【普林斯顿-Mengdi Wang】强化学习统计复杂度,35页ppt

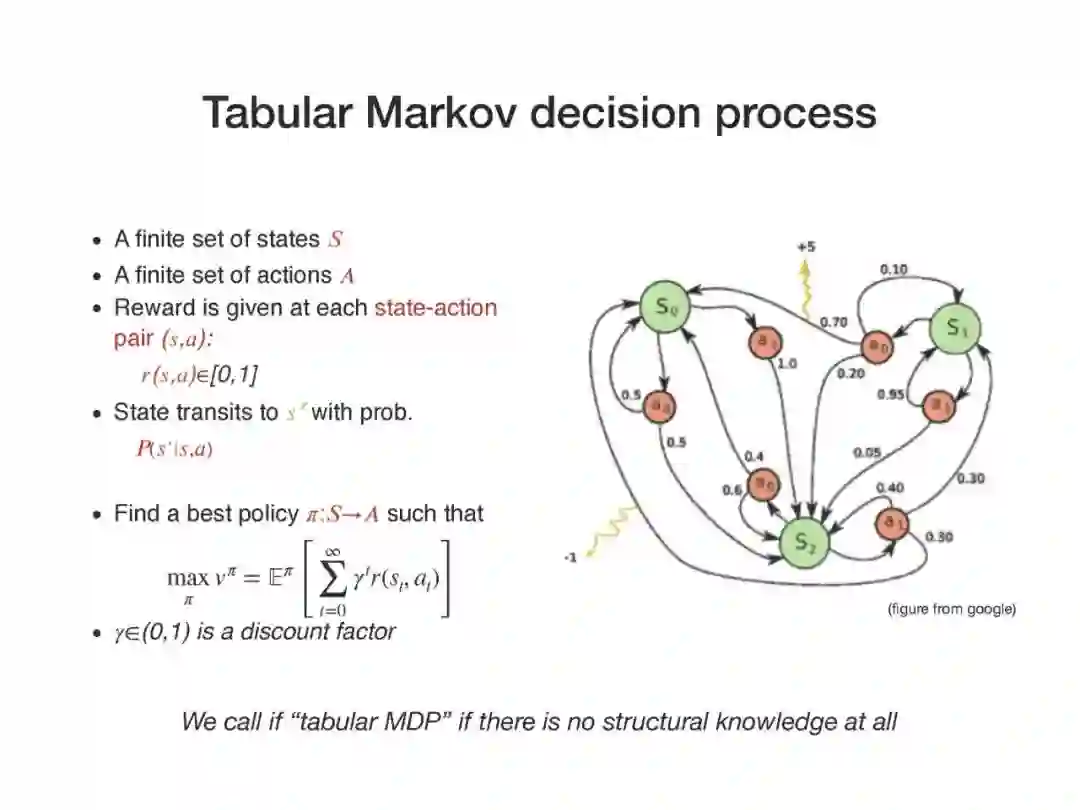
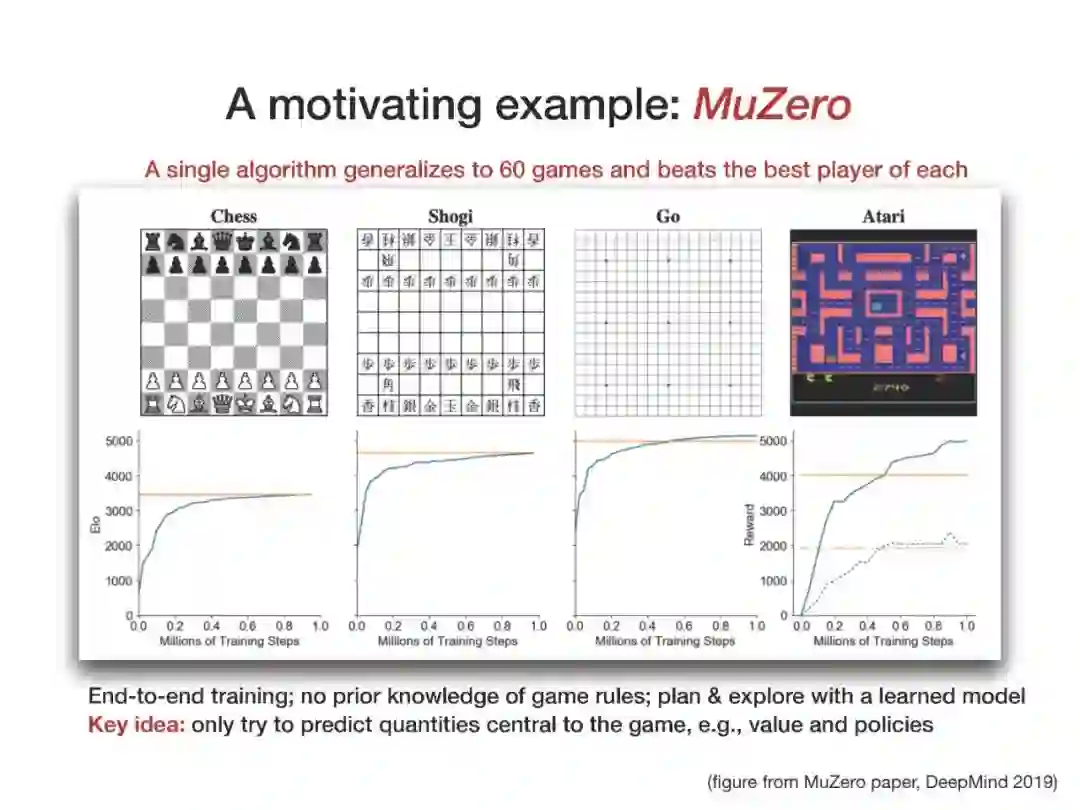
近年来,强化学习(RL)的经验研究取得了越来越多的成功。然而,关于学习能力的许多理论问题并没有得到很好的理解。例如,要学习一个好的策略,需要多少观察?马尔可夫决策过程(MDP)中函数近似在线学习的遗憾之处是什么?从未知行为策略生成的日志历史记录中,我们如何最优地估计新策略的价值?在本次演讲中,我将回顾一些最近研究这些问题的成果,如从生成模型求解MDP的最小轴最优样本复杂性,通过回归的最小轴最优非策略评估,以及使用非参数模型估计的在线RL的遗憾。
http://www.ipam.ucla.edu/abstract/?tid=16408&pcode=LCO2020





























专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RL35” 就可以获取《【普林斯顿-Mengdi Wang】强化学习统计复杂度,35页ppt》专知下载链接



登录查看更多
相关内容

Mengdi Wang,普林斯顿大学统计与机器学习中心的副教授。她还隶属于运筹学和金融工程系以及计算机科学系。她的研究重点是数据驱动的随机优化和在机器和强化学习中的应用。2013年,她获得了麻省理工学院电子工程和计算机科学博士学位。在麻省理工学院,Mengdi隶属于信息和决策系统实验室,并由Dimitri P. Bertsekas担任顾问。





相关VIP内容
相关资讯
相关论文