体素科技丁晓伟:医疗影像的哲学三问
医疗影像是什么,医疗影像处理在做什么,医疗影像技术要往哪里去。
撰文 | 邱陆陆
医疗,是「死生亦大矣」层面的讨论。这个鲜少「跟风」、转变审慎到近乎迟滞的行业,领域内研究通常要落后工程技术业界五年。
而这一次深度学习的高热从自然影像蔓延到医疗影像,只用了不到两年。就算数据维度不一样、工具不能套用,研究者们还是义无反顾地跳了这个坑。这等扩散能力,可以说是堪比癌细胞了。
如今,深度学习跨领域的霸权地位,让跨领域的技术探讨变得容易——如今三百六十行里,谁也离不开「分层、激活、反向传播」三板斧。八竿子打不着的两个领域里,讨论起彼此的神经网络也是津津有味。然而医疗影像圈却总是显得格外神秘:当我们谈起医疗影像,除了知道研究对象是五脏庙,最终目的是节约医疗资源之外,仿佛不再有其他谈资。
医疗影像是什么,医疗影像处理在做什么,医疗影像技术要往哪里去。这一回,我们和体素科技创始人、第一批代表医疗影像界吃深度学习这口螃蟹的研究者,丁晓伟博士从技术层面聊了聊这「哲学三问」。
医疗影像和自然影像有什么不一样
医疗影像的特点,一言以蔽之,就是「特别大,同时特别小」。
「大」体现在维数上,也体现在空间分辨率和色彩分辨率上。
无论是人手一部的智能手机还是专业的单反相机,日常生活里的影像都天然是二维的,即使是深度摄像机,也只能捕捉到「2.5 维」的信息:镜头与障碍物之间的直线距离变成了已知,然而中间空气的内容仍然是未知。而许多医疗影像,如 CT(电脑断层扫描)与 MRI(核磁共振成像),则是天然三维的,一个更学术的说法,就是三维坐标系里每一个点都有对应的像素值。
在分辨率上,自然影像界标杆一样的数据集 ImageNet,平均图像大小在 469*387,一般的视觉模型会把图像处理成 256*256 后进行操作。而一张普通的 2D X 光片的分辨率在 3000*3000 左右,一组 3D 的 CT 影像维度则在 500*500*500 左右。
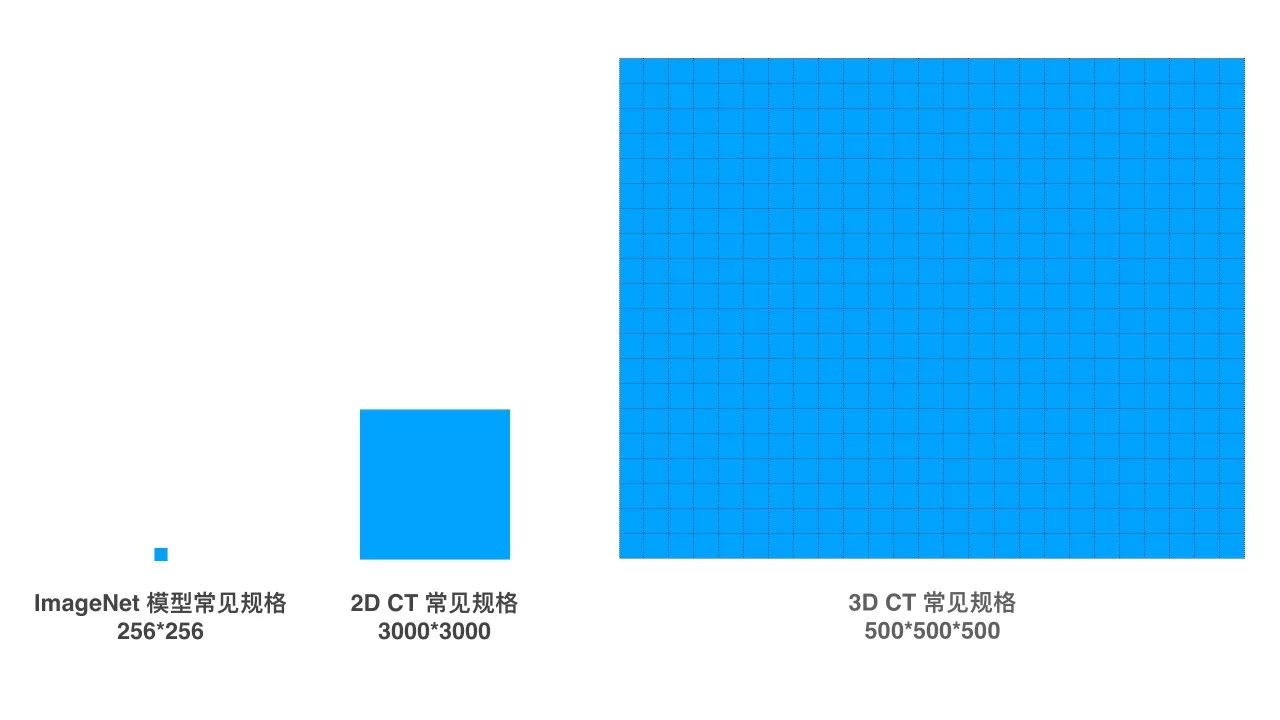
同时,一张 8 位色的自然图像有 256 阶,而一张 CT 影像则有上万阶。这还只是「普通」的医疗影像,至于动辄 50G 一张的病理图片,在医疗影像界也是屡见不鲜。
有人会说,图像大有什么要紧,压缩不就行了?然而自 1895 年伦琴发现 X 光以来,无数医学影像学的工程师与医生穷极职业生涯之力,只为用有限的辐射剂量提供尽可能清晰的影像,力求辅助医生进行更为精确的诊断。每个像素的信息都得来不易,又岂能轻易放弃。
所以,医疗影像模型,还没开始就注定比其他视觉模型难上一个数量级。
既然医疗影像天生就是 3D 影像,所以使用 3D 模型而不是 2D 模型解决问题,听起来似乎是一个理所当然的选项?
其实不尽然。以丁晓伟为代表的第一批将深度学习引入医疗影像的研究者从 2013 年开始做 3D 深度学习模型,但是直到今天,在解决 3D 医疗影像问题上,「2D 和 3D 模型各有优劣,哪种更有效仍然没有定论」。
3D 模型的优点和缺点一样明显。医疗影像问题本身无疑是 3D 问题,病人是 3D 的病人,病灶是 3D 的病灶,2D 截面是会破坏其空间延续性、损失 3D 空间信息量的。一个肿瘤的截面和一个一个血管的横截面,在像素和特征角度都没有任何区别,理论上无法区分开,可只要你上下看一看,蜿蜒的血管和球状的肿瘤就一目了然了。然而,3D 模型也没有成熟的、经过验证的结构。选择了 3D 模型就选择了在知识的荒野里开疆辟土,没有先人证明可行的结构,更不用说经过预训练的参数设置,一切都要从头做起。
而且 3D 模型本身也是一个庞然大物。卷积神经网络(CNN)的高效之处在于它利用了小的卷积核(kernel)来大幅减少需要优化的参数的数量,例如一个 4*4 大小的卷积核只需要对 16 个参数进行优化。但是 3D 模型一下子就把需要优化的参数数量做了指数升级,一个 4*4*4 的卷积核就有 64 个需要优化的参数,随之而来的是过拟合(overfitting)风险的急剧升高,难易训练出泛化(generalization)效果良好的模型。
因此也有研究者试图另辟蹊径,在 2D 空间里找一些技巧来引入 3D 信息:比如把 5 张横截面影像叠在一起,以一个堆(stack)的形式作为模型的输入。而 3D 模型的研究者也想尽办法把图像做聪明的切割和重组。
迄今为止,两种思路打了个平手。谁也没有明显的优势。
但是体素仍然选择了 3D 模型。「也是一个风险很大的探索过程吧。我的个人风格是不太喜欢从工程角度取巧,问题是什么样,模型就应该是什么样。」而面对 3D 模型没有通用数据集、没有预训练模型的弱点,体素的答案也很简单:自己做。「我们想做医疗影像界的 ImageNet。」,丁晓伟说,「我们想把人的各种结构、各类常见病种病理全部交给一个统一模型(unified model),让模型首先对影像里『有什么』有一个概念,然后再针对具体的应用开发精校的模型。」
「小」体现在关注区域上。
自然图像处理问题大多关心的是在图像中贡献主要语义的主要物体,如人,人脸,车辆,车牌,道路,目标面积占画幅比例较大,大的超过 30%,小的也应有 2%。这些目标有较为充足的细节和信息量供深度学习按层级抽取特征。
而在医学影像中则不同,图像中的主要物体是正常的人体结构,而这并不是关注的重点,很多场景关心的目标是早期的微小病灶。假设有一个 3mm 的近似球形的肿瘤需要在薄层 CT 中检出,那么这个目标物体在整个 500*500*500 分辨率的 3D 画幅中只占有不到 25 个体积像素(体素),那么这个物体占画幅比例是不超过 0.0125% 的。并且在一个平面上不足 10 像素的物体上,也是不足以抽取具有层级关系的图像特征的,从而模型纵然有很强的表达能力,也无用武之地。
拿到医疗影像之后,计算机能够做什么
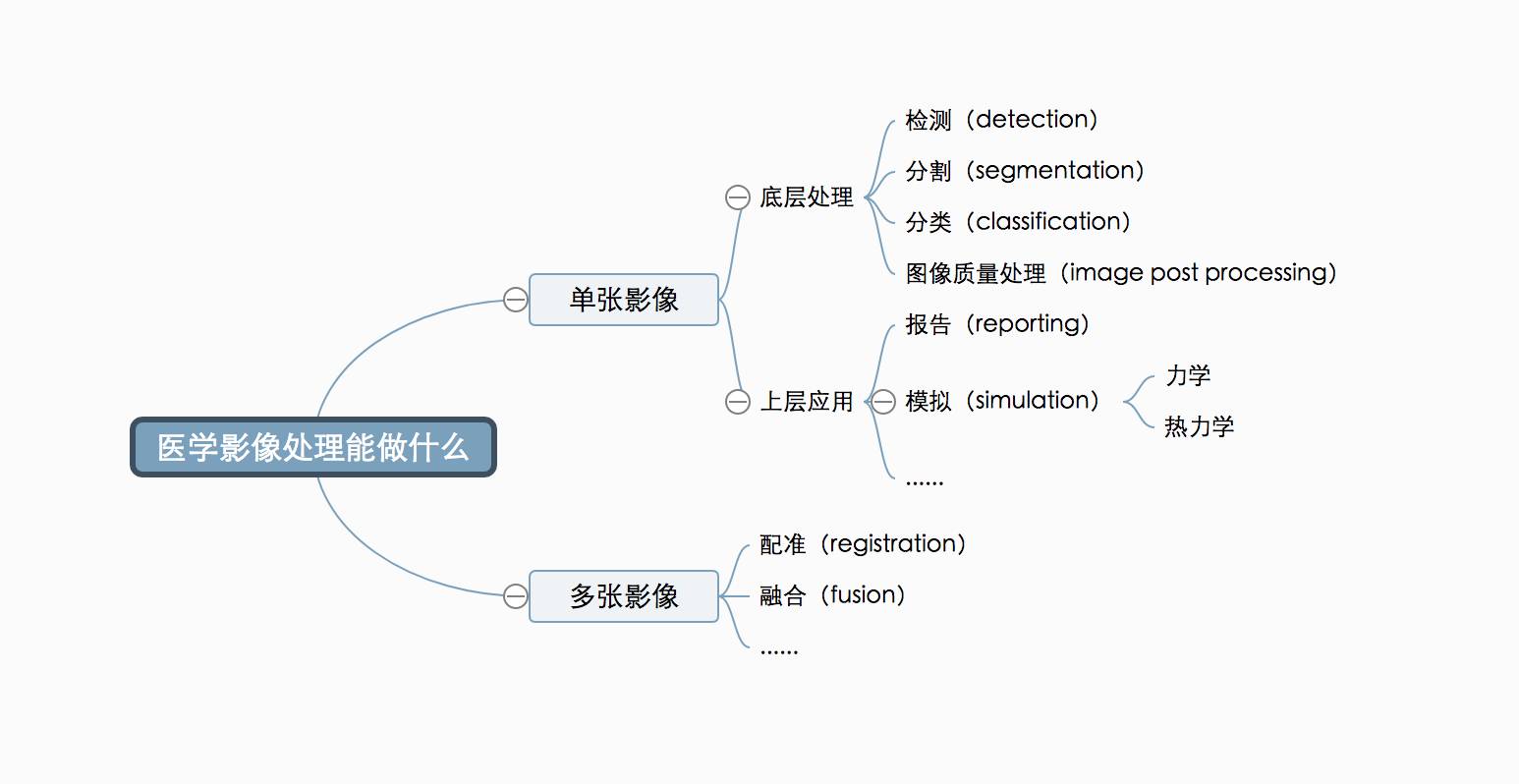
一个比较清晰的分类角度,是先按处理的序列数划分,再按处理的层级划分。
首先,所有的影像都可以在一个序列上进行处理,常见的有检测(detection,用边界框的形式确定物体的位置在哪里),分割(segmentation,找到边缘,能够量化大小等对特征提取比较有利的要素),分类(classification,将分割后的区块归类);图像质量/信息量处理(image post processing,如用生成的方法提高图像分辨率、图像降噪等)。这些处理方式与自然影像的处理方式非常类似。例如,自动驾驶相关的图像处理也需要在连续的图像里用边界框圈出机动车、非机动车、行人等物体。
底层处理完成后,就可以根据接下来要解决的具体问题开发上层应用了。比如,它可以帮帮忙帮到底——帮医生找到病灶之后,把报告也一起写了。当模型能够对底层的分析结果进行语义层面的归纳总结,并且针对需要报告的内容进行系统的训练,转换成自然语言形式的报告就不是太难的事情了。
当计算机对图像中的生理结果和病灶有了认知之后,就可以在此之上完成更多高级任务。比如计算机也可以通过力学和热力学仿真完成大量的组织动态功能重现、手术规划工作。比如,对心脏冠状动脉增强 CT 进行底层处理、重建出心脏血管的管腔和管壁的位置之后,算法可以进一步进行流体力学仿真,重现血液在血管内流动的情况,用于辅助评估一种有创介入检查 FFR 才能获得的冠心病诊断信息。热力学模拟的例子也很多。比如在病灶消融前,通过模拟不同的探针温度、位置,选择最合适的方案。在放射性疗法里,射线无法转弯,所以要确定合适的角度,保证不打到重要的器官,又能尽可能消除肿瘤;射线的副作用也很大,所以要慎重选择剂量,来达到理想的效果…… 带模拟的手术规划就好像把手术这件原来只有一次机会的演出,变成了可以提前一个月「实地有道具彩排」的活动。
不仅仅是这些致命的「疑难杂症」,随着医学手段的不断进步,当一项病症治愈的希望变得很大的,术后生活质量就变成了一项重要的考量,而医疗影像支持的手术模拟在这里的施展空间同样很大。例如,「前列腺癌」虽然听起来很严重,但随着根除手术的普及已经变得几乎不致命了。但是医生逐渐发现,术后很多病人会出现尿失禁症状。研究发现,是前列腺的切除影响了膀胱与尿道的压力平衡,单靠尿道括约肌本身的力量不足以抵抗来自膀胱的压力。于是医生开始利用医疗影像技术做模拟:在术前拍摄膀胱有水情景下的 MRI,进行有重力、甚至跳跃情境下几倍重力的尿道受力模拟,确保其外部压力一直大于内部压力。这就是充分利用计算机的「算力」,做人眼之所不能。
一张影像的应用场景已经如此丰富了,然而多张影像的之上能玩出的花样只有更多。
配准(registration)是把不同扫描序列按照生理结构对齐达到重合的目的,用于对比不同检查中的差异。所以,影像的背景部分可以大刀阔斧地调整,通过变形变换(deformation transformation),把病人每次拍照时因为姿势的不同、压到的腔体部位不同而导致的无法重合问题通过形状、大小、角度的变换来进行对准,保证多组照片之间互相可比。而病灶部分只能严谨地微调,通过只有六个空间自由度(dof)的刚体变换(rigid transformation)进行旋转和位移,保证病灶信息不损失。
融合(fusion)指的是同一病人的不同种类的影像的重叠,旨在把不同类型影像中获得的信息进行综合。比如 CT 可以观察到病灶的位置、结构,却没法了解其代谢情况。如果同时拍摄 PET 核影像(Positron Emission Tomography,将发射正电子的放射性核素标记到能够参与血流或代谢过程的化合物上,注射到受检者体内),同位素会聚集到代谢旺盛的地方,但是无法看清结构。拍摄的虽然是「一模一样」的内容,但却会获得两张「完全不像」的影像,但是计算机影像系统神奇的地方就在于:完全不像也能对齐!对齐之后,医生就能够同时获得结构与代谢信息,可以量化地对用药效果做预测。
虽然表面上看起来,所有医疗相关的创业公司都在做心脏影像、肺部影像,但大多是完成类似的底层处理,事实上,进入到上层应用领域的医疗影像还是一片「处处皆蓝海」的汪洋,切入角度不同、目标问题不同,影像的用法也就完全不同。
体素选择了三个方向发力。其中两个致力于解决大型医疗机构中现有的临床问题,一个旨在满足医疗机构触及不到、但是民间仍然呼唤技术解决方案的需求。
在与美国的 Cedars-Sinai 医疗中心、中国的协和医院等大型医疗机构的合作中,体素想揽下那些「人不愿意做」和「人不适合做」的工作。
「人不愿意做」的是那些重复性的、效率低下的工作:找病灶、量化病灶、随访对比都属于这一类任务。这一类任务看似简单,其实对使用场景场合设计作出了相当高的要求。「许多人对场景问题有误区在,认为做重病、大病使用量最大。其实这里面存在逻辑倒挂。一个面向某『重病大病』的产品理论上是要面向潜在患病群体。然而一位来到医院的咳嗽患者真的需要一个『专看肺癌,准确率极高,但是其他肺病一概不会看』的模型吗?」答案显而易见。「『是否有重病大病』是重要的后验知识,回顾时候有用,前瞻时候,没用。」
「人不适合做」的种种工作里,最常见的是「考眼力」。医疗影像那些细小的蛛丝马迹,常常小到难以刺激人眼捕捉相关模式。比如心血管钙化程度量化,再细心的医生也没精力逐条小血管进行检查,然而计算机是可以的,所以「心脑血管风险量化」由不可能变成了可能。
除此之外,还有大量在数量和难度上无法被医疗机构处理的问题。在百万、千万人规模上进行特定疾病筛查;为尚无表达能力配合医院检查的患儿做被动的视力障碍检查……「医院做不了,民间做不了,全然的蓝海,这样的应用深入挖掘的话,还有非常多。」采访过程中,丁晓伟从头至尾没有提到同业竞争,只有做不过来的项目,和解决不完的新问题。
从业者眼里的技术壁垒和破壁方向
定义了研究对象,了解了研究方法,接下来我们谈谈业内人士眼里这个领域的「边界」。
「我专门拿这个问题问了很多周围的研究者,这是一个汇总而来的答案。」,两个小时的采访里,这是丁晓伟第一次拿起手机。
首先是如何降低标记数据的成本和工作量。
一位成熟的影像科医生需要八年学习与更长时间的临床经验。即使人工智能所催生的数据标注行业发展再快,也很难培养出具有类似相应水平的标注员。更何况,即使是专业人士之间,观察者方差也很大。两位医生标记同一张影像,结果也可能相差甚远。
因此,不断有新的标记简化方法被开发出来。类似自然影像领域的迭代标记很快被采用:初始模型完成开发之后,立刻接棒大规模标记工作,人工转而花在质量控制工作上。还有一些从一开始就试图以更加系统化的思路拆分问题的方法:如果一个万张规模的数据库摆在你面前,你只有能力标注两千张,那么你选择哪两千?这是一个复杂的统计学采样问题:要在无监督的前提下,选择两千张既能贡献平衡的分布、又能反映典型特征、还能照顾到异常值的数据。这是一个直接影响最终模型质量的关键选择。
然后是多任务(multi-tasking)模型的开发。
医疗影像问题基本可以拆解成一串彼此相连的问题:找到异常位置、判断异常类型、量化异常大小,再加上开始治疗后的随访对比。既然选择做分析,就没有只做一项的道理。可是如果每一个环节都用专门模型做,一张图要被来回调用三、四遍,模型间还不能相互借鉴经验,这对于计算资源和医疗资源,都是一种浪费。
能不能无缝地把几项任务衔接起来?找病灶的同时能否完成分割与分类呢?在多任务意识上,医疗影像界和自然影像界可以说不谋而合。Facebook 的何恺明于 CVPR 2016 发表的论文就是以多任务 CNN 为主题。实践证明,联合任务的效率与表现比单独完成任何一个任务都要高。
此外还有多实例认知(multi-instance awareness)。
如今的分割算法可以把图像中的淋巴结区域从非淋巴结区域里分割出来。却没办法把一团淋巴结彼此区分开来。在实际治疗里,可能淋巴结「张三」需要整体切除,淋巴结「李四」却值得部分保留。可惜分割模型是个脸盲患者,面对病灶出现在多个实例上的「多发情况」,只能机械地对所有实例一视同仁。无差别对待不可行,所以需要让模型有能区分「张三」和「李四」的能力。
而最重要的,是对医疗大数据的定义和利用。
虽然单张数据信息量很大,但如今以千、万为数据单位的医学影像和以百万、千万为规模的自然影像相比,还远不能算一个「大数据」问题。差距不仅体现在横向比较,如今拿出来能用的医疗数据和医院里存储的数据相比也是九牛一毛。
「真正的大数据,是就把躺在医院数据库里的数据、就把临床过程里记录下来的数据拿出来用。」所以,不懂自然语言的计算机视觉专家不是好的医疗影像研究者。医生的病例报告里对病灶位置的描述,就是最好的标注。把文字转换成边界框,再转换为算法的训练集。只有不需要刻意进行的数据标注,才是处理百万、千万级别数据的办法,才是医疗大数据问题的答案。这是为医疗影像领域「修高速公路」的工作,什么时候这条高速公路通车了,什么时候医疗影像才能真正进入「大数据时代」。Nvdia 和 NIH 的 Le Lu 博士的工作代表了这个方向的先进成果。
体素的公司愿景里,有一条是「提供医疗语义级别的医学影像知识图谱 API」。采访开始前,我曾经对这个用两组形容词就横跨了计算机视觉和自然语言处理的说法感到困惑。
原来为了医疗这个崇高的目标,真的有研究者踏上了修建沟通语言与图像的巴比伦塔的征途。

点击「阅读原文」加入「AI 商用搜索」合作计划,全面进行公司应用实例展示及垂直合作:


往期文章
大公司:微软、亚马逊、阿里、百度、腾讯、英伟达、苏宁、西门子、浪潮
创业公司:商汤科技、依图科技、思必驰、竹间智能、三角兽、极限元、云知声、奇点机智、景驰科技、思岚科技、追一科技、海知智能、出门问问、钢铁侠科技、体素科技、晶泰科技、波士顿动力、弘量研究、小源科技、中科视拓
人物报道:吴恩达、陆奇、王永东、黄学东、任小枫、初敏、沈威、肖建雄、司罗、施尧耘
自动驾驶:传统变革、Uber、图森未来、速腾聚创、驭势科技、全球汽车AI大会