微信智言夺冠全球对话系统挑战赛,冠军解决方案全解析
机器之心原创
作者:路
如何利用端到端的对话系统基于 Fact 和对话历史生成靠谱的回答,微信智言团队有话说。
前不久,微信智言团队夺得第七届对话系统技术挑战赛(DSTC7)Track 2 赛道的冠军。
DSTC7 挑战赛由来自微软研究院、卡耐基梅隆大学(CMU)的科学家于 2013 年发起,旨在带动学术与工业界在对话技术上的提升,是对话领域的权威学术比赛。本届挑战赛分为三个方向,微信模式识别中心参加了其中一个方向:基于 Fact(如百科文章、Blog 评论)与对话上下文信息自动生成回答。共有 7 支队伍、26 个系统参加该竞赛。
据了解,微信智言团队的主要参赛成员是微信模式识别中心的暑期实习生 Jiachen Ding,目前在上海交通大学读研;另一名成员 Yik-Cheung (Wilson) Tam 博士毕业于 CMU,现任职于微信模式识别中心,对这一参赛项目提供了指导。近日,Wilson 接受了机器之心的采访,就任务详情、模型结构、训练细节等进行了介绍。
DSTC7 Track 2 任务简介
DSTC7 Track 2「Sentence Generation」任务要求基于 Fact 和对话历史自动生成回答。该任务与传统对话系统不同的一点是,它要求利用端到端的对话系统自动读取 Fact。这就像使对话系统具备阅读理解的能力,能够基于 Fact 产生正确的答案。
竞赛提供的 Fact 可能是维基百科文章、新闻等。如下图所示,DSTC7 Track 2 提供的数据集包括来自 reddit 社区的 300 万对话问答,以及从 reddit 网页上相关的网页中提取的 2 亿个句子。
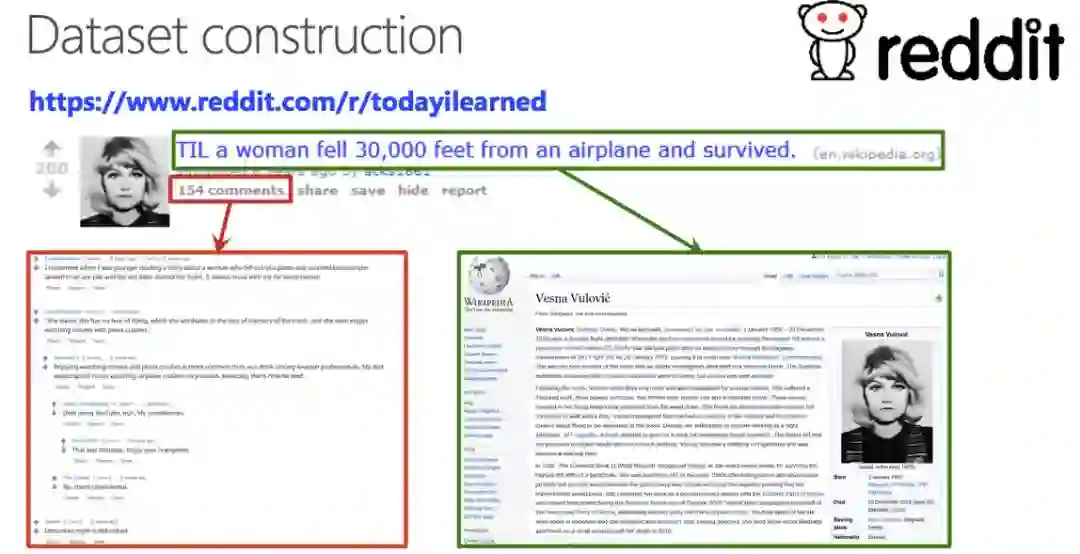
DSTC7 Track 2 竞赛的数据集构成示例。
Wilson 告诉机器之心,这个任务的难点在于:对话系统生成的答案需要与 Fact 相关,而 Fact 是非结构化数据,相对来讲比较难处理。
传统的聊天机器人没有「阅读」Fact 的机制,所以聊天回答可能会有偏差,例如:这家火锅店好不好吃?机器人回答有时会说「这家店的菜很好吃」,有时也会说「这家店的菜很差」,没有办法给出与真实点评一致的回答。
而结合了 Fact 和对话上下文信息的对话系统所生成的回答能够基于 Fact 中的真实信息作答,确保回答是有用、有信息的。
模型架构
微信模式识别中心提出一种基于注意力机制来「阅读」Fact 与对话上下文信息的方法,并利用原创动态聚类解码器,产生与 Fact 和上下文相关并且有趣的回答,在自动和人工评测都取得最佳成绩。
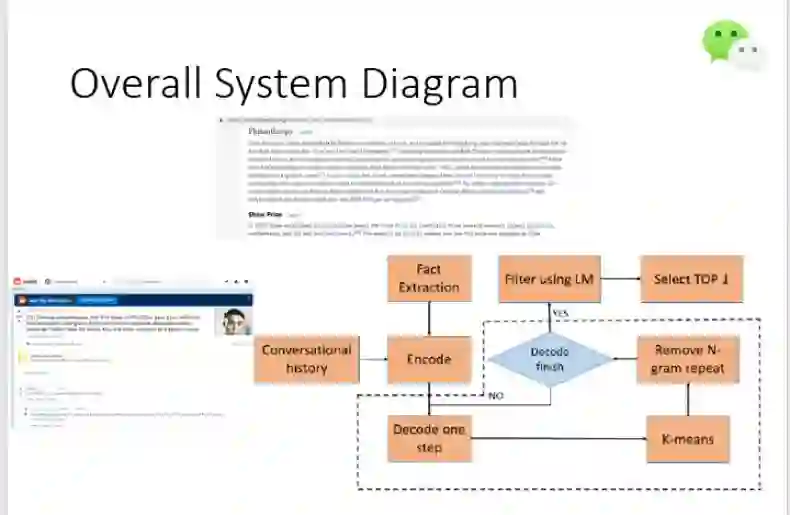
上图展示了该系统的整体架构,包括数据预处理、对对话历史和 Fact 执行端到端的编码器-解码器注意力建模、改进版解码策略。
下面我们来看一下每个模块的具体细节。
首先是数据预处理。这一步直接决定了系统的性能,Wilson 认为在所有模块中数据预处理是模型训练中最重要的模块之一。该竞赛提供的数据集中很多网页存在大量无关信息(如广告),模型训练时需要先进行数据预处理工作。
在数据清洗过程中,微信智言团队去除了对话历史数据中 reddit 网页上的无用信息(如广告、导航栏、页脚),并简化 Fact 文章内容:从相关 Fact 文章中提取与对话历史关联度高的信息,将平均 4000 单词的文章压缩至至多 500 个 word token。
若我们将 Fact 与对话历史编码为隐藏向量,再借助解码器就能将这些信息解码为对应的回答。其中如上所示编码器比较简单,直接用 BiLSTM 就行了。而如果需要得到优质回答,虚框内的解码过程就必须精炼候选回答,这也是该对话系统解决的核心问题。
为了解码为优质回答,微信团队主要利用了注意力机制、k 均值聚类和语言模型等方法,它们一方面保证集成对话历史和 Fact 信息,另一方面也最大限度地保障回答的多样性和有趣。
其中 k 均值聚类主要对 Beam search的候选回答进行聚类,这样就能识别重复或类似的回答。然而由于该模型解码器中使用了注意力机制,因此对话历史和 Fact 中的 token 可能被重复关注,从而生成重复的 N-grams。因此微信团队随后会移除重复的 N-grams,减少垃圾回答。
在经过了两次筛选之后,最终得到的 top n 个回答中仍可能包含安全却无用的回答。微信智言团队选择构建一个语言模型(LM),过滤掉无用的回答。最后,只需要选择概率最高的作为最终回答就可以了。
解码过程
微信智言团队使用双向 LSTM 分别编码对话历史和 Fact,然后对二者执行注意力机制,即解码器在每个时间步中通过注意力机制关注编码器输入的不同部分。然后利用模式预测和输出词概率估计来计算最终的单词概率分布。
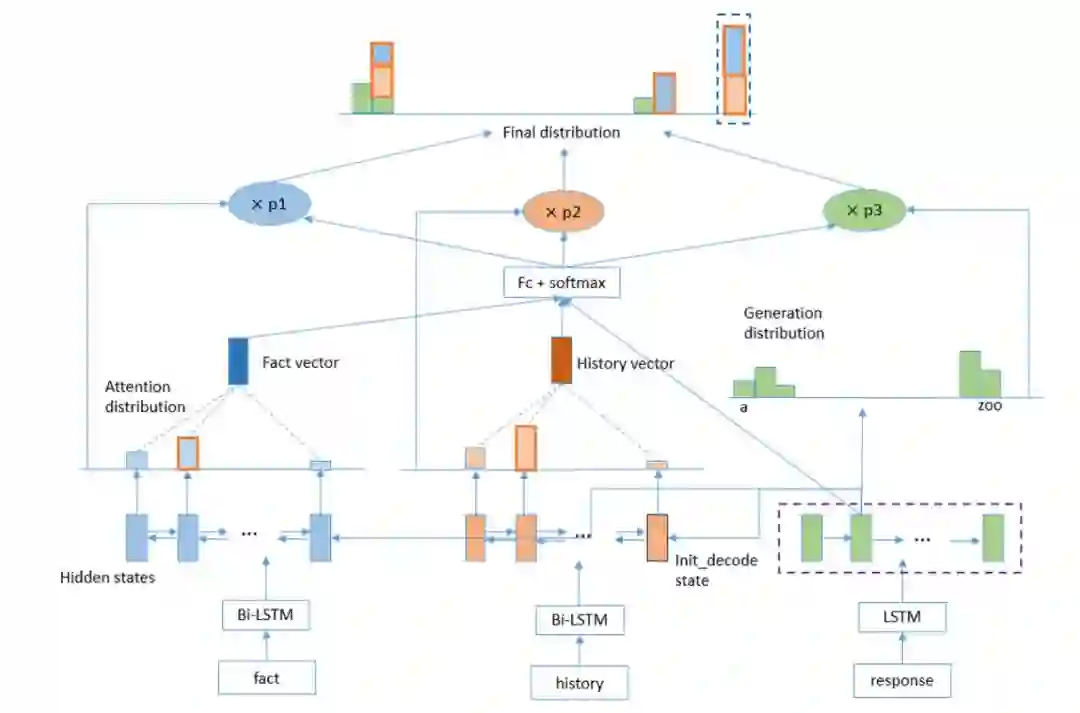
解码步流程。微信团队使用 pointer generator 模型,允许复制对话历史(H)和事实(F)。在每个解码时间步中,计算三个动作概率,即从 h 中复制一个 token,从 f 中复制一个 token,生成一个 token。最终的单词概率分布是这三个概率分布的线性插值。
传统的 seq-to-seq 模型易遇到 OOV 问题。为此,智言团队选择使用斯坦福大学 Abigail See 等人提出的 pointer-generator 方法(原用于文本摘要任务)。他们将该模型从支持两种模式(生成 token 和复制 token)扩展为支持三种模式:生成 token;从对话历史中复制 token;从 Fact 中复制 token。然后模型在每个解码步将所有可用特征级联起来,包括使用注意力机制后得到的对话历史向量和 Fact 向量、解码器隐藏状态、最后一个输入词嵌入。再使用前馈网络和 Softmax 层进行模式预测。
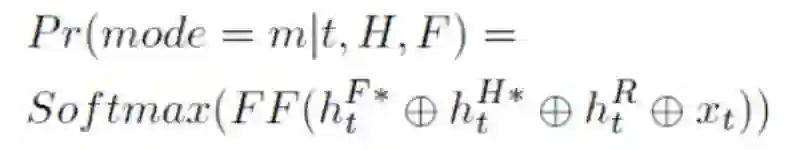
最后,模型对上述三种模式的词汇分布执行线性插值,从而计算出最终的单词概率分布,其中 m 对应于复制机制中的模式索引:
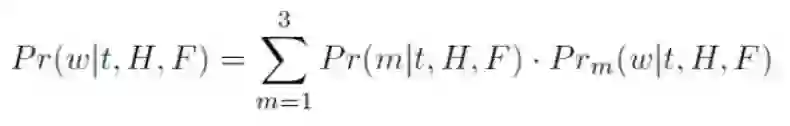
Beam search 解码策略
传统的束搜索方法主要目的是找到概率最大的假设,但对话系统中往往出现很多安全却无用的回答,很可能概率最大的句子并非是最合适、最有趣的回答。因此微信智言团队在束搜索中继承了 K 均值聚类方法,将语义类似的假设分组并进行修剪,以提高回答的多样性。
如下所示为带 k 均值聚类的束搜索,首先模型会和常见的束搜索一样确定多个候选回答,在对这些候选回答做聚类后,每一个集群都会是类似的回答。如果我们对每一个集群包含的候选回答做一个排序,那么就能抽取到更合理的候选回答,这样也会因为集群而增加回答的多样性。最后,使用语言模型对聚类得到的所有候选答案进行评分,符合自然语言表达的假设就能输出为最终的回答。

模型训练 trick
除了介绍模型之外,Wilson 还向机器之心介绍了模型训练过程中的具体技巧。
该模型基于 TensorFlow 框架构建,直接使用 pointer generator 模型的源代码,改进以适应该竞赛任务,从而在有限时间内完成比赛任务。
实现地址:https://github.com/abisee/pointer-generator
该模型训练过程中,微信智言团队最初使用了单机版 GPU,训练时间为 5 天。
Wilson 表示训练过程中遇到的最大困难是数据预处理,同时他也认为数据预处理是模型训练中最重要的模块之一。其次是束搜索,他们在束搜索中结合了 K 均值聚类,从而有效地过滤掉无用的回答,提高回答的多样性。
关于微信智言
微信智言是继微信智聆之后,微信团队推出的又一 AI 技术品牌。微信智言专注于智能对话和自然语言处理等技术的研究与应用,致力于打造「对话即服务」的理念。目前已经支持家居硬件、PaaS、行业云和 AI Bot 等四大领域,满足个人、企业乃至行业的智能对话需求。
在家居硬件方面,目前腾讯小微已经与多家厂商有合作,如哈曼•卡顿音箱、JBL 耳机和亲见智能屏等智能设备。
此外,腾讯小微定制了很多预置服务(如听歌、查天气、查股票等),但由于不同领域的需求不同,为提高可扩展性,微信智言团队为第三方开放 PaaS 平台,让任何一个开发人员甚至产品经理都可以基于自己领域的业务逻辑、业务需求在 PaaS 平台上搭建自己的应用和服务。
行业云提供面向企业客户的完整的解决方案,为企业快速搭建智能客服平台和行业任务智能对话系统。以客服系统为例子,很多公众号希望搭建对话机制,自动回答用户的问题。开发人员只需将数据上传到微信智言的平台,微信智言团队即可提供 QA 系统。此外,微信智言还提供定制服务,比如 NLP 方面的基础服务,包括分词、命名实体识别、文本摘要等,用服务的方式为客户提供技术。
据了解,微信智言已经通过智能对话技术服务于国内外数百万的用户。微信智言在 AI 技术研究上还将不断探索和提升,为各行业伙伴和终端用户提供一流的智能对话技术和平台服务——真正实现团队「对话即服务」的理念。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



