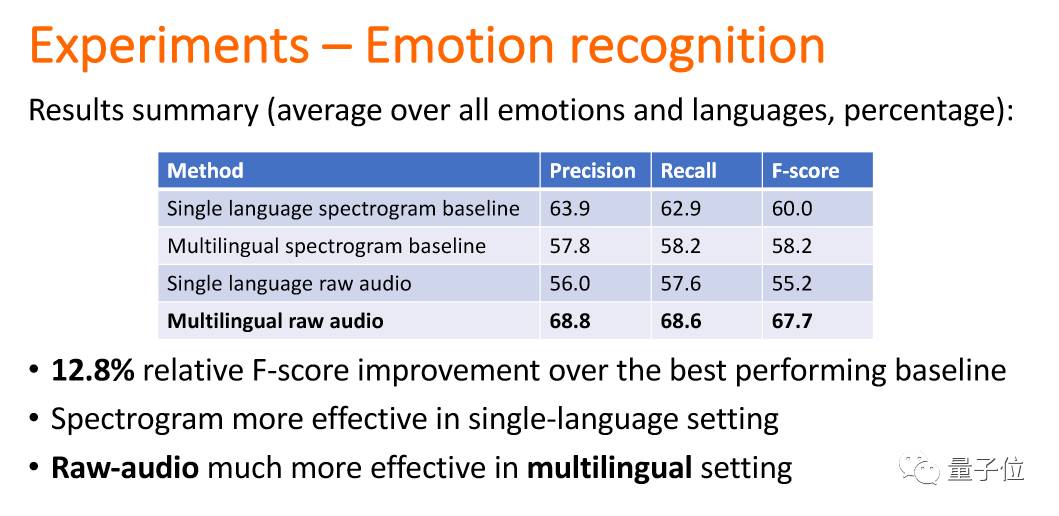
后来我们做了一个实验。机器人这样去识别人的性格。
人和人沟通的时候会有意无意地去迎合他人的性格,这是人在沟通里合作的形式。机器的性格识别里也可以用CNN,从面部表情,语音直接去识别。比如识别是不是外向的,是不是好相处的等等。
也是可以使用多种语言放在一起这种训练方法的。

以人来举例就是在国内生活的时候能够通过语言去识别性格,到了国外之后,通过一段时间的适应,因为有在国内的基础所以很快也能通过语言去识别性格。
有基本的情感识别的能力,往上就越来越不受语言限制。
我们刚刚说的是音频和语音方面的情感识别。后面说一下跟自然语言和文本有关的情感识别。
文本里的情感,比如说大众点评,从他的评价描述里面判断出他给这家店打几星,这叫做文本里的情感识别。
用户在跟机器人沟通的时候,面对不该说的话机器人该如何应对。
自然语言理解里的更大的话题:需要融入emotion和sentiments。

这是从Twitter上来看人的情绪,我们基本上也是用CNN和Word embedding。
Word embedding的好处是数据可以直接拿来用,在自己的数据不够的时候很好用。
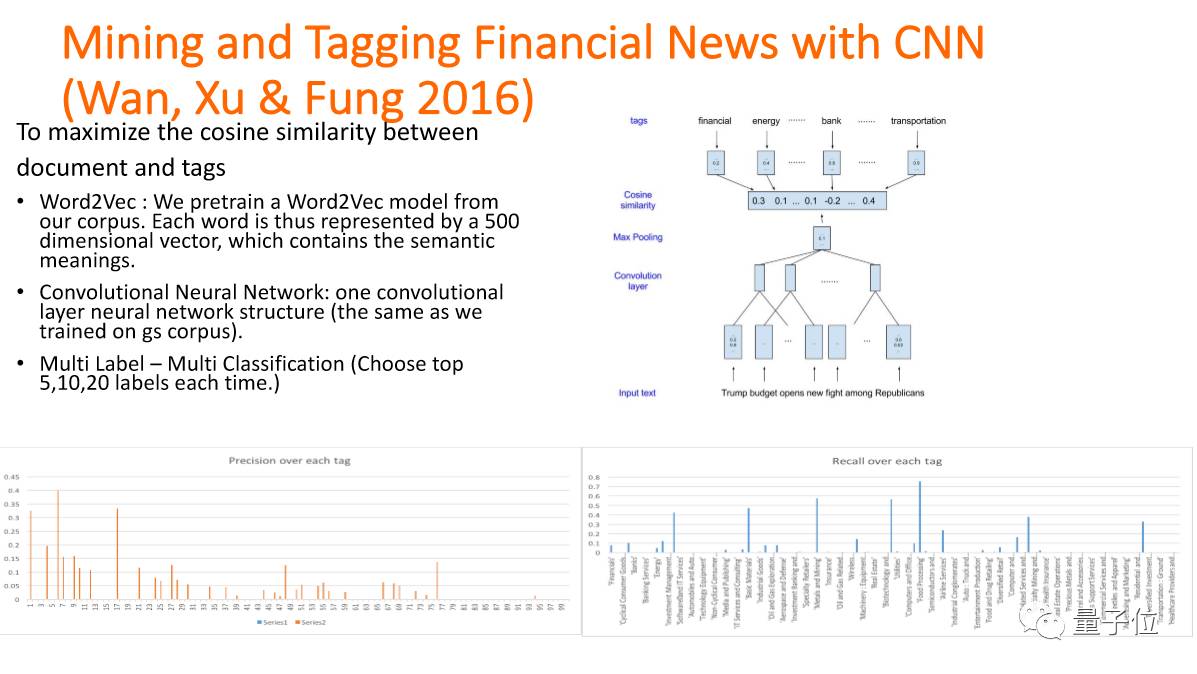
这个是我们做的一个课题:怎样在一篇新闻报道里提取标题。
新闻的标题是summarization里比较简单的一个工作,但是后来发现报纸的标题和网上的标题不一样,机器做出来的标题是实实在在的内容总结,而现在很多需要的是有点击率的标题,而这种标题就是带有情感的。
我们怎么样去让机器自动生成有点击率的标题呢?在原来的标题抽取结构上面再加上emotional embedding,这样出来的标题就能比较吸引人。
这是我们第一次发现在自然语言处理领域需要用上情感识别,才能产出我们更能接受的标题。

我们要从财经新闻上看出市场的走势,以前一些欧洲的专家们做过研究,如果按照财经新闻来研究,可以预知到12天以后的走势。这个其实就是大数据,而我们挖掘的是情感。
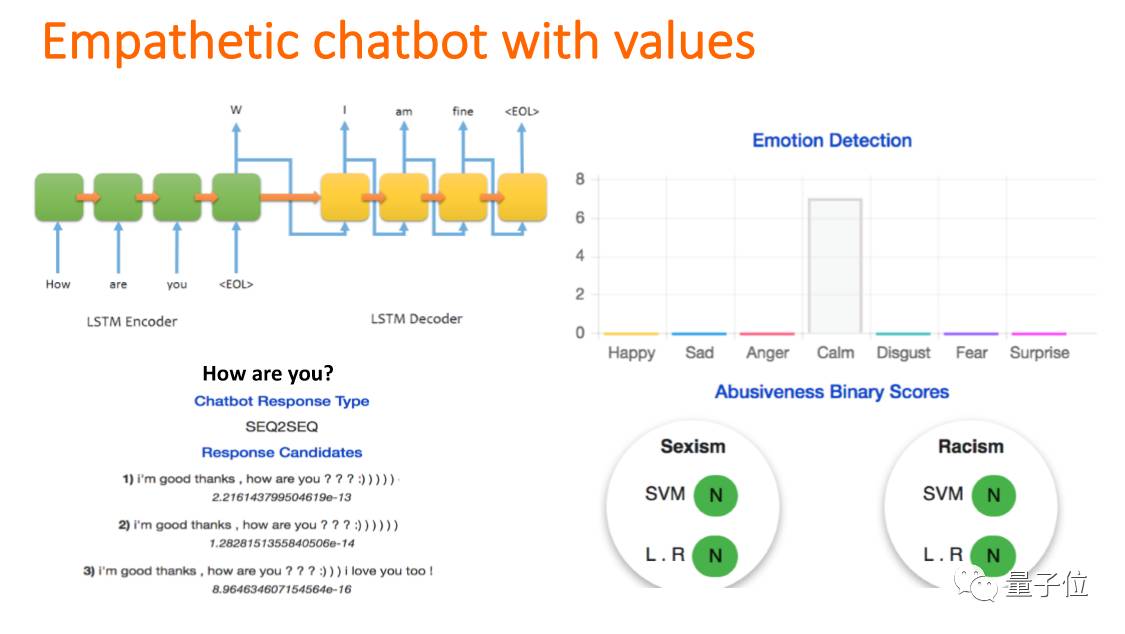
人和机器人是如何打交道的,研究发现有20%-25%的人会说一些不该说的话,也就是abusive language,那么机器人该如何应对。这也是可以用CNN去学的,我们可以用一个step:这个话是abusive还是sexist还是racist等等,或者用两个steps:先知道这个话该不该说,再知道这个话是属于哪一类。
我们可以在Chatbot里加一个values,有两个工作:如何让Chatbot记住更前面的会话内容;如何回答。训练的时候就要把emotion加在里面。

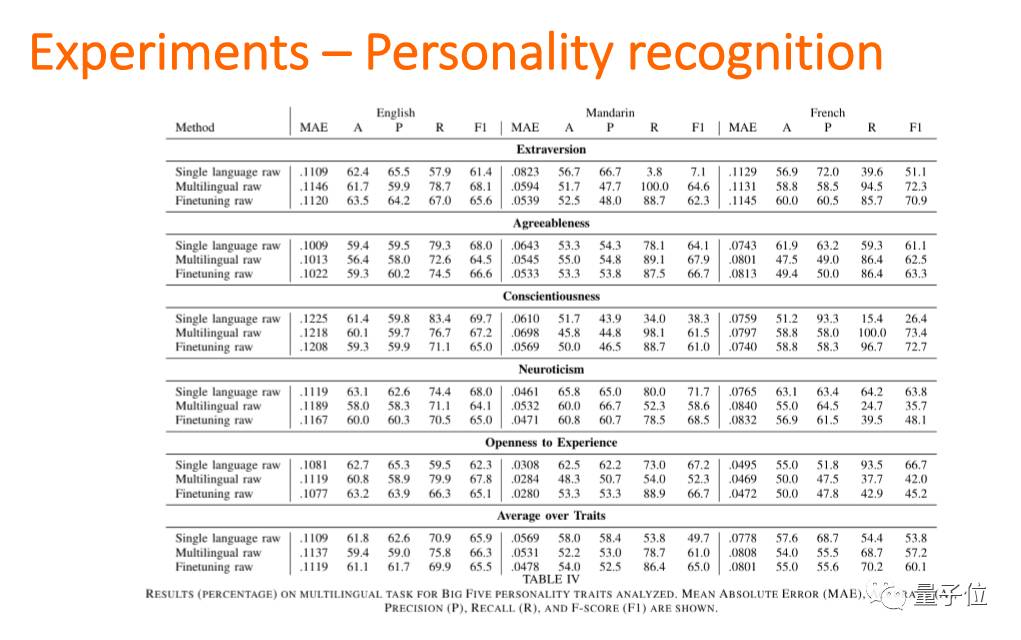
这是性格分析。我们在和人机沟通的时候,如果机器知道我们的性格,它就能用我们喜欢的方式来跟我们说话。那我们怎么去过性格识别呢?性格识别也是用CNN的方法。
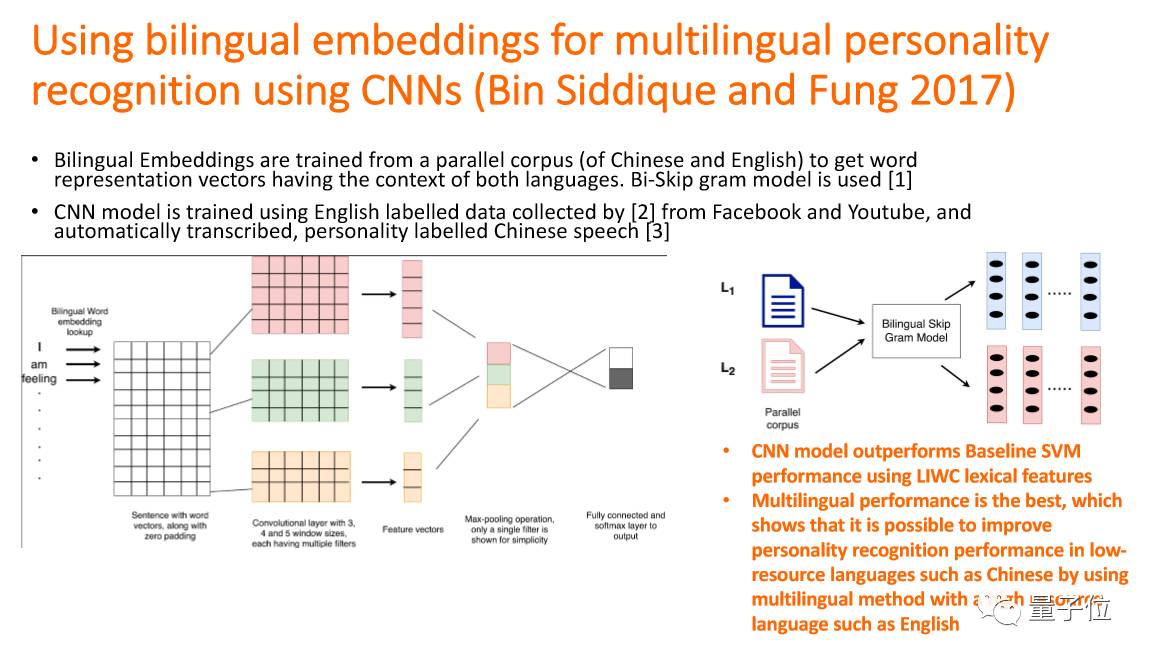
我们能不能用同一个系统去识别?说不同种语言的人他们的性格,直觉上好像不太一样,但是实验之后我们提出一个方法:bilingual word embedding,不论哪种语言,能够识别出一样的意思,那我们就发现可以有一个系统能够通过不同种的语言去分析性格。
然后这个是心理相关,分辨出人的心理问题。从email、Facebook等一些文本,还有通过聊天的过程来辨别这样的问题。结果就是:需要明白语言的意思,和这段音频的状态。这两点比听懂说什么更加重要。
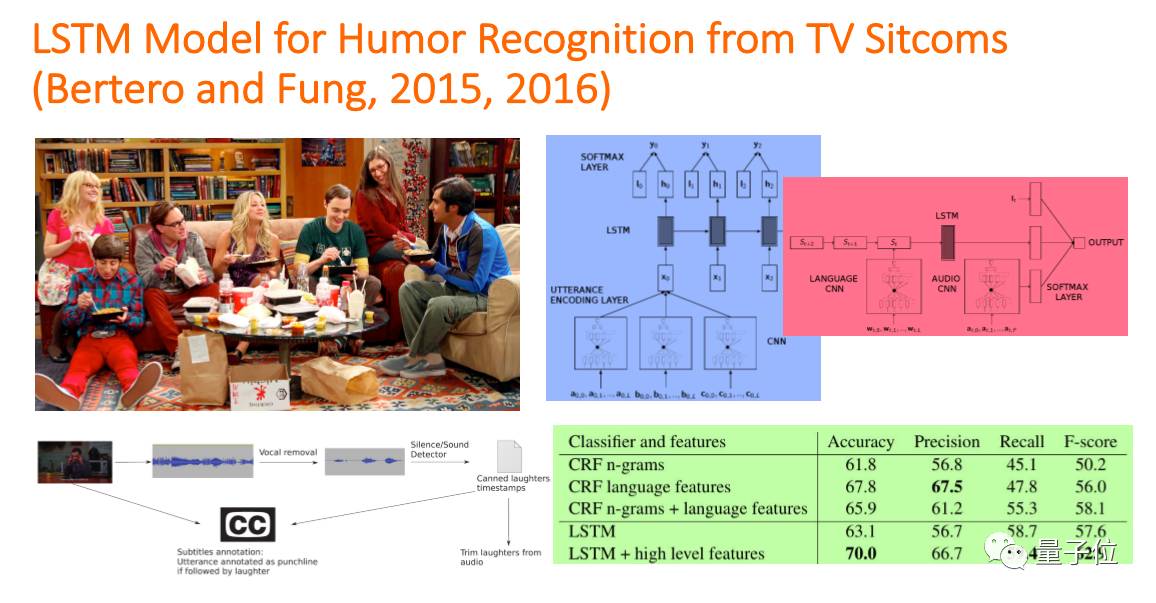
这是The Big Bang Theory,The Big Bang Theory里有一个人叫Sheldon,我们实验室有个学生做了一个Chatbot叫Sheldonbot,因为有时候识别不了笑点,所以叫Sheldonbot。他的研究主题是:怎样让机器幽默感。有幽默感有两步:第一步是在笑点上我会笑,这叫能不能识别幽默感;第二步能不能制造幽默感。

他怎么来实现的呢?也是分两步:第一步是识别,让机器来明白笑点,训练数据来源就是美剧的喜剧,因为所有的美剧中的喜剧在笑点出现都会哄堂大笑,那么大笑前这句话就具有对话中的幽默感;
第二步,humor generation,就是让机器能够抛出笑点。跟我们刚刚说的Chatbot相似,但又有一点不一样的是,它的目的是让人笑。在里面除了用sequence2sequence learning model,也加上了reinforcement learning,就是在训练的过程中在有人笑的地方加强学习。在这个领域来讲,这还是刚刚开始的工作。
总结来讲,在机器人对话过程中需要加入一个empathy analysis,无论是客户服务还是Chatbot。还有一点就是我们在做empathy analysis的时候也可以加上脸部表情识别,还有其他研究会加上肢体语言,这都是情感的一种表达。

还有一个就是我们的方法,我们组从两年前做machine learning全都用DNN,第一是因为速度快;第二是因为统一用DNN更加容易,情感、表情等等能够表达情绪的识别一起学习,形成一个系统的能够识别所有的情绪表达,在这个方面DNN是个很好的平台。
今天我的分享就到这里,谢谢大家。
(在后台回复关键词“170818”,可获取冯雁教授现场分享完整版PDF。)
— 完 —
加入社群
量子位AI社群7群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot2入群;
此外,量子位NLP技术交流群正在招募,面向正在从事相关NLP领域的工程师及研究人员。
进群请加小助手微信号qbitbot2,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态





