NIPS 2018 |谷歌大脑提出 DropBlock 卷积正则化方法,显著改进 CNN 精度
由极市、机器之心和中科创达联合举办的“2018计算机视觉最具潜力开发者榜单”评选活动,现已接受报名,杨强教授、俞扬教授等大牛嘉宾亲自评审,高通、中科创达、微众银行等大力支持,丰厚奖励,丰富资源,千万渠道,助力您的计算机视觉工程化能力认证,提升个人价值及算法变现。极市与您一起定义自己,发现未来~点击阅读原文即可报名~
来源:我爱计算机视觉
转载自我爱计算机视觉,未经允许不得二次转载
近日arXiv新上一篇被NIPS2018会议接收的论文《DropBlock: A regularization method for convolutional networks》,作者为来自谷歌大脑的研究人员,提出了一种专门针对卷积层正则化的方法,有效改进了CNN的各种任务,非常值得一读!
作者信息:

文中指出,在目前的神经网络训练的广泛实践中,全连接网络加DropOut是一种有效的正则化方法,但将DropOut加到卷积层却往往难以奏效。
为什么会这样呢?
作者认为这是因为卷积层的特征图中相邻位置元素在空间上共享语义信息,DropOut方法在整幅特征图随机丢弃元素,但与其相邻的元素依然可以保有该位置的语义信息。
为了更加有效丢弃局部语义信息,激励网络学到更加鲁棒有效的特征,应该按块(block)丢弃(drop),这就是DropBlock的由来。

上图中绿色区域代表卷积层后的激活层特征图中带有语义信息的区域。
(b)为使用DropOut的示意图,即在整幅特征图中随机丢弃一些元素的结果,虽然绿色区域有元素被丢弃,但因为特征元素之间空间上的语义信息相关性,这种操作并不能有效激励网络学习剩下的区域的语义特征。
(c)图为DropBlock方法,语义信息区域被空间连续的丢弃,使得网络不得不专注于剩余含有语义信息区域中特征的学习。
算法思想
那如何按块(block)丢弃(drop)呢?
我想大部分人第一直觉是在特征图中随机生成种子点,在种子点周围按照一定的宽高将元素置0,本文中就是这样做的。
算法描述和示意图如下:
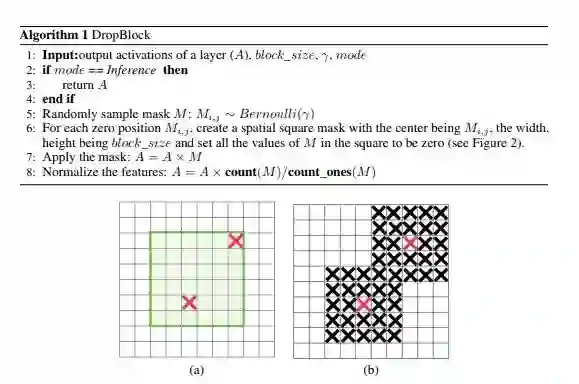
上图中绿框以内是按照block_size计算得来的可以生成种子点的区域(为了保证block不出特征图),红色X标出的元素即为种子点,黑色X标出的元素即为置0的区域。
其中有几个参数,论文中唯一的一个数学公式就是关于其中一个参数的计算。(唯一的公式看起来也不是特别得重要)
实验结果
为了验证该方法的有效性,作者在ImageNet图像分类、COCO目标检测、PASCAL VOC 2012语义分割等三个大型真实世界数据库上的不同任务中做了实验。
都有显著的性能提升。
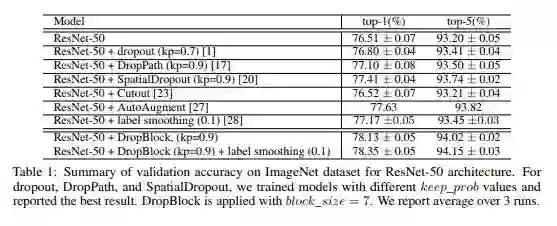
ResNet-50网络+DropBlock在ImageNet验证集的结果,显著提升了分类精度。
下图是在state-of-the-art分类网络AmoebaNet上加DropBlock的结果,top1和top5都取得了稳健提升。

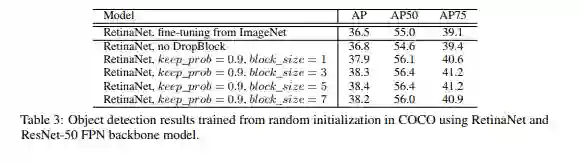
下图是使用RetinaNet检测网络加DropBlock在COCO目标检测任务上的结果,依然表现优异。
下图为RetinaNet语义分割网络从随机初始化开始加DropBlock,在VOC2012语义分割任务中的提升结果。

总结
该文想法非常有道理,方法也非常简单,实验结果很有说服力。也许会成为未来CNN的标配。
论文地址:
https://arxiv.org/abs/1810.12890v1
关于代码:
该文目前并无代码,但个人实现起来也不难,考虑到三位作者来自TensorFlow的大本营谷歌大脑,所以未来也许会直接加到TensorFlow中去。
你认为这项工作如何?欢迎留言~
*推荐阅读*
NIPS 2018 | 行人重识别告别辅助姿势信息,商汤、中科大提出姿势无关的特征提取GAN
资源 | 谷歌开源AdaNet:基于TensorFlow的AutoML框架
DeepMind开源图深度学习(GraphDL)工具包,基于Tensorflow和Sonnet
杨强教授、俞扬教授等大牛嘉宾评审团,万元大奖,丰富资源,助力您的计算机视觉工程化能力认证,点击阅读原文即可报名“2018计算机视觉最具潜力开发者榜单”~




