Facebook AI 用 10 亿张来自Instagram的随机、未标注图像预训练了一个参数量达 13 亿的自监督模型 SEER,该模型取得了自监督视觉模型的新 SOTA,可能会为计算机视觉领域打开一个新篇章。
![]()
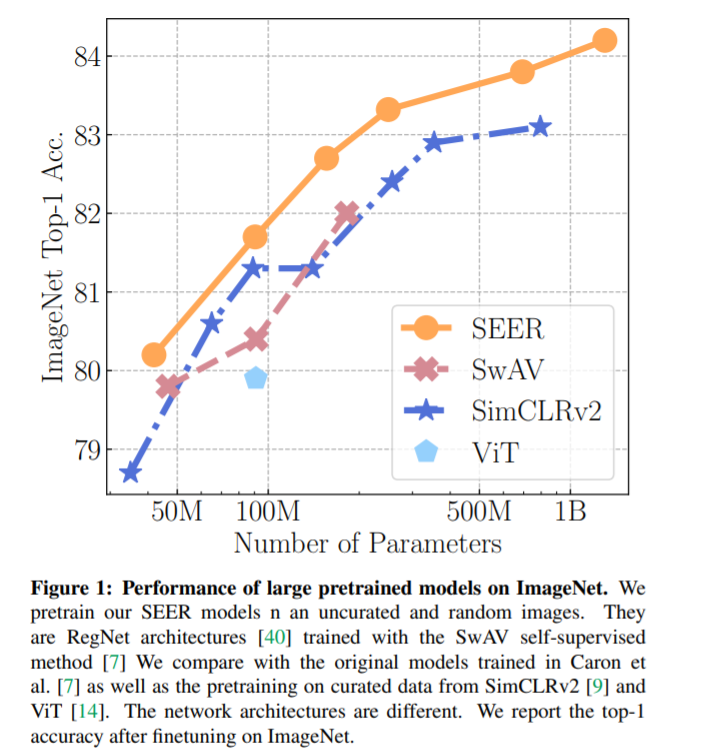
近日,Facebook 宣布了一项重要新工作:他们提出的自监督 AI 模型 SEER 能够在没有人类手动标注的情况下,从 10 亿张来自 Instagram 的随机图片中学习识别和分类照片中的主要对象。最终,该模型在 ImageNet 上的 top-1 准确率达到 84.2%,比现有的 SOTA 自监督模型高出一个百分点。
![]()
对此,Facebook AI 首席科学家、图灵奖得主 Yann Lecun 发推表示祝贺,并将显著结果进行了展示:
![]()
在大家的认知里,大多数计算机视觉模型都是从标记的数据集中学习。与此不同的是,Facebook 的模型则是通过暴露数据各部分之间的关系从数据中生成标签。
这一步被认为对有朝一日实现人类级的机器智能至关重要。
研究人员认为,AI 的未来在于做出一种自动化系统:其可以从任何给定的信息中进行推断,而不依赖于标注的数据集。给定一份文本、图像或其他类型的数据,AI 系统最好能够识别照片中的物体、读懂文本,或执行要求它完成的其他无数任务中的任何一项。
Facebook 声称,他们已经朝着这一目标迈出了一步,推出了一种名为 SEER 的计算机视觉模型。SEER 是 SElf-supERvised 的缩写,包含 13 亿个参数,可以从互联网上的任何一组随机图像中学习,而不需要标记数据。
![]()
论文地址:https://arxiv.org/pdf/2103.01988.pdf?fbclid=IwAR3sRgn_9uiOc_yZFROfEfyXylMZX5-C-yTDN_QRggHev9ai2snQkemh81w
参数一直是机器学习系统的基本组成部分,是从历史训练数据中得到的模型的一部分。AI 的未来在于是否能够不依赖于带注释的数据集,从给定的信息中进行推理。
视觉自监督是一项极具挑战性的任务。对于文本来说,语义概念可以分解为离散的词,自监督学习在自然语言处理中已经取得突破,在数量越来越多的未标记文本上训练算法已使诸如问答、机器翻译、自然语言推理等应用程序取得了进展。
但是对于图像,计算机视觉尚未完全进入自监督的学习,在现有的技术中心,模型必须决定哪个像素属于哪个概念。因此,要抓住围绕一个概念的变化,就需要查看大量不同的图像。
正如 Facebook AI Research 的软件工程师 Priya Gopal 所解释的那样,SEER 是该领域的首创。与现有的在 ImageNet 数据集上训练的计算机视觉的自监督模型相比,SEER 是第一个可以随机训练互联网上图像上的完全自监督的计算机视觉模型。
![]()
研究人员通过 Instagram 公开的 10 亿张图片进行模型训练。
经过研究,Facebook 的研究人员发现,扩展 AI 系统以处理复杂图像数据至少需要两个核心部分:
卷积网络最早是在 20 世纪 80 年代被提出的,它的灵感来自于生物过程,即模型各部分之间的连接模式类似于视觉皮层。
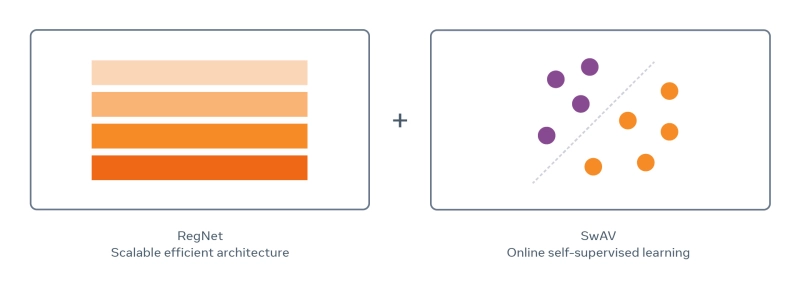
在开发 SEER 的过程中,Facebook 采用了一种称为 SwAV 的算法。SwAV 使用了一种聚类技术,可以快速地对来自相似视觉概念的图像进行分组,并利用它们的相似性,与以前最先进的自监督学习相比有了改进,同时所需的训练时间缩短为原来的1/6。
![]()
SEER 模型架构的简化示意图。图源:Facebook
PriyaGoyal 介绍说,为了训练 SEER,Facebook 的团队使用了具有 32GB RAM 的 512 块英伟达 V100 GPU,耗时 30 天完成。
训练 SEER,还需要 VISSL 通用库,它一种基于 PyTorch 的全能库,用于自监督学习, 该库是开源的。VISSL 通过整合现有的几种算法,减少了对每个 GPU 的内存需要,提高了任意一个给定模型的训练速度,促进了大规模的自监督学习。
![]()
项目地址:https://github.com/facebookresearch/vissl
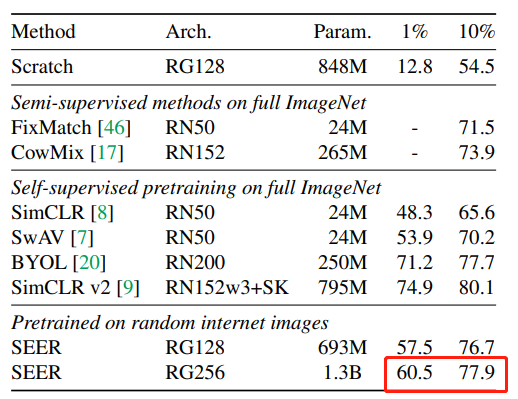
Facebook 的研究人员使用 ImageNet 数据集作评估 SEER 性能的基准,他们发现自监督模型在诸如物体检测、分割和图像分类等任务上优于最新的自监督 AI 系统。结果表明,SEER 在对 10 亿张 Instagram 公共图片进行预训练后,性能优于现有的 SOTA 自监督系统。
当使用 ImageNet 数据集中 10% 的数据进行训练时,SEER 仍然达到 77.9% 的准确率。当只使用 ImageNet 数据集中 1% 的数据训练时,SEER 的准确率为 60.5%。
![]()
这一结果表明,研究人员不需要像 ImageNet 这样的高度精选的数据集,对随机图像的自监督学习就可以产生非常高质量的模型。
当被问及 Instagram 用户是否知道自己的照片被用来训练 SEER,或有机会选择退出研究时,Goyal 表示说,Facebook 在其数据政策中告知 Instagram 账户持有人,他们上传的照片可能会被用来进行研究,同时包括 SEER。
同时这也意味着,Facebook 没有计划分享图像数据集或 SEER 模型本身。
Facebook 在博客中写道:自监督学习一直是 Facebook AI 关注的焦点,因为它使机器能够直接从大量可用的信息中学习,而不仅仅是从专门为 AI 研究创建的训练数据中学习。
自监督学习对计算机视觉的未来有着难以置信的影响,就像它在其他研究领域中的那样。
消除对人类注释和元数据的需求,可以使计算机视觉模型能够处理更大、更多样化的数据集,从随机的公共图像中学习,并可能减轻数据管理中的一些偏见。
自监督学习还可以帮助我们在图像或元数据有限的领域(如医学成像)进行专门研究。而且,无需预先进行标记,就可以更快地创建和部署模型,从而能够更快、更准确地响应快速变化的情况。
https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision/
https://venturebeat.com/2021/03/04/facebooks-new-computer-vision-model-achieves-state-of-the-art-performance-by-learning-from-random-images/
亚马逊云科技白皮书《策略手册:数据、 分析与机器学习》
曾存储过 GB 级业务数据的组织现在发现,所存储的数据量现已达 PB 级甚至 EB 级。要充分利用这 些海量数据的价值,就需要利用现代化云数据基础设施,从而将不同的信息竖井融合统一。
无论您处于数据现代化改造过程中的哪个阶段,本行动手册都能帮助您完善策略,在整个企业范围内高效扩展数据、分析和机器学习,从而加快创新并推动业务发展。
点击阅读原文,免费领取白皮书。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com