BERT模型超酷炫,上手又太难?请查收这份BERT快速入门指南!
选自GitHub
作者:Jay Alammar
参与:王子嘉、Geek AI
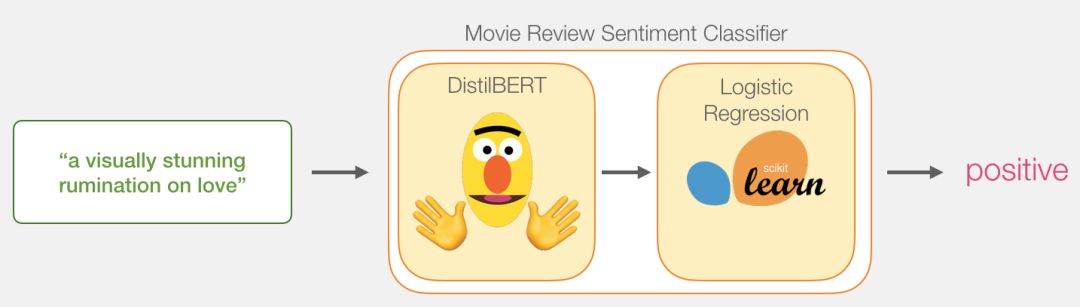
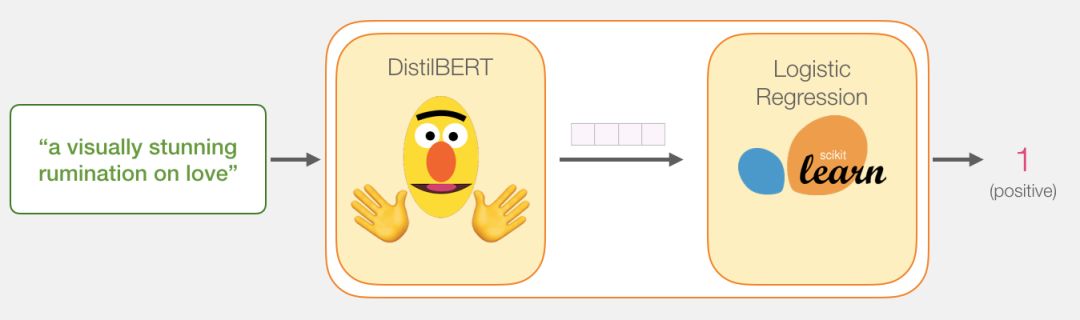
如果你是一名自然语言处理从业者,那你一定听说过最近大火的 BERT 模型。 本文是一份使用简化版的 BERT 模型——DisTillBERT 完成句子情感分类任务的详细教程,是一份不可多得的 BERT 快速入门指南。

| sentence | label |
|---|---|
| a stirring , funny and finally transporting re imagining of beauty and the beast and 1930s horror films | 1 |
| apparently reassembled from the cutting room floor of any given daytime soap | 0 |
| they presume their audience won't sit still for a sociology lesson | 0 |
| this is a visually stunning rumination on love , memory , history and the war between art and commerce | 1 |
| jonathan parker 's bartleby should have been the be all end all of the modern office anomie films | 1 |

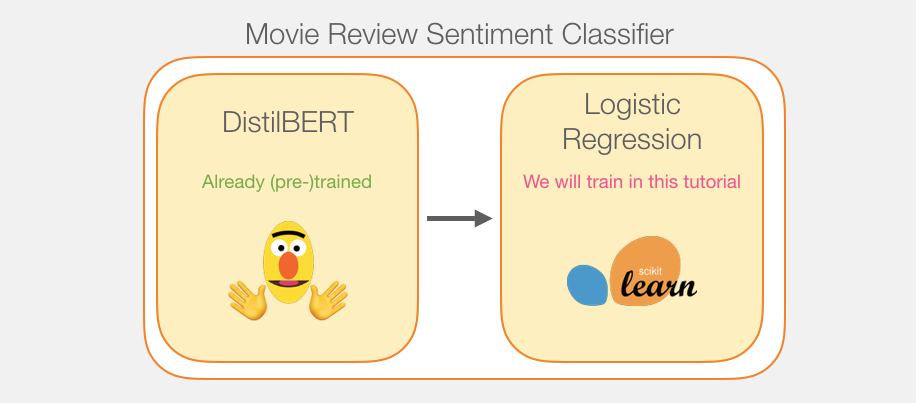
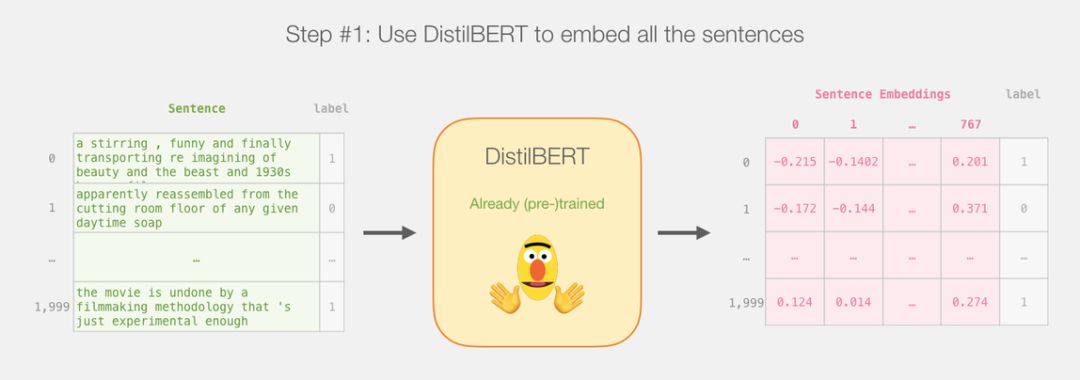
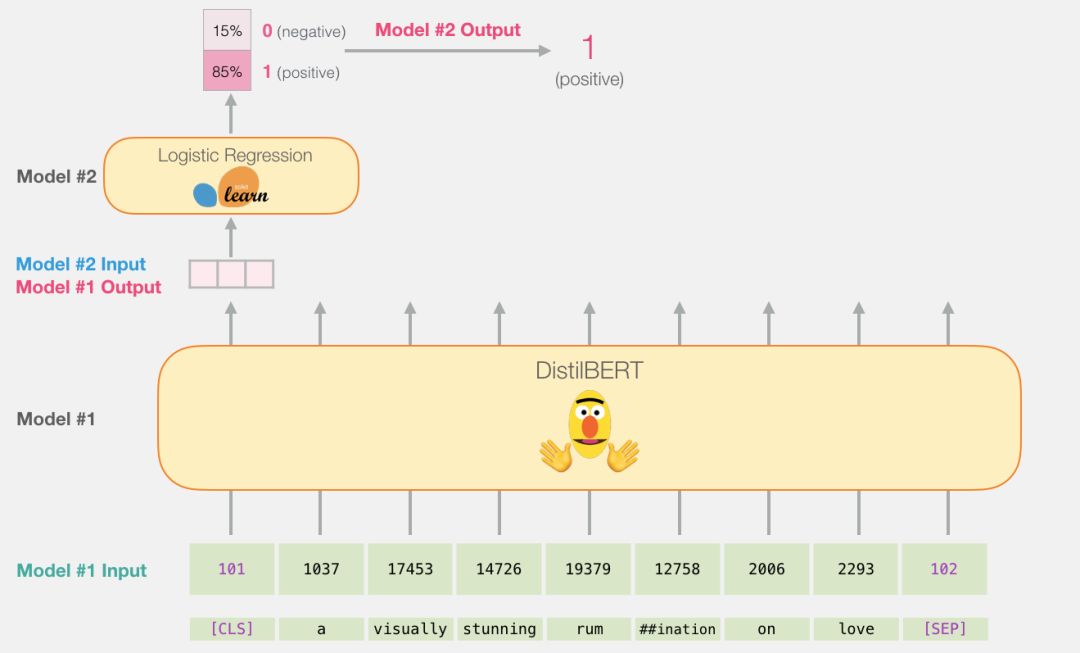
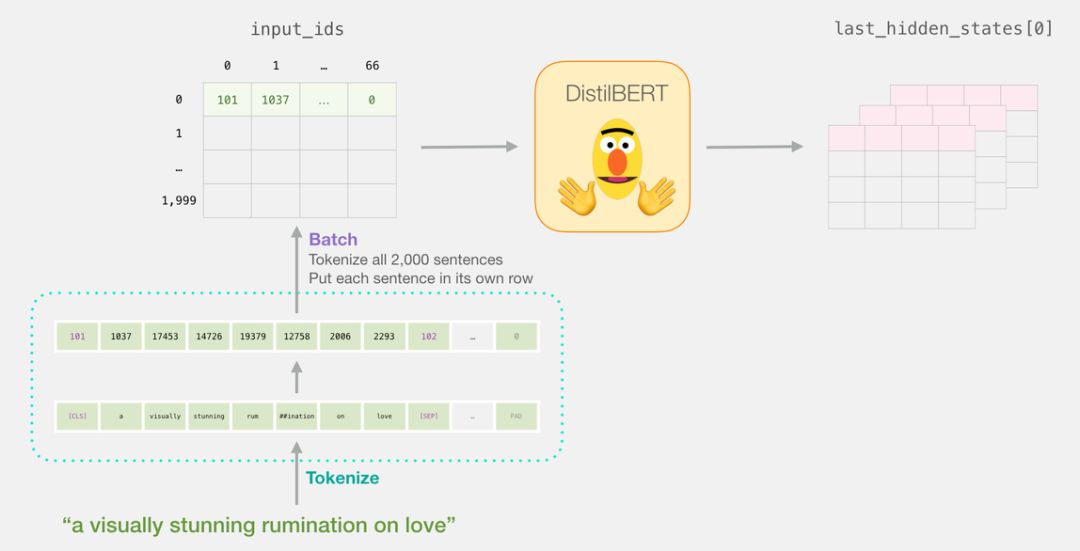
DistilBERT 先对句子进行处理,并将它提取到的信息传给下个模型。DistilBERT 是 BERT 的缩小版,它是由 HuggingFace 的一个团队开发并开源的。它是一种更轻量级并且运行速度更快的模型,同时基本达到了 BERT 原有的性能。
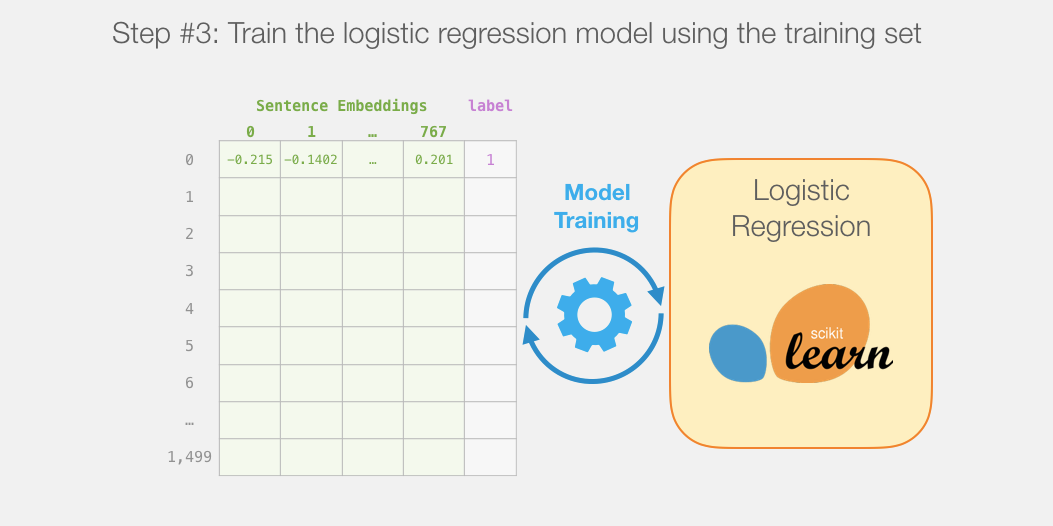
另外一个模型,是 scikit learn 中的 Logistic 回归模型,它会接收 DistilBERT 处理后的结果,并将句子分类为积极或消极(0 或 1)。


tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)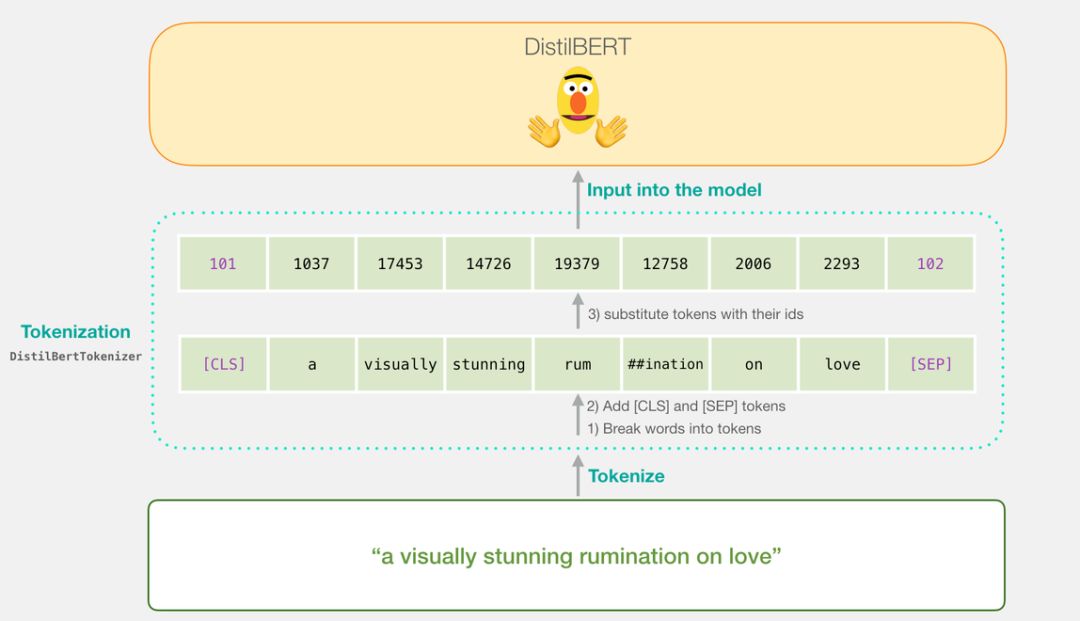
import numpy as np
import pandas as pd
import torch
import transformers as ppb # pytorch transformers
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_splitdf = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)df.head()
输出如下:

model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
## Want BERT instead of distilBERT? Uncomment the following line:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')#
Load pretrained model/tokenizertokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)tokenized = df[0].apply((*lambda* x: tokenizer.encode(x, add_special_tokens=True)))
T
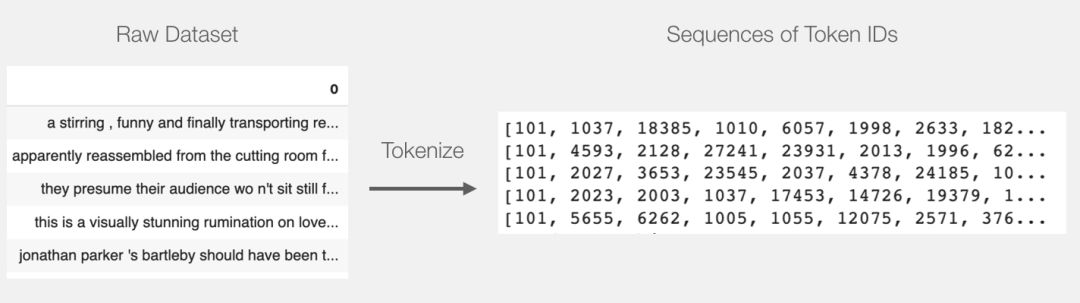
上面的代码将所有句子转化为了编号的列表。

input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)
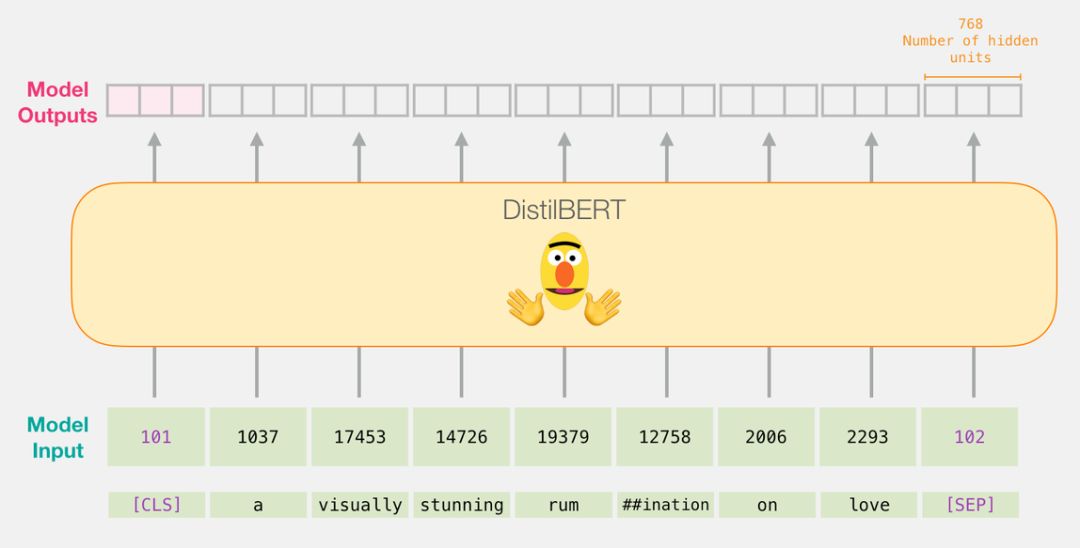
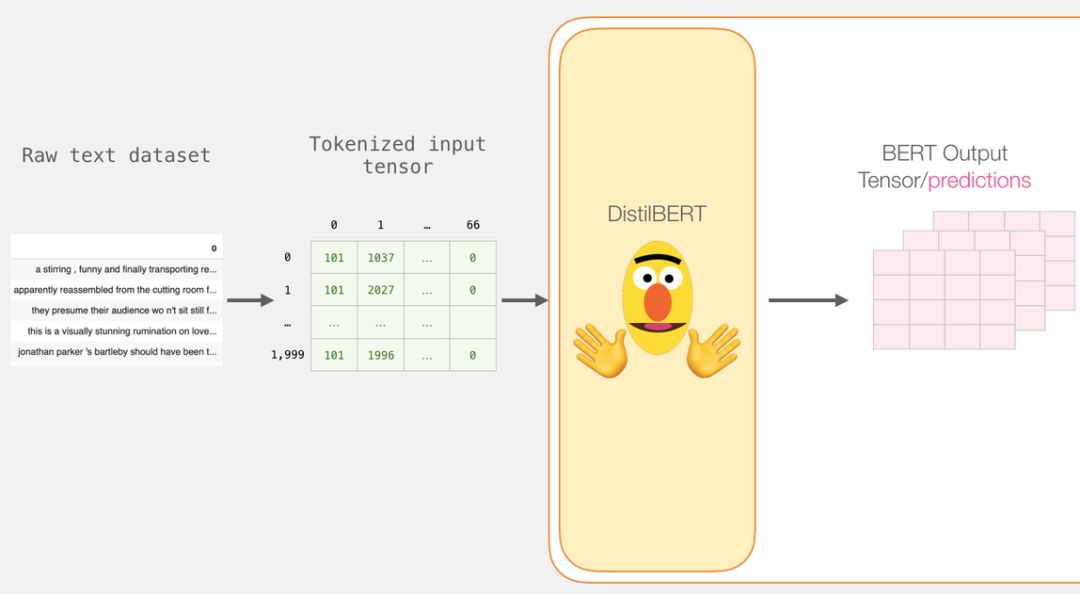
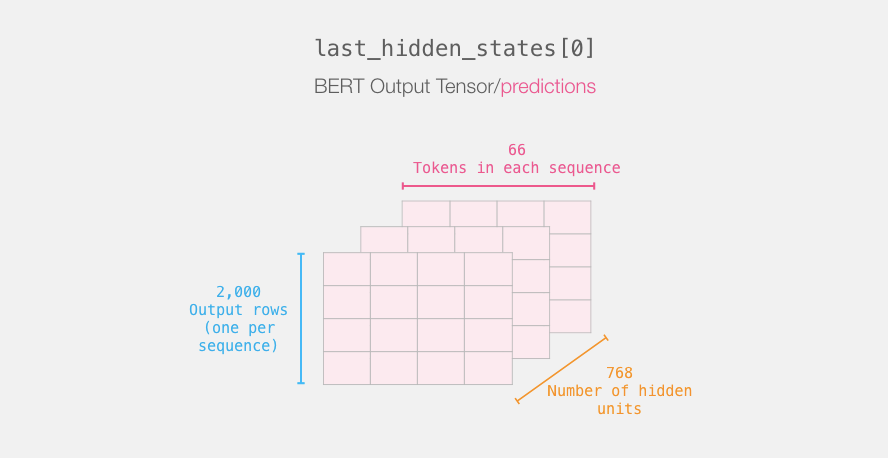
这一步完成后,会将 DistilBERT 的输出赋给「last_hidden_states」。这是一个维度为(句子数,序列中的最大词数,DistilBERT 模型中的隐藏层数)的元组。在本例中,这个维度就是(2000,66,768),因为我们有 2000 个句子,2000 个句子中最长的序列长度为 66,DistilBERT 模型中有 768 个隐藏层。
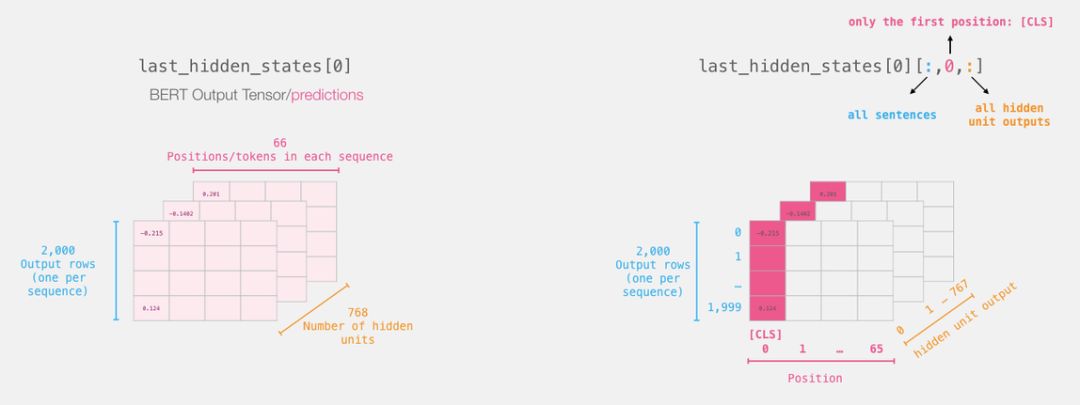
# Slice the output for the first position for all the sequences, take all hidden unit outputs
features = last_hidden_states[0][:,0,:].numpy()
现在,「features」是一个二维的 numpy 数组,它包含了我们数据集中所有句子的嵌入。
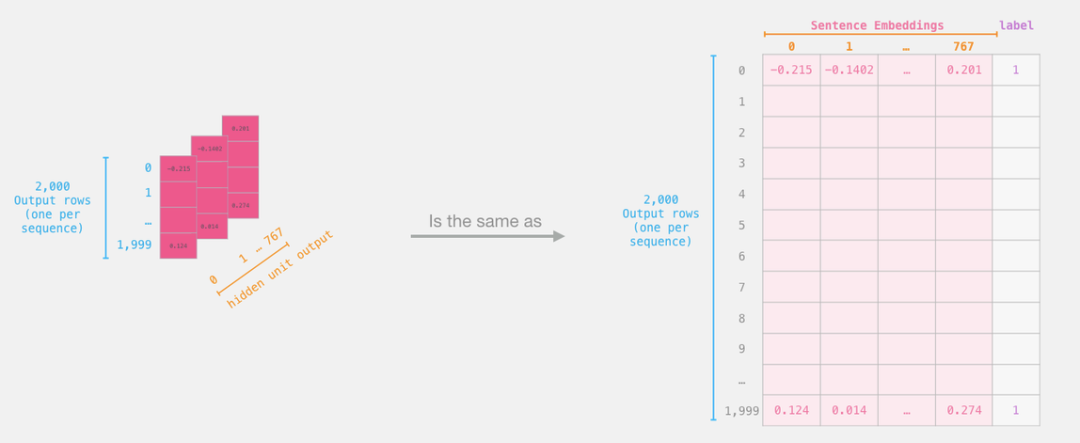
现在我们已经得到了 BERT 的输出,并且把训练 logistic 回归模型的数据集组装好了。这 768 列是特征,我们还给出了原始数据集中的标签。
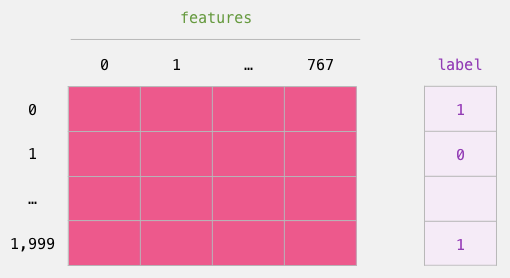
labels = df[1]
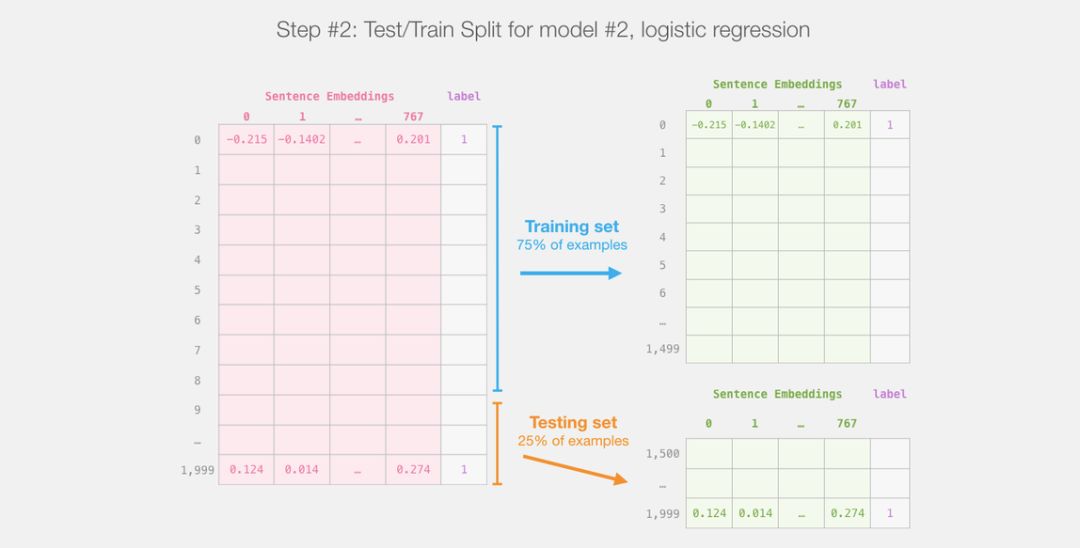
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)
现在模型已经训练好了,我们可以用测试集对其进行评估。
lr_clf.score(test_features, test_labels)上面一段代码的输出告诉我们这个模型获得了 81% 的准确率。
作为参照,在这个数据集上所能达到的最高的准确率是 96.8。在这个任务中,我们同样可以训练 DistilBERT 来提高其得分,也就是通常所说的调优过程,该过程可以更新 BERT 的权重参数,并让其在句子分类任务中(通常被称为「下游任务」)获得更好的性能。经过调优后的 DistilBERT 可以达到 90.7 的准确率,而完整的 BERT 可以达到 94.9。

点击阅读原文,立即访问。