AI赋能法律 | NLP最强之谷歌BERT模型在智能司法领域的实践浅谈
作者:实在智能算法专家徐亮
本文已获授权转发,可点击文末“阅读原文”直达原文链接

10月中旬,谷歌AI团队新发布的BERT模型,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:两个衡量指标上超越人类,并且还在11种不同NLP测试中创出最佳成绩,奠基新的NLP里程碑。后续,谷歌开源了该项目,并且公布了包括中文字向量预训练模型等在大规模数据上预训练过的通用模型。随后,陆续有AI业界同仁尝试在不同任务中应用BERT预训练模型,其中有团队在AI Challenger阅读理解赛道中取得了最好成绩。
开源项目公布之前,我们对BERT论文进行了学习和讨论,并根据论文思想实现了简化版、预训练的TextCNN模型。在预训练的中文BERT模型公布不久,作者写了一个BERT中文预训练模型的简短教程,并将模型成功部署到我们正在推进的“AI赋能法律”相关系统。
最近,我们结合智能法律评估工作实践对pre-train和fine-tune不同模式下BERT模型与经典模型的效果差异进行了对比,发现即使仅训练有限轮次,预训练过的BERT模型也能取得很不错的效果。本文将具体介绍上述实践和探索,同时也将介绍在谷歌TPU上训练定制版BERT模型的过程。
关键词:
BERT; pre-train; fine-tuning; performance; sequence length; TPU; multi-label; on-line prediction

01
1. 模型效果对比
我们使用司法领域的公开数据,在10万份民事判决书上进行训练和效果对比。输入包括原告诉求请求、事实描述或法院认定的事实以及特定案由下的诉求类型;输出是“0,1”。“1”代表支持原告,“0”代表不支持原告。训练数据包含11个民事大案由,55个诉求类型。所有诉求类型的数据都经过采样,支持与否比例为1比1。虽已预先过滤了一部分缺失证据、诉讼时效存在问题等影响结果预测的数据,但数据集中仍存在不少噪音。字符级别文本平均长度为420。报告的准确率,指验证集上的准确率。
数据集:100k, 55个类别, 二元分类,验证集上准确率,类别平衡

3L代表3层网络;sent-piar代表sentence pairs即句子对任务;seq-512代表sequence length即最大句子长度为512;batch32表示batch size即批次大小为32;epoch10代表训练10轮次。其他简写,表示类似意思。
从训练结果来看,有以下初步结论:
(1). 在同等条件下,使用句子对 (sent-pair)形式和单纯的文档分类(classify)的形式,来做本任务,效果相差不显著;
(2). 根据12层(12L)和3层(3L)的模型对比效果,在本任务中暂不能得到 “更多层的BERT模型效果更好”的结论;
(3).最大序列长度(max sequence length)对模型的效果影响比较大。最好的模型是序列长度为512、使用3层的预训练过的BERT模型。随着最大序列长度增加,效果有所提升,但模型的训练时间也相应增加。当最大序列长度变小后(如截取信息),模型的准确率下降约3-4%。
(4). 批次大小(batch size)对模型的效果影响也比较,如从64下降到16后,模型的准确率下降幅度较大。
(5).fine-tuning模式下略微提高训练轮次(epoch) ,效果可进一步提高2-5%。
(6). 不同模型效果对比: BERT模型>Fasttext模型(仅需训练几分钟,准确率仅比BERT模型低3.5%)>TextCNN模型。可能的原因是我们的智能法律评估任务并不仅关注关键词等局部信息,同时要结合文本中很多信息做综合判断。
需要说明的是,本次效果对比在有限时间内完成,虽然每个模型都有做了一些调优工作,但这些模型如能结合一些其他技术、特征工程等,可能都有比较大的提升空间。
除上述结论外,我们还发现了BERT预训练模型在特定情况下(GPU环境,显卡配置固定)长文本任务中的困境——无法同时增大对最终效果提升有帮助的批次和最大序列长度。
从总体上看,在我们的任务中,使用比较长的序列长度,比较大的批次大小,效果比较好。但由于BERT模型比较大,在11G的显卡环境下,使用12层的网络、512的序列长度,批次大小最大只能设置为4,批次过小,导致训练会不稳定。而使用256的序列长度,批次可以增大为16,但很多信息又被丢失,效果也不佳,从而陷入两难境地。
2. 在自己的数据集上运行BERT的三个步骤
(1).在github上克隆谷歌的BERT项目,下载中文预训练的模型;
(2).分类任务中,在run_classifier.py中添加一个processor,明确如何获取输入和标签。之后将该processor加到main中的processors。将自己的数据集放入到特定目录。每行是一个数据,包括输入和标签,中间可以用特殊符号,如”\t”隔开。数据集包含训练集(如train.tsv)和验证集(如dev.tsv);
(3).运行命令run_classifier.py,带上指定参数,主要包含:训练的任务类型、预训练的模型地址、数据集的位置等。
03
3. 在自有数据集上做pre-train,然后做fine-tune
如果有任务相关的比较大的数据集,可在BERT中文预训练模型的基础上,再使用自有数据集做进一步的预训练(可称之为domain-pre-train),然后在具体的任务中做fine-tune。
需要做的工作包括:
(1)从领域相关的数据集上抽取出预训练文本。文本的格式如下:每一句话是一行,每一个文档直接用空行隔开。
(2)将预训练文本转换成tfrecord格式的数据。
运行 create_pretraining_data.py
(3)预训练模型pre-train
运行 run_pretraining.py
(4)调优模型(fine-tuning)
运行 run_classifier.py
预训练任务上的效果对比:
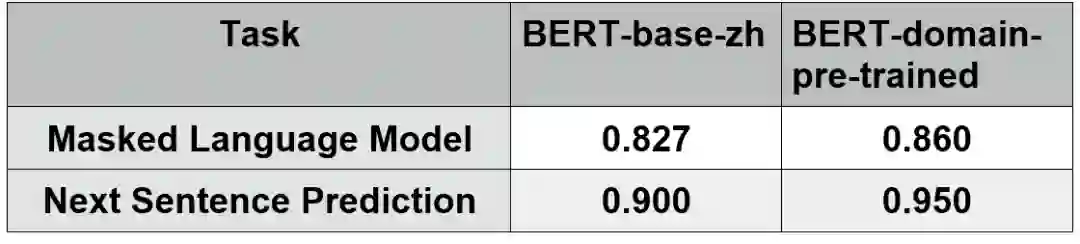
由此可看到,使用领域相关的数据做pre-train,在两个预训练任务上,效果提升了3-5%。在我们的实验中,为了加快预训练速度,只选取了领域相关的300万行数据,运行12个小时,1/3个epoch,但预训练任务的准确率还是有明显的提升。
领域相关的任务上的效果对比:

我们使用了5个不同业务类别的数据,文本平均长度超过400,预测结果为0或1。
使用领域相关的数据做pre-train,相对直接使用BERT预训练过的模型,绝对值有4.4%的提升,相对值有5.9%的提升。
随着使用更大的领域相关数据,并且增加训练轮次,相信效果会有进一步的提升。
04
4. 在TPU上使用BERT模型
下面简单介绍使用TPU的两种方式。任何一种方式下,都需要有谷歌计算引擎的账户,以及谷歌云存储的账户来存储数据和保存训练过的模型。使用TPU的好处之一是可以利用其强大的计算能力,犹如在CPU时代使用GPU来训练,大幅提升训练速度和效率。
Google Colab notebook方式体验TPU
可通过Google Colab notebook 免费使用TPU, 体验在TPU环境下,BERT在两个自带数据集的分类任务: "BERT FineTuning with Cloud TPUs"。但这个Colab主要是demo形式为主,虽能得出训练和结果,但可能仅支持BERT自带任务。
CTPU方式访问TPU(谷歌云专门访问TPU环境的工具)
相比方式一,这是一个真正的生产环境,可以训练模型。序列长度为512,在普通GPU下只能支持batch size为4,而在TPU下可以设置为128。从下图可以看到训练使用了8卡的TPU,每个卡训练的batch size为16.
可通过谷歌的ctpu工具(见ctpu的github项目说明)运行“ctpu up”命令进入tpu环境。
(1).需要谷歌云账号和google cloud storage(gcs)存储服务。
(2).在gcs中新建bucket,放入训练和验证数据、BERT预训练过的模型。之后可通过gs:\\形式,像访问本地文件一样访问存储服务中的数据。如新建了一个名叫data_training的bucket,那么在TPU中它的地址就可以写成
“gs:\\data_training”。
(3).在TPU环境下克隆并下载自己定制的BERT项目(或github上谷歌的BERT项目)。
(4).像在GPU里一样运行命令训练任务,只需加上参数use_tpu=true。训练完后,从谷歌存储位置的bucket中下载模型的checkpoint。
TPU下的训练,Sequence length=512, batch size=128
第一次仅训练了三轮后的准确率为0.739,模型的检查点(checkpoint)自动被保存到预先设定的谷歌存储服务的bucket中。如下图:

05
5. 使用BERT模型做多类别任务
BERT模型本身只支持二分类或多分类,或是阅读理解任务和命名实体识别任务。如需支持多类别任务(multi-label classfication),则需要定制。具体可基于tensorflow的高级API(tf.estimator)来修改,也可以直接基于session-feed的风格实现。其中,基于session-feed方式主要修改如下:
(1)修改损失函数,使得多个类别任务具有非排他性。
(2)将一些输入、标签等,特别是是否训练(is_training)的参数,变成占位符(placeholder)。这样可使用feed方式提供训练或验证数据;从而也可以根据训练、验证或测试的类型,来控制模型的防止过拟合的参数值(dropout的比例)。
因为做的是分类任务,需要在输入序列的第一位插入特殊符号[CLS],训练完后,模型根据最后一层的[CLS]所在的位置的隐藏状态(hidden states),得到做为整个任务状态的表示(representation)。
(3)根据BERT数据转换的方式,以feed方式在session中将转换后的数据通过占位符输出至模型。
06
6. 使用BERT模型做在线预测
BERT模型本身在训练或验证中只支持从文件中读取数据,并不支持在线预测。可基于session-feed方式,根据BERT数据转换的规则,将需要预测的数据提供给模型,从而获得预测的概率分布,并完成预测。
07
7. 总结
BERT发布之前,模型的预训练主要应用于计算机视觉领域。BERT发布后,很多NLP相关工作可在BERT模型预训练的基础上完成,使得自然语言处理更加成熟,支持在不同应用场景取得更好效果。
BERT模型在很大程度上提升了短文本、阅读理解等任务效果,但由于目前业界单个显存大小的限制和瓶颈,在长文本等任务上存在占用较大计算资源和效果打折等问题。
在后续的工作中,我们将继续尝试提升BERT预训练模型在长文本上的效果,如在领域相关的大数据上训练、采用基于词向量的BERT模型、使用滑动窗口方式应对文本过长的问题以及在TPU环境下实施大数据集的大规模训练等。
实在智能
算法团队

徐亮,实在智能算法专家,在深度学习、文本分类、意图识别、问答系统方面有非常深入的研究和创新,github top10最受欢迎的文本分类项目作者。
对人工智能领域感兴趣的朋友,欢迎投简历到talent@i-i.ai
实在智能团队期待你的加入!
专业|创新|AI赋能商业


有爱有AI ,智能更实在
官网:i-i.ai 商务洽谈:contact@i-i.ai


