我建议你最好掌握“网络挖掘“!
如果你有几年数据分析经验,或是掌握一定的统计算法/机器学习技能,为了个人能力更好的提升,建议你最好掌握“网络挖掘”。
但不少人对“网络挖掘”所知甚少,到底什么是网络挖掘呢?
网络型数据挖掘(简称网络挖掘)是一项主流的、重要的数据挖掘技术,常见的如社交网络、购物网络、金融网络等网络类型在生活中无处不在,做好网络挖掘可在用户画像、推荐系统、搜索引擎金融风险评估、知识图谱、城市交通优化方面产生极大作用。
不同于一般意义的数据挖掘通过算法模型(比如常用的回归、分类、聚类模型)进行描述/预测,网络挖掘则给出了新的解决方式:通过将数据 / 问题抽象为网络模型,来帮助我们更好地进行数据分析 / 数据挖掘。
网络挖掘在基本的描述性统计方面又更进了一步,从某种程度上可以发现很多我们做一般的描述性分析所得不到的深刻洞见。
很多业务用一般的数据挖掘方法效果不佳的,加入网络模型之后,却能大幅提升。可以说网络挖掘的应用舞台无限宽广......

网页排序
比如谷歌的 PageRank,本身也是在构建庞大的网页网络模型的基础上(网页为节点,超链为边),通过计算不同网页的中心度(权重),来对网页进行排序,从而实现更加精准的搜索和推荐。
推荐系统
传统的协同过滤算法的基本思想是,将与目标用户选择相似性度较高的用户喜欢的商品,推荐给目标用户。而网络模型的加入(比如好友网络、商品网络),很大程度上解决多样性问题、冷启动问题、社会推荐问题,从而提升某些场景下的推荐精度。
社交网络分析
社交网络天然适合构建网络模型进行分析,比如信息的传播预测、影响力分析、社交组群发现、好友推荐、用户画像等,单独拿出来看个体,和其他的个体拿出来看,发现一些不一样的东西。从某种程度说,社交网络分析是建立在网络模型分析的基础之上。
( 网络挖掘应用举例 )
-
其他的分析方法得不到的深刻洞见,并以此指导实际业务中的决策; -
能够通过网络挖掘去构建商业模型,比如 社交推荐与消息传播模型、商品推荐系统、金融风控模型 等,这才是数据真正产生价值的地方; -
在很多细分领域工作中,你将获得更多加分。
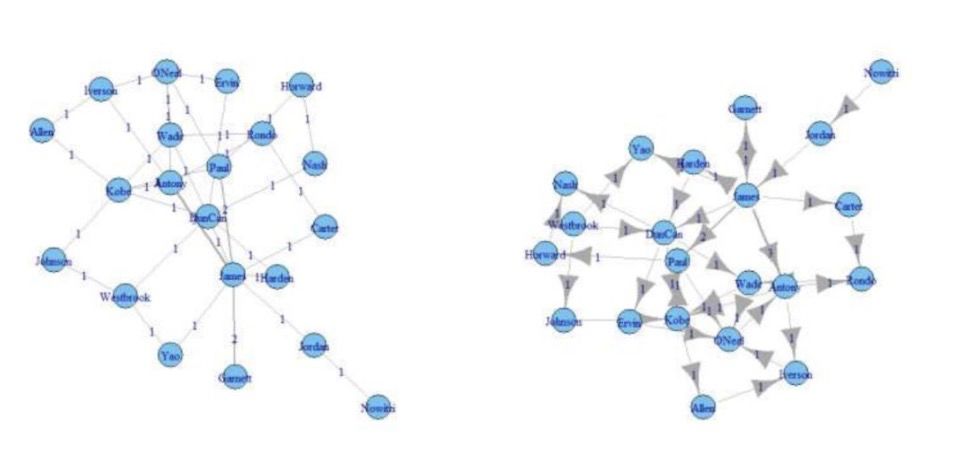
(2)如何从传播网络中找出大V ?
中国教育创新校企联盟首席数据科学家、专家委员会副主任,中国计算机学会技术前线委员会(CCF TF)数据科学研讨会主席,国家技术标准创新基地(贵州大数据)数字经济专业委员会专家,北航、西安交大、人大、对外经贸、武大等多所高校客座教师。

《 数据科学家必备:网络挖掘理论与案例实践 》
1. 网络挖掘定义与基本概念
网络元素、最短路径、网络直径、密度等常用概念
2. 网络挖掘常用算法
——社群划分、中心性分析等常用算法
社交网络分析(SNA)
(1)邻接矩阵(link)
(2)度数(degree)
(3)最短路径(shortest path)
(4)距离(distance)
(5)直径(Diameter)
(6)密度(Density)
(7)modularity Q
中心性分析
(1)点度中心性
点度中心度(degree centrality)
(2)中间中心性
(3)接近中心性

请大家耐心等待,会一一通过申请



