腾讯优图鄢科:以AI技术助力内容安全 促进互联网环境健康发展 | AICon2021

近年来,伴随着深度学习技术的成熟以及计算机算力的增长,人工智能技术在各行业的业务场景中实现了快速的普及和落地。在人工智能技术进一步落地实践的背景下,将会为行业带来什么样的变革与技术创新,成为了大家共同关心的问题。
11 月 25 至 26 日,以“AI 商业化下的技术演进”为主要研讨方向的 AICon 全球人工智能与机器学习技术大会北京站顺利召开。据了解,AICon 北京站设置了 “人工智能前沿技术”、“计算机视觉实践”、“智能金融技术与业务结合”、“认知智能的前沿探索”等 14 个技术专题,并邀请了 50 余位行业资深专家,分享其最新 AI 技术创新和应用实践。
本次大会,腾讯优图实验室内容安全算法负责人鄢科受邀出席了“计算机视觉实践”技术专题的研讨,并通过《腾讯优图在视觉内容理解领域的研究与实践》的主题演讲,分享了腾讯优图在内容安全领域中的研究成果和应用实例,提供了技术创新和落地实践的经验和思路。
随着互联网的高速发展,网络内容不论是呈现形式还是信息体量都迎来了爆发式的增长。而在这些增长的背后,也隐藏着海量的色情、血腥等不良和有害信息,不仅危害互联网平台的内容生态,更可能导致安全问题。在内容安全问题不断加剧的背景下,AI、大数据等信息技术能够辅助传统人工审核,在内容安全领域中发挥重要作用。
基于此,腾讯优图依托在视觉 AI 技术上的研究成果,打造了包含涉黄、广告、违法违规等在内的、一站式内容安全的解决方案。凭借支持一体化接入、需求定制化、详实的标签体系和自动化训练平台等优势,该解决方案能够在社区、UGC、直播、点播等场景中辅助人审,从而提高内容安全审核的效率。
而在推动视觉 AI 技术落地业务场景的过程中,腾讯优图也归纳和总结了视觉内容理解的技术特点和挑战:
首先,内容安全审核被广泛应用在海内外不同国家的各个行业和业务之中,不同业务的审核场景千差万别;以游戏直播场景为例,该场景一般是二次元模态的游戏画面,但由于海外手机的像素质量和国内不一样,很多都是一些模糊不清低质图像,场景多样严重考验 AI 算法的稳定性和泛化能力。
其次,针对于同一个内容,不同客户的标准定义差别很大,针对客户需求制定能够实现全覆盖的标签和标准体系,对技术完备提出了较高的要求。
最后,多样化的内容审核场景也要求方案具备多标签识别、目标检测、画面细粒度、OCR 等技术,无法通过一个简单的技术点或是通用模型解决所有问题,对模型能力的精细化和快速优化也提出了较高的要求。
目前,腾讯优图在内容安全领域主要研究方向包括细粒度识别、多标签识别、目标检测、目标定位、对抗攻击、图像描述等方向。
旋转目标检测:
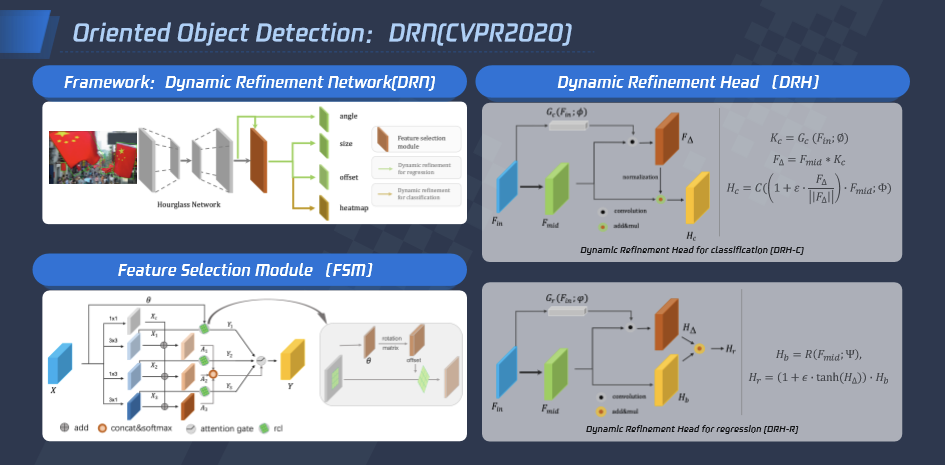
目标检测在内容理解领域发挥了重要作用,大多数场景的目标检测都是常见的正框检测,但在遥感地图、密集商品、自然场景的文本检测等场景需要用到多角度目标检测技术,腾讯优图提出 DRN 网络来提高多角度检测效果。
首先在特征选择模块 FSM 中设计了自适应感受野调整模块,使得模型能够根据目标形状,旋转角度自适应调整感受野,缓解单一的感受野与多变的目标之间的矛盾。然后分别针对分类与回归任务设计了动态修正分类器 DRHC 与动态修正回归器 DRHR,使得模型同时学习样本无关的一般性知识及样本敏感的特殊性知识,赋予模型依据样本自适应调整的能力。此外,该工作还设计了统一的动态修正网络,使得模型可以端到端的学习旋转目标检测任务。
弱监督目标定位:
全监督目标检测因其出色的效果一直广泛应用于内容理解的各个任务中,但其标注成本很高,有统计显示按照弱监督要求只标注 image-level 的类别标签不标注 bbox,标注速度可以比 bbox level 的标注提高数倍。
为了提高效率降低成本,腾讯优图弱监督目标检测和定位上展开深入研究。该工作提出目标结构保持才是弱监督定位的关键问题,首先设计受限激活模块缓解模型的结构信息弥失的问题,之后重新定义了高阶相似性的概念并基于此提出了自相关图生成模块,显著提高了目标定位精度。
受限激活模块如主要包括两个部分,首先通过计算每个特征位置在类别响应图上的方差分布得到粗略的伪 mask, 用以区分前背景;然后利用 Sigmoid 操作对类别响应特征图进行归一化,之后利用提出的受限激活损失函数引导模型关注目标前景区域。在自相关图生成模块,将 CAM 的定位结果当做种子节点,分别提取前景与背景的相似性图,通过聚合前背景相似性图得到最终的定位结果。

多标签识别:
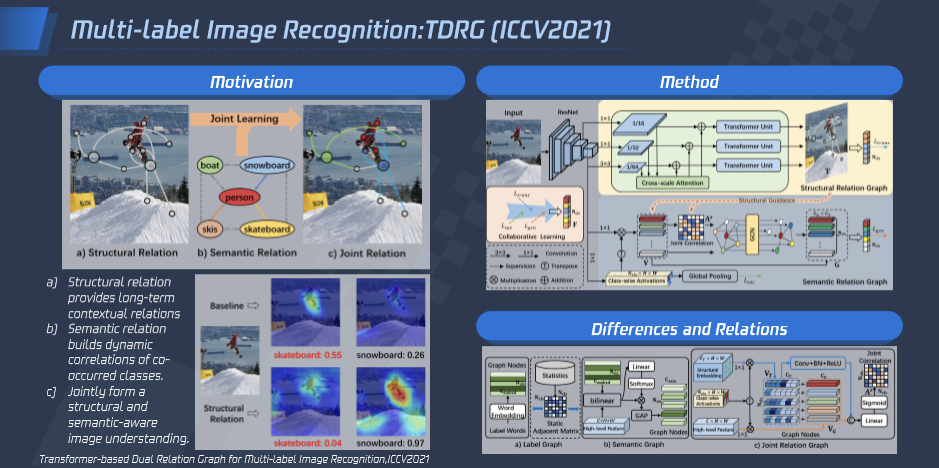
多标签识别是内容理解场景中非常通用的技术问题,主要目标是同时识别一幅图像中的多个对象。现有的大多数工作主要通过学习标签共现依赖关系增强特征的语义表达。腾讯优图提出除共现依赖以外,空间依赖也是影响多标签识别的重要因素。
由此,腾讯优图提出基于 Transformer 的双路互补关系学习框架来联合学习空间依赖与共现依赖。针对空间依赖,使用跨尺度 Transformer 建模长距离空间上下文关联,具体来说,对 CNN 提取到的特征经过跨尺度增强后得到空间信息更加丰富的图像特征,然后利用共享权重的 transformer 层来建模图像特征中的空间依赖,根据空间关联提升类别响应。针对共现依赖,我们提出类别感知约束和空间关联引导,基于图神经网络联合建模动态语义关联,最后联合这两种互补关系进行协同学习得到鲁棒的多标签预测结果。
细粒度识别:
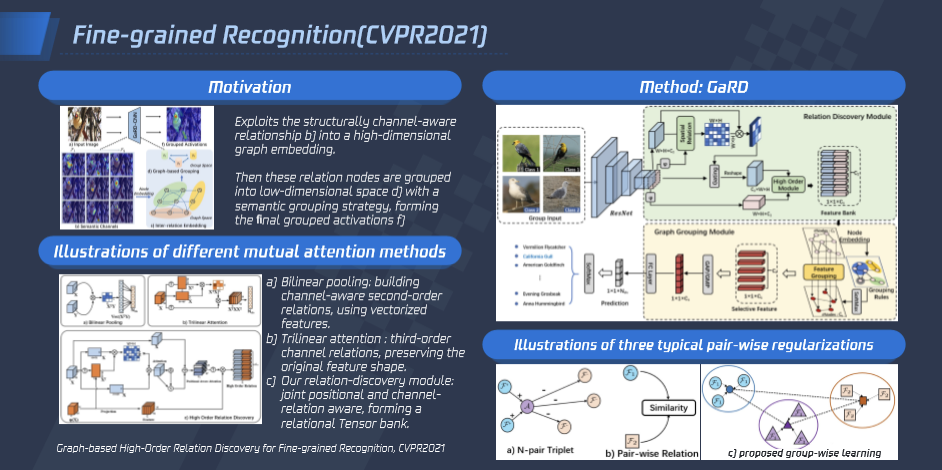
细粒度图像识别是计算机视觉研究热点问题,其旨在将表观高度近似的同类物体区分为不同的子类。现有的细粒度识别算法通常使用通道间的高阶特征来获取区分性表征。其忽略了空间位置关系和不同语义特征间的相互关联,在复杂背景或类间距较小情况下误判较显著。腾讯优图针对这一问题,创新性地提出一种特征高阶关系建模的方法,通过挖掘特征间的空间与语义关联来建模高阶关系,合并其中的相似关系得到区分度高的特征。
该方法首先通过特征间语义和位置感知来构建高维特征库(feature bank),同时进行正则化约束。其次提出一种基于图的语义分组方法 (graph grouping),将高维特征映射到低维空间中,保留其中高区分性特征。在训练过程中,设计了一种分组学习策略 (group-wise learning),对特征聚类中心进行约束。通过以上三个模块的协作,此方法可学习到细粒度类别间更丰富的区分性信息。此外在训练过程中,还设计一种平衡分组策略,将不同样本按照中心化采样,进行分组约束迭代,使图像特征倾向于聚类原型,抑制异常样本的表征。
目前,腾讯优图视觉内容理解的实际应用场景包括 ACG 敏感内容识别和图像情感倾向分析等多类。
1.ACG 敏感内容识别:
在内容安全领域中,由于 ACG 场景风格与通用场景之间的差异较大,导致通用模型在动画、漫画领域中的识别能力相对较弱,容易出现大量的漏过和误判。为解决此类问题,腾讯优图提出渐进式领域自适应方法,首先统计源域和目标域的特征分布,用 MMD 缩短通用特征与 ACG 特征分布间的距离,然后提出动态渐进式学习策略 PAS,由易到难进行学习,降低迁移难度。最后通过半监督学习快速迭代模型,得到面向 ACG 场景专用识别模型。
在实际应用中,ACG 模型相较于通用模型,显著提升了召回率,极大程度上提升了该场景审核的效率和效果。
图像倾向分析:
现阶段的内容审核工作中,审核系统对于出现人民币等敏感元素的图片都会做召回处理。但实际场景中,大量出现人民币元素的图片是正常的,这无形中为人审环节增加了很多负担。
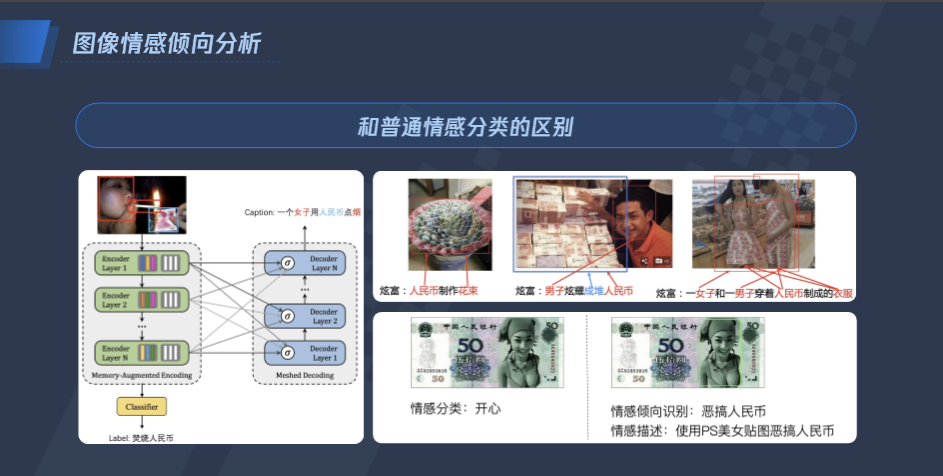
为此,腾讯优图基于图像描述(Image Caption)技术,提出了一套图像倾向分析框架,可精准识别恶意的敏感元素,相比一般的元素检测识别方案,可显著降低相关能力人审成本。
在 12 月 26-27 日,ArchSummit 全球架构师峰会(北京站)即将落地北京,本次会议我们也配置了微服务治理之基础架构、微服务治理之业务架构、架构师成长、客户端架构设计、数据库与存储技术、云原生技术应用、质效度量体系和测试平台建设、低代码实践与应用、领域驱动设计方案落地、高并发架构设计等专题,届时欢迎你的参与。


你也「在看」吗?👇





