大规模计算时代:深度生成模型何去何从

编辑 | 丛末
人工智能的核心愿望之一是开发算法和技术,使计算机具有合成我们世界上观察到的数据的能力, 比如自然语言,图片等等。
-
每当我们建立一个模型来模仿这种能力时,该模型就称为生成模型 (Generative Models)。 如果该模型涉及深度神经网络,则该模型是深度生成模型(Deep Generative Models, 简称 DGMs)。
作为深度学习中自我监督学习 (self-supervised learning)技术的一个分支,DGM特别专注于刻画数据的生成过程。这篇文章回顾了DGM的历史,定义和现状,并分享最新的一些研究结果。最终希望启发大家去思考一个共同的主题:如何在大规模预训练时代推进或应用深度生成模型。
生成模型(Generatitve Models)在传统机器学习中具有悠久的历史,它经常与另外一个主要方法(判别模型,Discriminative Models)区分开。我们可以通过一个故事学到它们有何不同:有两兄弟,他们具有不同的特殊能力,一个具有深入洞察事物内在的能力,而另一个善于学习所见事物之间的差异。在故事里,前者代表生成模型,而后者代表区分模型,他们的特点总结为:
生成模型:专注于使用某种内部机制来表征实际观察的事物的分布;
区分模型:专注于在不同事物之间建立决策边界。
随着深度学习的兴起,生成模型通过和深度神经网络的结合,逐渐形成了一个新的家族:深度生成模型。他们这个家族有个共同的特点,就是利用神经网络来模拟数据生成的过程。这样以来,复杂而神秘的数据生成过程就被某个参数量一定的神经网络的给拟合出来了,加之训练这个DGM的数据库本身大小也是确定的,这里就会出现一个潜在的通用技巧。引用2016年一篇OpenAI博客上的话来说:
我们用作生成模型的神经网络具有许多参数,这些参数远小于我们在训练它用的数据量,因此模型会被迫使发现并有效地内化数据的本质,从而以生成数据。
简单地做一些数学上的刻画。作为来自真实数据分布




所有DGM都具有上述相同的基本目标和通用技巧,但是它们处理问题的思路方式不同。根据OpenAI的分类法,我们这里考虑三种流行的模型类型:VAE,GAN,自回归模型 (autoregressive models),详见下表:
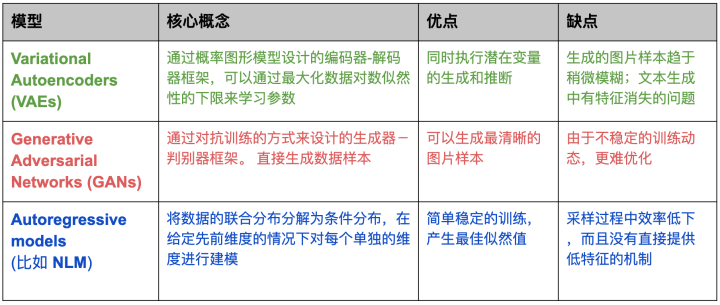
表格1:不同深度学习模型的对比。不同类别标记为不同的颜色,它们对应的变种也用相同的颜色展示在下面的图1里。
多年来,我们在发展DGM及其理论原理方面做出了许多努力,DGM在较小的规模上现在已得到相对较好的理解。上面提到的DGM技巧保证模型在温和条件下可以正常运行: 

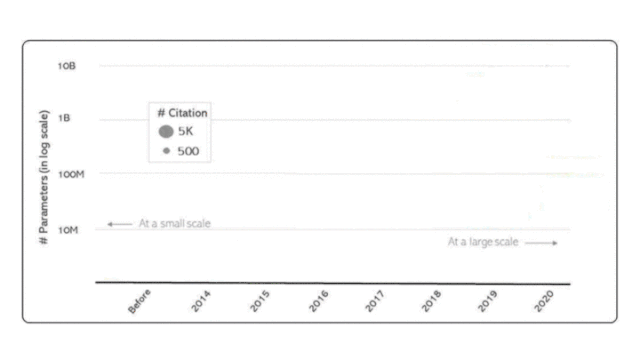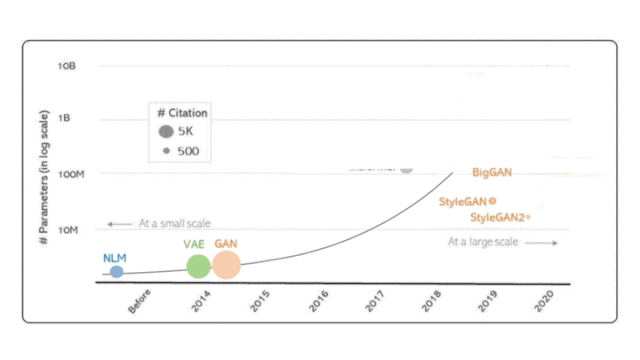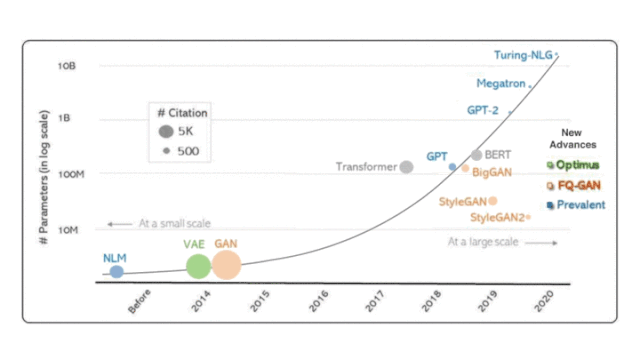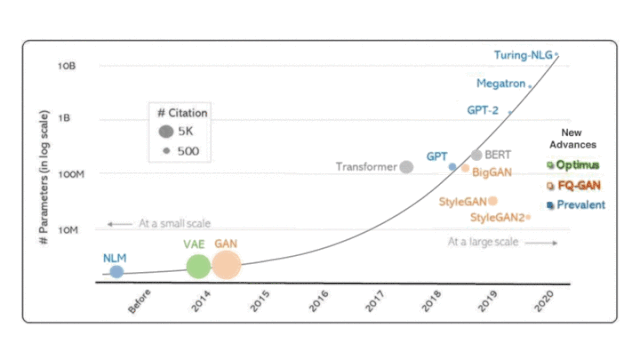
图1:我们考虑了三种流行的深度生成模型类型:蓝色的自动回归模型(神经语言模型,或NLM),绿色的可变自动编码器(VAE)和橙色的生成对抗网络(GAN)。Transformer和BERT作为重要的文献参考点也包括在图里,但并不作为本文考察重点。图里最右边的三个新模型,是在大规模计算的时代下我们自己的工作。
上图总结了深度生成模型随时间的简短演变历史,通过两种指标来衡量:
模型大小(参数数量)
科学影响力(迄今为止的引用次数)
OpenAI的研究人员认为,生成模型是最有前途的方法之一,可以潜在地实现用计算机了解世界的目标。沿着这些思路,他们在2018年开发了Generative Pre-training (GPT)),在各种未标记文本的语料库上训练了自回归神经语言模型(neural language model, 简称NLM),随后对每个特定任务进行了区分性微调,从而显着提高了多项任务的性能语言理解任务。在2019年,他们将这一想法进一步扩展到15亿个参数,并开发了GPT-2,该模型显示了近乎人类的语言生成能力。随着更多的计算,英伟达的Megatron 和微软的Turing-NLG 继承了相同的想法,并将其参数分别扩展到83亿和170亿。
以上研究表明,NLM已取得了巨大进步(大大增加
机遇:如果我们把DGM做到大规模,是否能和现有的预训练模型一争高低?
挑战:现有DGM是否需要进行修改,以使其在此大规模的数据上有效地工作?
应用:反过来做,DGM是否可以帮助预训练?
接下来,我们用自己的研究结果作为例子,来对这些问题一一进行回答。
Optimus:我们开发了第一个大规模的VAE模型,展示出比起主流的语言建模预训练模型(比如BERT和GPT-2)的一些优势 。【论文】【代码】
FQ-GAN:作为以分布匹配为目标的GAN,在大数据上训练尤其困难,我们提出FQ作为一种有效的解决技巧,展示出在BigGAN, StyleGAN, U-GAT-IT这些主流模型上的性能提升。【论文】【代码】
Prevalent:我们使用生成模型合成大量多模态数据,并在此基础上进行自我监督学习,预训练了第一个通用的视觉语言导航系统,在三个相关任务上取得SoTA。【论文】【代码】
读者可以直接跳到相应的章节阅读具体内容。
1、Optimus: 在语言建模领域的机遇
预训练语言模型(Pre-trained language models ,简称PLM)在各种自然语言处理任务方面取得了实质性进展。PLM通常经过训练,可以根据海量文本数据中的上下文预测单词,并且可以对学习的模型进行微调以适应各种下游任务。PLM通常可以扮演两个不同的角色:编码器(例如 BERT 和 Roberta)和解码器(例如 GPT-2 和 Megatron)。有时,两个任务都可以在一个统一的框架中执行,例如UniLM, BART 和 T5。尽管这些已取得了显着的性能改进,但是它们缺乏一种在紧凑的特征空间对结构进行显式建模的功能,因此很难从整体句子的语义级别控制自然语言的生成和表示。
原理上来说,变分自动编码器(VAE)经过有效训练后,既可以作为强大的生成模型使用,又可以作为自然语言的有效表示学习框架来使用。VAE把句子表示在低维的特征空间中,通过操纵句子对应的特征向量表示来轻松操纵句子语义上的变化(比如使用可解释的向量运算符等),操作后的向量作为整体语义的概要,来指导句子的生成。例如,基本款的VAE就提供了一种由先验分布来指定的特征平滑的正则化。下图展示了VAE操纵句子变换的过程。
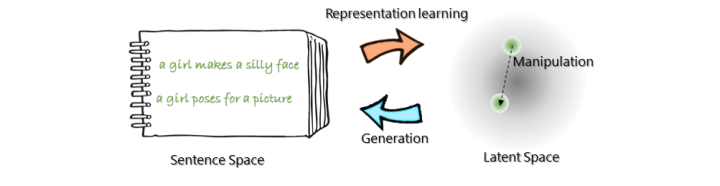
图2:在语义空间组织和操纵句子。
我们来利用下面的公式对比,详细了解下自回归模型和VAE在建模句子时候的不同。对于长度为 





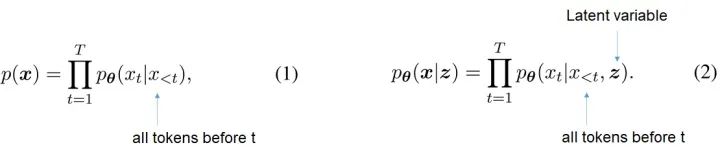
尽管VAE具有扎实的理论优势,但当前语言建模中使用的VAE经常使用较小的网络体系结构(例如两层LSTM)来构建模型, 这大大限制了模型的容量,导致性能欠佳。这种浅层VAE,在当下的海量数据的时代,就尤其显得不适配----因为上文提到的DGM的通用技巧会奔溃: 
如果扩大VAE模型,并将其用作新的预训练语言模型(PLM),将会发生什么?因此,我们开发了Optimus(Organizing sentences with pre-trained modeling of a universal latent space),第一个针对自然语言的大规模深度隐变量模型,该模型使用句子级别的(可变)自动编码器在大型文本语料库进行了预训练, 从而将由符号表达的自然语言组织在一个连续且紧凑的特征空间里,把对句子的语义操作转换为对向量的算术操作。
Optimus体系结构如下图(a)所示。为了易于培训,我们使用BERT初始化编码器,并使用GPT-2初始化解码器。[CLS]位置输出的特征用于转化我们感兴趣的语义空间
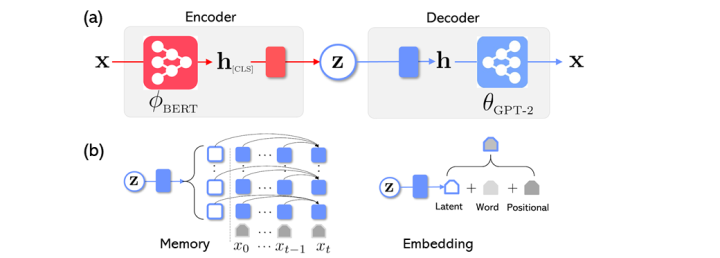
图3:(a) Optimus体系结构,由编码器和解码器组成,(b) 向编码器注入特征向量的两种方式
作为一种新型的PLM,Optimus显示出一些有趣的结果,具有与现有PLM相比的独特优势:
语言建模----我们考虑了四个数据集,包括Penn Treebank ,SNLI, Yahoo, 和 Yelp语料库,并对每个PLM进行微调。由于VAE独特的先验分布中编码的语义知识,Optimus在三个数据集上展示了低于GPT-2的困惑度(perplexity)。另外,和文献中所有的自然语言上的VAE相比,Optimus显示了更好的特征学习性能,以相互信息(mutual information)和活动单位(active units)衡量。这意味着预训练本身就是缓解特征消失问题的有效方法。
引导性的语言生成----由于潜在变量
的存在,Optimus具有从语义级别控制句子生成的独特优势(GPT-2在此方面是不适用的)。这种可控制性给用户提供了一种新的方式来和语言生成模型进行交互。在图4中,我们展示了两种使用一些简单的潜在矢量操纵来说明这种想法:(1)通过潜在矢量的算术运算进行句子的类比写作:
,(2)两个句子之间的过度:
,其中
。对于更复杂的潜在空间的句子操纵功能,我们考虑对话响应生成(dialog response generation),风格化响应生成(stylized response generation)和标签条件语句生成(label-conditional sentence generation)这些任务。Optimus在所有这些任务上都比现有方法具有优势。




图4:(a)句子类比生成;(b)句子插补。蓝色表示生成的句子。
低资源下的语言理解----与BERT相比,Optimus学习的特征空间更平滑,特征模式更分离(请参见图4a和4b)。在冻结主干网络且仅更新分类器的微调设定下(feature-based setting), Optimus能够比BERT获得更好的分类性能和更快的适应性,因为它允许Optimus维护和利用到在预训练中学习到的语义结构。图4c显示了在Yelp数据集上每个类别带有不同数量的标记样本的结果,Optimus在低计算场景(feature-based setting)中显示了更好的结果。我们在GLUE数据集上可以观察到类似的比较。
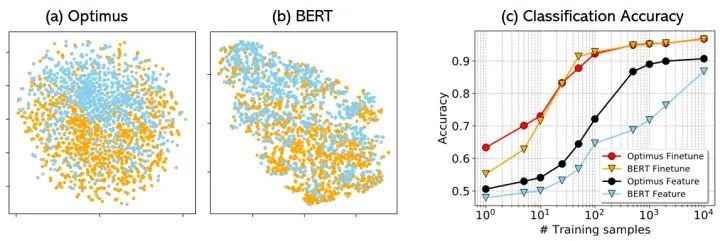
图5:(a)和(b)分别展示了使用tSNE对Optimus和BERT进行特征空间可视化的结果。具有不同标签的句子以不同的颜色呈现。(c)不同数量的带有标签数据的结果
感兴趣更多详细结果,请查看我们的论文,在Github上试试Optimus的代码。
2、FQ-GAN: 图像生成中的挑战
Generative Adversarial Networks (GAN)是一种流行的图像生成模型。它由两个网络组成:一个用于直接合成模拟样本的生成器(generator),以及一个用于区分真实样本 ( 

特征匹配 ( Feature matching ) 一项有理论支撑的训练GAN的原理技术, 它将GAN的数据分布匹配问题转换为鉴别器特征空间中的特征分布匹配问题。这要求从整体伪造样本和整体真实样本中算得的特征统计量要相似,比如,一阶或二阶矩。但实际实现上,这些特征统计量是使用连续特征空间中的小批量数据(mini-batch)来估计的。随着数据集变得更大和更复杂(例如,更高的分辨率),基于小批量的估计质量变得很差。因为在固定大小的批量去估计更大的数据集,估计方差很大。对于GAN来说,这个问题尤为严重,因为生成器的伪造样本分布在训练中总是在变化,这对于大规模扩展GAN模型提出了新的挑战。
为解决此问题,我们在论文“Feature Quantization Improves GAN Training”中提出了鉴别器的特征量化(FQ)的技术,将特征表示量化在一个字典空间里,而非它原来的连续空间。FQ-GAN的神经网络架构如图6a所示。相比较于原来的GAN模型, 我们仅仅需要把FQ作为一个新的层,嵌入到区分器中某一层或者多层。FQ-GAN将原来的连续特征限制在一组学习好的字典的元素上;而这里的字典元素,则一直代表着当前真假样本最具代表性的特征。
由于真假样本只能从有限的词典元素中选择其表示形式,因此FQ-GAN间接执行特征匹配。这可以使用图6b中的可视化示例进行说明,其中将真实样本特征 


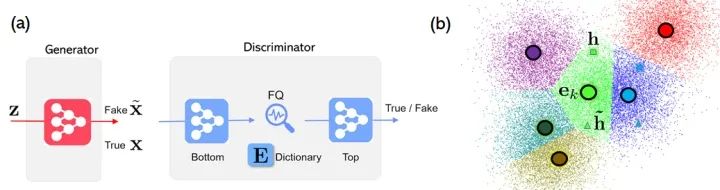
图6:(a)FQ-GAN架构:我们的FQ可以作为标准GAN区分器中的新层来添加进去。(b)用字典查找来实现隐式特征匹配。相同颜色的小散点们表示可以量化为相同中心(大圆圈)的连续特征;在经过FQ之后,真实特征(正方形)和伪特征(三角形)会共享相同的中心。
我们所提出的FQ技术可以轻松地应用到现有的GAN模型中,且在训练中的计算开销却很小。大量的实验结果表明,FQ-GAN可以在各种任务上大幅度提高基线方法的图像生成质量,我们尝试了在9个基准数据集上的3个代表性GAN模型:
BigGAN 图像生成。 BigGAN是由Google DeepMind于2018年推出的,它是我们知道的最大的GAN模型。我们在以下三个数据集上将FQ-GAN与BigGAN进行了比较:CIFAR 10, CIFAR 100 和 ImageNet。这三个数据集依次具有越来越多的图像类别或者样本。就FID值(该指标衡量了真假数据之间的特征统计差异)而言,FQ-GAN始终优于BigGAN超过10%。我们的方法还改进了Twin Auxiliary Classifiers GAN,这是在NeurIPS 2019上出现的GAN的一个新变体,它特别适合细粒度的图像数据集。
StyleGAN 人脸合成。StyleGAN,是由NVIDIA在2018年12月推出的,该模型可以生成特别逼真的高分辨率人脸面部肖像的图像(想象下 Deep Fake 的潜在影响)。StyleGAN是基于Progressive GAN进行改进的,但它引入更多使研究人员可以更好地控制特定的视觉功能的机制。我们在FFHQ数据集上进行比较,图像分辨率从 32x32 一直到 1024x2014。结果显示FQ-GAN收敛速度更快,并产生更好的最终性能。感受一下:
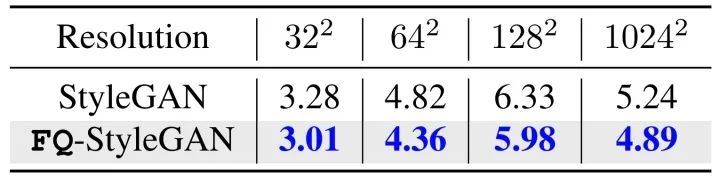
表格2:FQ对StyleGAN的提升。在FFHQ数据集上不同分辨率下的 FID-50k scores (越低越好)。

图7:FQ-StyleGAN的生成的1024x2014的样例图片 (在8块V100上训练一周多就为看这些美女帅哥?)。
U-GAT-IT 图像转化。U-GAT-IT 是刚出现在 ICLR 2020上的最先进的图像样式转换(image style transfer)方法。在五个基准数据集上,我们看到FQ在很大程度上改善了量化性能,并显示了更好的人类感知评估结果。
如果你想使用FQ改善你的GAN模型,那赶紧尝试我们在GitHub上的代码,并查看我们的论文去了解更多细节。
3、Prevalent: 在视觉和语言导航任务上的应用
通过对图像和语言的语义的进一步了解,自然而然的下一步就是使机器在理解多模态输入后能采取行动以完成指定任务。为了实现此目标,我们碰到的一项基本挑战就是 “遵循自然语言的指示并让机器能够学习如何在视觉环境中导航” (vision-and-language navigation,简称VLN)。在理想情况下,我们希望一次性地训练一个通用的机器,它可以迅速适应多个不同的下游任务。
为此,我们提出了Prevalent,第一个遵循预训练和微调范式的VLN算法。如图8a所示,我们将预训练的数据样本表示为三元组(图像-文本-动作),并以两个目标对模型进行预训练:掩盖语言建模(masked language modeling)和动作预测 (action prediction)。由于预训练不涉及最终的下游学习目标,因此这种自我监督的学习方法通常需要大量的训练样本才能发现多模态数据的内部本质,从而很好地泛化到新任务上。
在我们的研究中,我们发现该子领域最大的训练数据集R2R仅包含104,000个样本,这比用于自然语言(language pre-training)还有多模态(vision-and-language pretraining )的那些子领域的预训练数据集要小一个数量级。这会导致以下尴尬的情况:一方面由于训练数据不足而使得预训练质量不理想,另一方面,使用人工注释来收集此类样本又非常昂贵。
在我们的论文 “Towards Learning a Generic Agent for Vision-and-Language Navigation via Pre-training” 中, 我们尝试了用深度生成模型来合成这些多模态数据,很幸运地发现这样做居然是有效果的。我们首先训练一个自动回归模型(相当于VLN领域的 Speaker 模型),该模型可以根据R2R数据集上的机器人的轨迹(一系列的动作和视觉图像的序列)生成语言指令。然后,我们使用模拟器(Matterport 3D Simulator)收集大量的最短轨迹,并使用生成模型合成它们相应的指令。这产生了6,482,000个新的训练样本。通过图8b中比较了这两个数据集,我们看到合成数据占了98.4%的预训练数据。我们的Prevalent就是预训练在这样的组合数据集上。
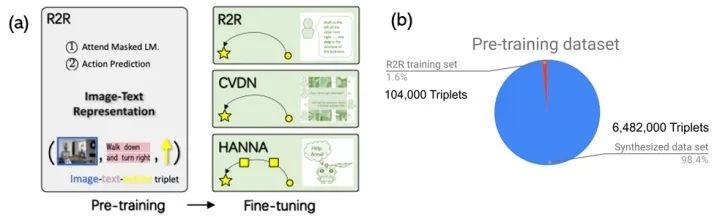
图8:(a)模型学习的流程:在大量增强的R2R数据集中对机器进行预训练,并在三个下游任务上进行微调;(b)预训练数据集的百分比:98.4%的合成数据和1.6%的真实数据。
预训练好模型后,我们尝试了三个下游导航任务的微调,包括房间到房间的导航(R2R),和两个域外任务:对话指导的视觉导航(CVDN)以及和人类交互更多的导航任务(HANNA)。我们的算法在这三个任务上都达到了最先进的水平。这些结果标明,深度生成模型合成的样品可用于预训练,并且可以提高其模型的通用性。有关更多详细信息,请阅读我们的CVPR 2020论文“Towards Learning a Generic Agent for Vision-and-Language Navigation via Pre-training”。我们在GitHub上发布了Prevalent的预训练模型,数据集和代码。我们希望它可以为将来在视觉和语言导航这个子领域的自我监督预训练方面的研究奠定坚实的基础。
从上面的示例中,我们已经看到了在大规模训练时代,深度生成模型的的机遇,挑战和应用。下面我们谨慎地探讨下,这个时代背景下,深度生成模型未来可以开展的工作:
落地实用:随着我们继续推进这些模型并扩大其规模,我们可以期望DGM去合成高保真的图像或语言样本。这本身可能会在各个领域中会被真正地落地实用起来,例如艺术图像合成或面向任务的对话。
技术组合:这三种深度学习模型类型的界限会很容易变得模糊,研究人员可以结合不同模型的优势进行进一步的改进。小规模的设置里已经有非常多融合的工作,那大规模的情况,是否会有新的技术难题呢?借助已经被极度大规模化的autogressive models, 其它模型类别是否会因此受益呢?
自我监督学习:这个我个人最感觉兴趣的方向。(1) 利用生成模型提升自我监督学习的性能,比如 Electra 。(2) 作为自我监督学习的一个分支,DGM本身在基础工作上的进展也会在更加广泛的意义上影响自我监督学习 。比如,上文交代的DGM的通用技巧,更深入一层的思考,其实也是自我监督学习的通用技巧:有限参数量的神经网络,在学会生成(部分)观察到的数据的中对其过程进行编码,这必须要求模型本身可以有效地学习并发现掌握数据的本质,从而推理出对许多下游任务都通用的良好表达。