用functools.lru_cache实现Python的Memoization

Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
用functools.lru_cache实现Python的Memoization
现在你已经看到了如何自己实现一个memoization函数,我会告诉你,你可以使用Python的functools.lru_cache装饰器来获得相同的结果,以增加方便性。
我最喜欢Python的原因之一就是它的语法的简洁和美丽与它的哲学的美丽和简单性并行不悖。Python被称作“内置电池(batteries included)”,这意味着Python捆绑了大量常用的库和模块,这些只需要一个import声明!
我发现functools.lru_cache是一个很好的例子。lru_cache装饰器是Python标准库实现的易于使用的记忆功能。一旦你认识到什么时候使用lru_cache,你只需几行代码就可以快速加快你的应用程序。
我们再来看看我们的斐波那契数列示例。这一次,我会告诉你如何使用functools.lru_cache装饰器添加记忆:
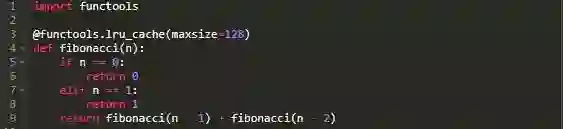
请注意我给lru_cache传递的maxsize参数是同时来限制存储在缓存中的项目数量。
我再一次使用该timeit模块来运行一个简单的基准测试,以便了解这种优化对性能的影响:

您可能想知道,为什么我们这次能够以更快的速度获得第一次运行的结果。第一次运行缓存不应该是 “冻结”的吗?
不同的是,在这个例子中,我在函数定义的时候使用了@lru_cache装饰器。这意味着这次递归调用fibonacci()也在缓存中查找。
通过@lru_cache装饰器装饰fibonacci()函数,我基本上把它变成了一个动态编程解决方案,每个子问题只需要存储一次子问题解决方案,并在下次尝试解决相同问题时从缓存中查找结果。
这只是一个例子——但我相信你开始能够看到使用memoization装饰器的美丽和强大,并且开始意识到实现一个动态算法能够带来多大的好处。
为什么你应该喜欢 functools.lru_cache
一般来说,由functools.lru_cache实现的Python的memoization比我们的专用memoize函数更全面,就像你在CPython源代码中看到的一样。
例如,它提供了一个方便的功能,允许您使用cache_info方法检索缓存统计信息:

再一次,正如你在CacheInfo输出中看到的那样,Python的lru_cache()记住了递归调用fibonacci()。当我们查看memoized函数的缓存信息时,您会发现为什么它在第一次运行时比我们的版本更快——缓存命中了34次。
正如我之前所暗示的,functools.lru_cache还允许您使用maxsize参数限制缓存结果的数量。通过设置maxsize=None你可以强制缓存是无界的,我通常会反对这样做。
还有一个typed布尔参数可以设置为True告诉缓存,不同类型的函数参数应该分开缓存。例如,fibonacci(35)和fibonacci(35.0)将被视为产生截然不同结果的不同调用。
另一个有用的功能是可以随时使用cache_clear方法重置结果缓存:

如果您想了解更多关于使用lru_cache装饰器的复杂信息,我建议您参考Python标准库文档。
总之,你永远不需要推出自己的记忆功能。Python的内置方法lru_cache()是易于使用的,更全面和经过测试的。
缓存注意事项——什么是可以被记忆的?
理想情况下,您将要记忆确定性的函数。

这deterministic_adder()是一个确定性函数,因为它总是会为相同的一对参数返回相同的结果。例如,如果您将2和3传入该函数,它将始终返回5。
将此行为与以下非确定性函数进行比较:
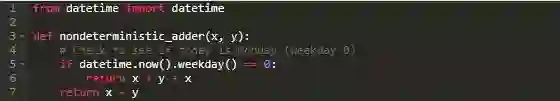
这个函数是不确定的,因为它对于一个给定的输入的输出会根据星期几而变化:如果你在星期一运行这个函数,缓存将在一周中的任何一天返回陈旧的数据。
一般来说,我发现任何更新记录或返回随时间变化的信息的函数对于记忆都是不好的选择。
或者,正如Phil Karlton所说:
计算机科学只有两件难事:缓存失效和命名事物。
——Phil Karlton
Python中的记忆:快速总结
在这篇Python教程中,您看到了memoization如何通过基于提供给它的参数缓存输出来优化函数。
一旦你记忆一个函数,它将只为你调用的每一组参数计算一次输出。第一次调用之后的每次调用都将快速从缓存中检索出来。
您看到了如何从头开始编写自己的memoization装饰器,以及为什么在生产代码中您可能想要用Python内置的lru_cache():
记忆是一种软件优化技术,它根据参数存储返回函数调用的结果。
如果你的代码符合某个标准,memoization可以是一个很好的方法来加快你的应用程序。
您可以从Python标准库中导入一个全面的memoization函数,functools模块中的lru_cache()。
英文原文:https://dbader.org/blog/python-memoization
译者:立方体的太阳




