排序、搜索、 动态规划,DeepMind用一个神经算法学习器给解决了
机器之心报道
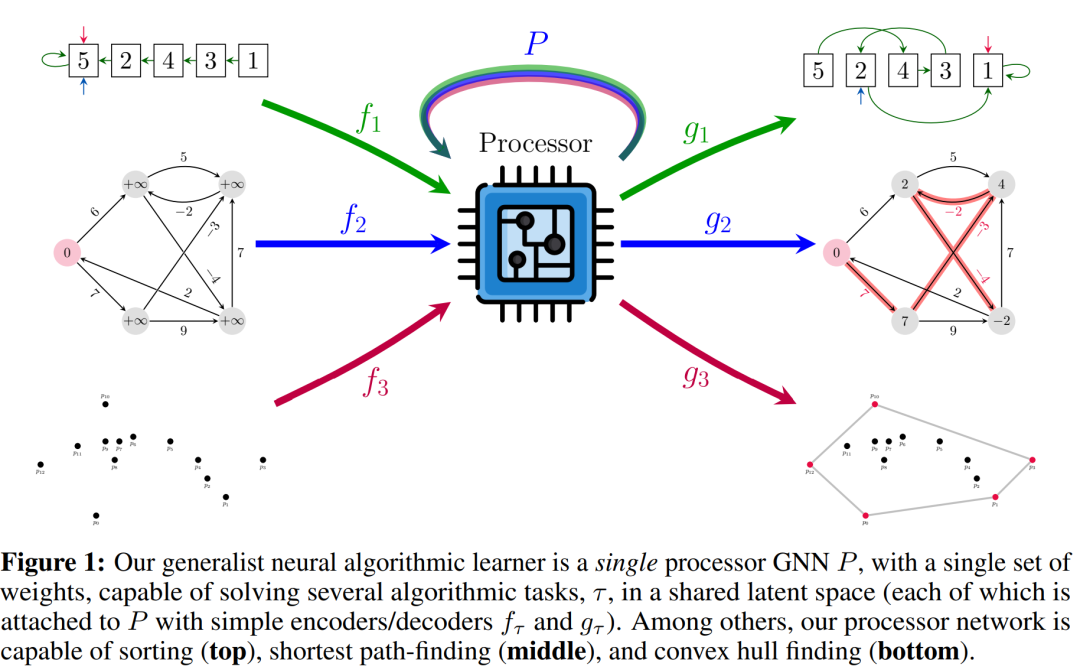
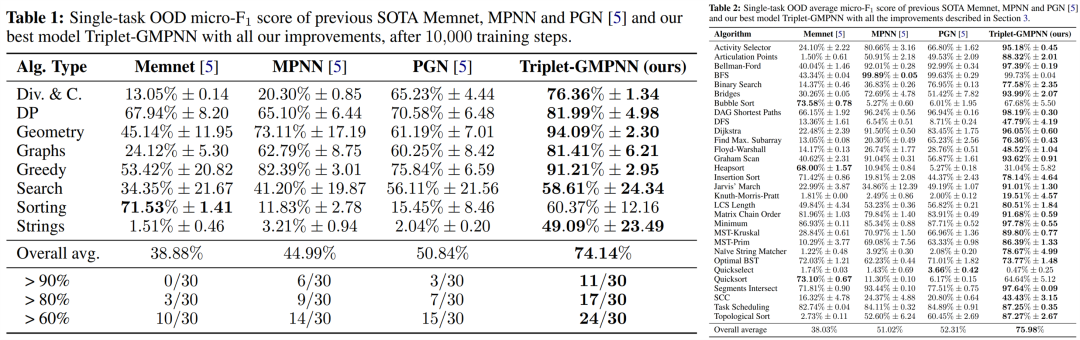
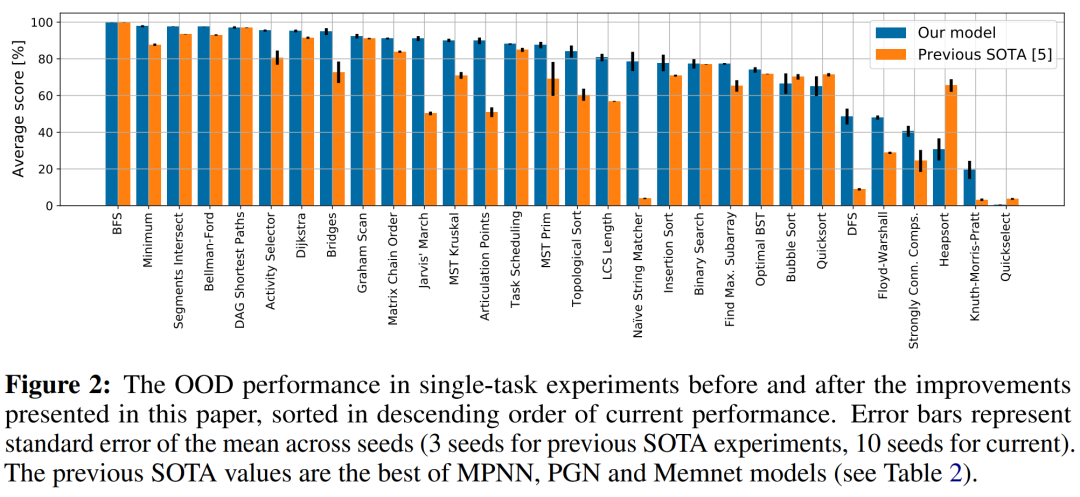
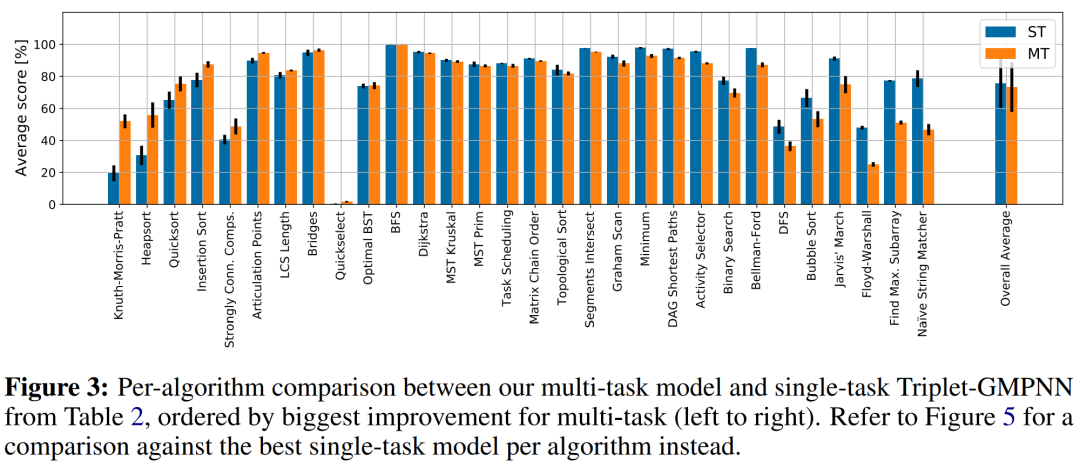
来自 DeepMind 等机构的研究者提出了一个通用神经算法学习器,其能够学习解决包括排序、搜索、贪心算法、动态规划、图形算法等经典算法任务,达到专家模型平均水平。


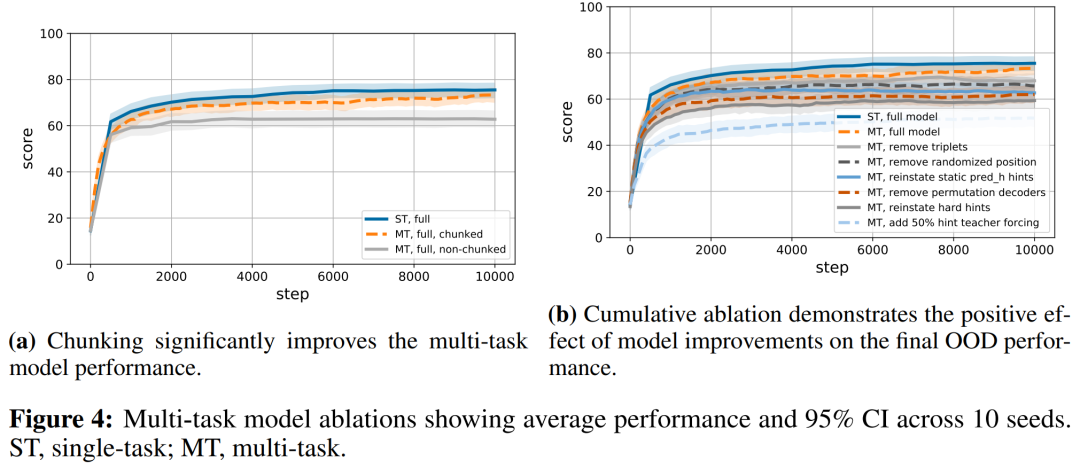
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月23日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月23日