NLP真实项目:利用这个模型能够通过商品评论去预测一个商品的销量

大数据挖掘DT数据分析 公众号: datadw
前言
由于是日语项目,用到的分词软件等,在中文任务中需要替换为相应的中文分词软件。例如结巴分词 : https://github.com/fxsjy/jieba
前提知识和术语解释
如果需要获得更多知识,请自行百度,谷歌。中文资料不是很多,有能力请阅读相关论文资料。
术语缩写
PV-DM: Distributed Memory Model of Paragraph Vectors 句向量的分布记忆模型
PV-DBOW: Distributed Bag of Words version of Paragraph Vector 句向量的分
布词袋
注意:distributed这里是区别于one-hot
distrubted 表示一个个体用几个编码单元而不是一个编码单元表示,即一个个体分布在几个编码单元上,主要是相对one-hot编码中一个编码单元表示一个个体。
one-hot representation与distributed representation学习笔记
余弦相似度
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
余弦相似度
将向量根据坐标值,绘制到向量空间中。如最常见的二维空间。
求得他们的夹角,并得出夹角对应的余弦值,此余弦值就可以用来表征,这两个向量的相似性。夹角越小,余弦值越接近于1,它们的方向更加吻合,则越相似。
单位矢量
单位向量是指模等于1的向量。由于是非零向量,单位向量具有确定的方向。一个非零向量除以它的模,可得所需单位向量。单位向量有无数个。
(矢量和向量是同一个意思,Vector,这里习惯用矢量这个词语)
gensim.matutils.unitvec(vec, norm='l2')
Scale a vector to unit length. The only exception is the zero vector, which is returned back unchanged.
Output will be in the same format as input (i.e., gensim vector=>gensim vector, or np array=>np array, scipy.sparse=>scipy.sparse).
向量加减
平行四边形定则解决向量加法的方法:将两个向量平移至公共起点,以向量的两条边作平行四边形,结果为公共起点的对角线。
平行四边形定则解决向量减法的方法:将两个向量平移至公共起点,以向量的两条边作平行四边形,结果由减向量的终点指向被减向量的终点。
image.png
向量点积
代数定义
设二维空间内有两个向量
和
,定义它们的数量积(又叫内积、点积)为以下实数:
更一般地,n维向量的内积定义如下:
点乘的结果就是两个向量的模相乘,然后再与这两个向量的夹角的余弦值相乘。或者说是两个向量的各个分量分别相乘的结果的和。很明显,点乘的结果就是一个数,这个数对我们分析这两个向量的特点很有帮助。如果点乘的结果为0,那么这两个向量互相垂直;如果结果大于0,那么这两个向量的夹角小于90度;如果结果小于0,那么这两个向量的夹角大于90度。
TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
在gensim里面有多个主题模型,TfidfModel可以直接用库来计算.
from gensim.models import TfidfModel, LsiModel, LdaModel
corpus = [dic.doc2bow(text) for text in words]
tfidf = models.TfidfModel(corpus)LSI(latent semantic index)
潜在语义索引
我们希望找到一种模型,能够捕获到单词之间的相关性。如果两个单词之间有很强的相关性,那么当一个单词出现时,往往意味着另一个单词也应该出现(同义词);反之,如果查询语句或者文档中的某个单词和其他单词的相关性都不大,那么这个词很可能表示的是另外一个意思(比如在讨论互联网的文章中,Apple更可能指的是Apple公司,而不是水果) 。
LSA(LSI)使用SVD来对单词-文档矩阵进行分解。SVD可以看作是从单词-文档矩阵中发现不相关的索引变量(因子),将原来的数据映射到语义空间内。在单词-文档矩阵中不相似的两个文档,可能在语义空间内比较相似。
SVD,亦即奇异值分解,是对矩阵进行分解的一种方法,一个td维的矩阵(单词-文档矩阵)X,可以分解为TSDT,其中T为tm维矩阵,T中的每一列称为左奇异向量(left singular bector),S为mm维对角矩阵,每个值称为奇异值(singular value),D为dm维矩阵,D中的每一列称为右奇异向量。在对单词文档矩阵X做SVD分解之后,我们只保存S中最大的K个奇异值,以及T和D中对应的K个奇异向量,K个奇异值构成新的对角矩阵S’,K个左奇异向量和右奇异向量构成新的矩阵T’和D’:X’=T’S’D’T形成了一个新的t*d矩阵。
LDA
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
请不要将自然语言处理的LDA和机器学习的LDA混淆(Linear Discriminant Analysis, 以下简称LDA)
Doc2Vec
在自然语言处理中,一个很重要的技术手段就是将文档转换为一个矢量,这个过程一般是使用gensim这个库进行处理的。
gensim官网地址
如果你需要Java版本的Doc2Vec:
https://github.com/NLPchina/Word2VEC_java
作为一个处理可变长度文本的总结性方法,Quoc Le 和 Tomas Mikolov 提出了 Doc2Vec方法。除了增加一个段落向量以外,这个方法几乎等同于 Word2Vec。和 Word2Vec 一样,该模型也存在两种方法:Distributed Memory(DM) 和 Distributed Bag of Words(DBOW)。DM 试图在给定上下文和段落向量的情况下预测单词的概率。在一个句子或者文档的训练过程中,段落 ID 保持不变,共享着同一个段落向量。DBOW 则在仅给定段落向量的情况下预测段落中一组随机单词的概率。
Token
Token在词法分析中是标记的意思。自然语言处理中,一般来说,Token代表“词”。自然语言预处理中,一个很重要的步骤就是将你收集的句子进行分词,将一个句子分解成“词”的列表。
交叉验证
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法。于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证。 一开始的子集被称为训练集。而其它的子集则被称为验证集或测试集。交叉验证是一种评估统计分析、机器学习算法对独立于训练数据的数据集的泛化能力(generalize)
least-one-out cross-validation(loocv)
假设dataset中有n个样本,那LOOCV也就是n-CV,意思是每个样本单独作为一次测试集,剩余n-1个样本则做为训练集。
优点:
1)每一回合中几乎所有的样本皆用于训练model,因此最接近母体样本的分布,估测所得的generalization error比较可靠。
2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOOCV的缺点则是计算成本高,为需要建立的models数量与总样本数量相同,当总样本数量相当多时,LOOCV在实作上便有困难,除非每次训练model的速度很快,或是可以用平行化计算减少计算所需的时间。
LinearRegression
[sklearn学习]linear_model.LinearRegression
from sklearn.linear_model import LinearRegressionfit(X, y[, n_jobs])
对训练集X, y进行训练。是对scipy.linalg.lstsq的封装
score(X, y[,]sample_weight) 定义为(1-u/v),其中u = ((y_true - y_pred)**2).sum(),而v=((y_true-y_true.mean())**2).mean()
最好的得分为1.0,一般的得分都比1.0低,得分越低代表结果越差。
其中sample_weight为(samples_n,)形状的向量,可以指定对于某些sample的权值,如果觉得某些数据比较重要,可以将其的权值设置的大一些。
代码和处理流程
语料库的准备
语料库的准备,就是将你准备好的文章库,转换为一个语料库。
你的文章一般会被保存为TaggedDocument,也就是带有标签的文档。
一篇文章对应着一个TaggedDocument对象。
TaggedDocument里面存放的是Token列表和Tag:
其中Token列表就是将文章通过分词软件分成的词语的列表,Tag这里保存着原来文章的编号。
这里的Tag也可以是文档的标题,或者任何可以代表文档的Paragraph Id。
下面这个代码中 tdocs变量表示一个TaggedDocument数组。
注意:在gensim以前版本中TaggedDocument是LabeledSentence
corpus = Doc2Vec(tdocs, dm=1, dm_mean=1,
size=300, window=8, min_count=2, workers=4, iter=20)
corpus.save(os.path.join(WORK_DIR, 'base-pv_dm.mdl'))关于这个函数的参数介绍,可以参考这里,全英文非常晦涩难懂的介绍:
https://radimrehurek.com/gensim/models/doc2vec.html
dm defines the training algorithm. By default (dm=1), ‘distributed memory’ (PV-DM) is used. Otherwise, distributed bag of words (PV-DBOW) is employed.
dm:定义了训练的算法,默认值为1,使用 ‘distributed memory’方法,不然则使用分布式的“bag of words” 方法。(dm,就是distributed memory的意思)
size is the dimensionality of the feature vectors.
size:是向量的维度,本项目维度设定是300。维度这个参数也是需要通过大量实验获得最佳的值。
dm_mean = if 0 (default), use the sum of the context word vectors. If 1, use the mean. Only applies when dm is used in non-concatenative mode.
dm_mean:如果是默认值0,则使用上下文向量的和(SUM),如果是1的话,则使用上下文向量的平均值。这个仅仅在dm使用non-concatenative的模式才发生效果。
workers = use this many worker threads to train the model (=faster training with multicore machines).
如果是多核处理器,这里可以指定并行数
iter = number of iterations (epochs) over the corpus. The default inherited from Word2Vec is 5, but values of 10 or 20 are common in published ‘Paragraph Vector’ experiments.
迭代次数:默认的迭代次数是5,但是最佳实践应该是10或者20.
min_count = ignore all words with total frequency lower than this.
如果出现频率少于min_count,则忽略
window is the maximum distance between the predicted word and context words used for prediction within a document.
window是被预测词语和上下文词语在同一个文档中的最大的距离。
语料库也是支持序列化操作的,语料库可以保存为磁盘上的文件:
Save the object to file (also see load).
fname_or_handle is either a string specifying the file name to save to, or an open file-like object which can be written to. If the object is a file handle, no special array handling will be performed; all attributes will be saved to the same file.
语料库建成之后,就可以进行一些有趣的检索了。
例如参考文档 [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型 中的句子相似度实验:
下面是sentence2vec的结果示例。先利用中文sentence语料训练句向量,然后通过计算句向量之间的cosine值,得到最相似的句子。可以看到句向量在对句子的语义表征上还是相当惊叹的。
句子相似度结果
相似检索
这里的相似度检索是指,给定一个正面的句子,然后检索和其相似度最大的句子。
当然,这里也可以指定一个负面的句子,也就是和这个句子越不相似越好。
这里有一个限制,如果正面的句子和负面的句子,进行分词之后,没有一个词语是被训练过的(被训练过的词语,是指语料库里面存在的词语),则无法进行操作。
具体在求相似度的操作之前,检索用向量需要进行一下处理。
假设positive变量是一个数组,数组里面存放着正面的Token。
corpus[token]表示token的矢量,这里对矢量进行按列求和,结果是一个和token维度一样的矢量。换句话说,就是将多个矢量合并为单个矢量。(Token矢量的求和矢量)
然后将上面那个“Token矢量的求和矢量”,和新的positive的推测矢量进行相加,获得一个新的"求相似度用矢量"。
(Negative和Positive类似)
p = np.array([ corpus[token] for token in positive ]).sum(axis=0)
p = p + corpus.infer_vector(positive, steps=20)
n = np.array([ corpus[token] for token in negative ]).sum(axis=0)
n = n + corpus.infer_vector(negative, steps=20)在语料库对象(Document Model)中有一个很有用的方法infer_vector,这个方法可以基于当前的文档模型快速,将一个文档转换(按照模型推测)成一个矢量。
infer_vector
(doc_words, alpha=0.1, min_alpha=0.0001, steps=5)
Infer a vector for given post-bulk training document.
Document should be a list of (word) tokens.
在机器学习界,有两种机器学习方式,一种是Online的,一种是Offline的。Online的方式,模型可以实时更新,新的样本会被实时进行训练,训练结果也实时反映到模型中去。Offline的方式,如果有新的样本,则需要将新老样本放在一起,重新进行训练。这里的话,模型无法进行Online的训练,所以新的样本,只是基于训练好的模型,被转换(推测 Infer,有些类似于预测Predict)为一个矢量。
相似度计算的核心方法是most_similar
most_similar
(positive=[], negative=[], topn=10, clip_start=0, clip_end=None, indexer=None)
Find the top-N most similar docvecs known from training. Positive docs contribute positively towards the similarity, negative docs negatively.
This method computes cosine similarity between a simple mean of the projection weight vectors of the given docs. Docs may be specified as vectors, integer indexes of trained docvecs, or if the documents were originally presented with string tags, by the corresponding tags.
The ‘clip_start’ and ‘clip_end’ allow limiting results to a particular contiguous range of the underlying doctag_syn0norm vectors. (This may be useful if the ordering there was chosen to be significant, such as more popular tag IDs in lower indexes.)
寻找最相似的N个文档。正面(Positive)文档向相似度贡献正面的值,负面(Negative)文档贡献负面的值。这个方法通过计算给定文章的矢量的加权平均值的余弦相似度来给出结果。可以通过矢量,被训练过的文档矢量的下标,或者原始的字符串标签来指定文档(正面或者负面文档)。
‘clip_start’ 和 ‘clip_end’则是指定了相似度检索的范围。
官方文档其实说明的不是很清楚,很多地方还是不容易理解。
topn这个参数应该没有问题,你想返回最相似的多少个,这里就指定多少即可。
对于positive和nagative的指定,首先明确一下,这里必须是一个数组,即使只有一个值,也必须是数组。
positive和nagative数组里面的值,可以是:
1.具体的文档的矢量
2.被训练过的文档的下标
3.文档的Tag字符。(本项目里面的Tag就是文档的编号)
具体到这个项目中,Positive则是上文提到的"求相似度用矢量"。
‘clip_start’ 和 ‘clip_end’则是指定了相似度检索的范围,这个一般是用来限定检索范围,例如只想在1年或者3年的资料中进行检索。
情感模型建立
MiniBatchKMeans
情感分析是建立在文档的聚类基础上的。由于计算量比较巨大,项目使用的是MiniBatchKMeans。
在有效减少计算时间的同时,也能保证计算误差在可接受范围中。
项目中使用的是Leave-One-Out Cross Validation,每次将一个样本作为测试集,一共进行n次交叉验证。
K-Means算法是常用的聚类算法,但其算法本身存在一定的问题,例如在大数据量下的计算时间过长就是一个重要问题。为此,Mini Batch K-Means,这个基于K-Means的变种聚类算法应运而生。
Mini Batch K-Means
from sklearn.cluster import MiniBatchKMeans
X_km_norm = [ unitvec(x) for x in X_km ] #转为单位向量
km_all = MiniBatchKMeans(n_clusters=8) #分为8个簇
km_all.fit(X_km_norm) #计算8个簇的质心fit(X, y=None)
Compute the centroids on X by chunking it into mini-batches.
fit拟合操作,实际上就是计算每个簇的质心。
所以说,如果簇只有一个的话,拟合的意义是求出整个数据的质心。
predict(X)
Predict the closest cluster each sample in X belongs to.
predict预测操作,是给出每个样本属于哪个簇的结果
训练样本的分类和整理
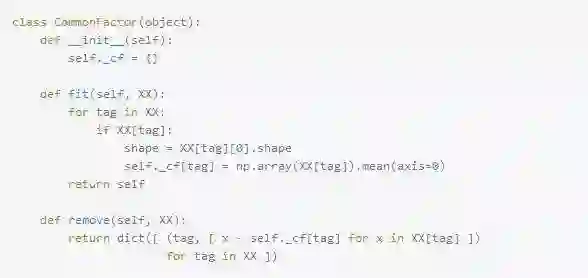
项目中将所有样本按照时间分为:1年期样本和3年期样本。同时根据其他业务规则进行了分类(分类规则需要保密)。由于收集样本的渠道不同(不同的公司,组织提供的样本数据),所有的样本还需要进行Remove Common Factor的操作:
1.样本的分类并没有按照渠道进行分类,所以这里同一收集渠道的样本,也会被分在不同的类中
2.所有分类样本,例如1年期,3年期的样本,都必须进行Remove Common Factor
3.同一样本可能同时存在于不同分类组里面,因为有些是按照时间分类的,有些是按照业务分类的,分类的维度不同。
代码的逻辑如下:
fit:XX[tag]里面的tag表示收集渠道,XX[tag]表示某个渠道的样本矢量数组:
_cf[tag]:表示某个渠道的Common Factor矢量,这里使用np.array(XX[tag]).mean(axis=0)按列求均值获得的。每一个渠道有一个Common Factor矢量。
remove代码则是将某个渠道里面所有的矢量,都剪去Common Factor矢量
(代码有删减,原来代码里面有对于未知渠道的防御代码,这里已经简化)
在我们的训练样本(document)中,有一个权重(weight)属性,这个属性是和业务有关的,也是这个项目需要进行预测的。例如,有一些用户对于商品的评论,可以看作一个训练样本(document),这个商品的销量可以看作权重属性(weight)。我们需要训练的模型就是获得一个商品评论和销量的关系模型,
利用这个模型能够通过商品评论去预测一个商品的销量。
这里假设我们的权重分为5个级别,-2(无人问津),-1(滞销),0(正常),1(畅销),2(爆款) 分别对应5种销量级别。
然后我们将所有样本通过MiniBatchKMeans分到8个不同簇里面,注意,这里的簇数和级别数是不一样的。
另外请注意,训练后的簇,其簇的编号和权重也是没有任何关系的,簇号0-7和权重-2到2,完全是两个独立的体系。
def fit(self, X, y):
X = np.array(X)
y = np.array(y).reshape(-1, 1)
size_x = X[0].shape[0]
self.km.fit([ unitvec(x) for x in X ])
#为评分Score进行数据整理
n_clusters = self.km.get_params()['n_clusters']
self.p_vec = np.zeros((n_clusters, size_x), np.float32)
self.n_vec = np.zeros((n_clusters, size_x), np.float32)
self.pn_vec = np.zeros((n_clusters, size_x), np.float32)
#簇的编号和权重没有任何关系
p_vecs = [ [] for i in range(n_clusters)]
#存放每个簇的Positive矢量
n_vecs = [ [] for i in range(n_clusters)]
#存放每个簇的Nagative矢量
for c, x, (w,) in zip(self.km.predict(X), X, y):
ext = [x] * abs(w)
#矢量 * 权重的绝对值
if w > 0:
p_vecs[c].extend(ext)
#weight[0]是正数
else:
n_vecs[c].extend(ext)
#weight[0]是负数和零
for c in range(n_clusters):
if len(p_vecs[c]) == 0:
p_vecs[c] = [ np.zeros(size_x, np.float32) ]
if len(n_vecs[c]) == 0:
n_vecs[c] = [ np.zeros(size_x, np.float32) ]
self.p_vec[c] = np.array(p_vecs[c]).mean(axis=0)
#簇的权重为正数的矢量均值
self.n_vec[c] = np.array(n_vecs[c]).mean(axis=0)
#簇的权重为负数的矢量均值
self.pn_vec[c] = unitvec(self.p_vec[c] - self.n_vec[c])
#簇的正负差,单位矢量化
return self同时,我们还需要获得一个训练的得分(score)
def predict(self, X):
if not X: return (([], []), [])
X = np.array(X)
res = np.zeros((X.shape[0], 2))
labels = self.km.predict(X)
for i, (x, c) in enumerate(zip(X, labels)):
#pn_vec[c]已经单位矢量化了,注意:p_score计算式中的是n_vec,反之亦然
#负分数 =(待预测矢量 - 簇的权重为正数的矢量均值)点积 单位矢量化簇的正负差
p_score = np.dot(unitvec(x - self.n_vec[c]), self.pn_vec[c])
#正分数 =(待预测矢量 - 簇的权重为负数的矢量均值)点积 单位矢量化簇的正负差
n_score = np.dot(unitvec(x - self.p_vec[c]), -self.pn_vec[c])
res[i] = (p_score, n_score)
return (res, labels)评价训练得分的部分使用了余弦原理,通过单位向量的点乘(点积)结果来获得相似度。注意,一定要将两个矢量都单位化,转换为模为1的矢量,这样点乘出来的结果才是余弦值。
负分数 = 矢量单位化(待预测矢量 - 簇的权重为正数的矢量均值)点积 单位矢量化簇的正负差
负分数示意图
Python语言
推荐通过网络上的 廖雪锋的Python教程 学习python语法
numpy sum
axis:求和的维。
>>> np.sum([0.5, 1.5])2.0>>> np.sum([0.5, 0.7, 0.2, 1.5], dtype=np.int32)1>>> np.sum([[0, 1], [0, 5]])6>>> np.sum([[0, 1], [0, 5]], axis=0)
array([0, 6])>>> np.sum([[0, 1], [0, 5]], axis=1)
array([1, 5])numpy mean
axis:求平均的维。
>>> a = np.array([[1, 2], [3, 4]])>>> np.mean(a)2.5>>> np.mean(a, axis=0)
array([ 2., 3.])>>> np.mean(a, axis=1)
array([ 1.5, 3.5])lambda 和浮点数
python中使用 .1 代表浮点数 0.1 或者 1. 代表浮点数 1.0。
原因是要保证结果的精度,防止程序自动强制转换。
score = lambda X, y: 1.-((y-X)**2).sum()/((y-y.mean())**2).sum()percentile
幾つかの数値データを小さい順に並べたとき、小さい方から数えて全体のX%に位置する値をXパーセンタイルと言います。
(数值按照从小到大进行排列,从小的数字开始计算,全体数字的X%的位置,数值是多少)
例えば10人のクラスがあるとして、各生徒のテストの点数が[40, 50, 60, 70, 75, 80, 83, 86, 89, 95]だったとします。
その時、下から95%に位置する点数(逆に言うと上位5%に位置する点数)が何点なのか示すものが95パーセンタイルになります。
以下、numpyを使ったサンプルです。
>>> import numpy as np>>> a = np.array([40, 50, 60, 70, 75, 80, 83, 86, 89, 95])>>> np.percentile(a, 95) # 95パーセンタイルを求めます(逆に言うと上位5%に位置する点数)92.299999999999997# 95パーセンタイルは約92.3点であることがわかります>>> np.percentile(a, 30) # 30パーセンタイルを求めます(逆に言うと上位70%に位置する点数)67.0# 30パーセンタイルは67.0点であることがわかりますnumpy的mask
numpy的高级特性,可以进行数据的筛选。下面的代码没有完全看懂,猜测了一下意思:
n_clusters 是一个数字,则c也是一个数字。P[下标]也应该是一个数字,这个下标数字是由C==c这个条件来获得的。在C这个数组里面存放的就是数字,C[x] == c的时候,x则是需要求出的下标,P[C==c],则实际上就是P[x].当然,这里x应该是多个值,则P[x]的结果也是一个数组。
def score(self, X, y):
score = lambda X, y: 1.-((y-X)**2).sum()/((y-y.mean())**2).sum() #predict的结果为 (res, labels)
#res[i] = (p_score, n_score)
#则最后的形式是[[p_score, n_score],[labels]]形式
# P 为 p_score,N 为 n_score,C为label
P, N, C = zip(*self.predict(X))
P = np.array(P)
N = np.array(N)
C = np.array(C)
y = np.array(y).reshape(-1, 1)
n_clusters = self.km.get_params()['n_clusters']
res = np.zeros((n_clusters+1, 1))
#==使用了numpy的mask特性
for c in range(n_clusters):
res[c] = score(P[C==c]-N[C==c], y[C==c])
res[-1] = score(P-N, y)
return res人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注

