今日 Paper | PolarMask;时间序列;面部表情编辑;ELECTRA 等

目录
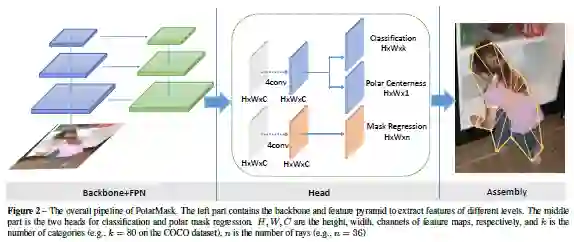
PolarMask:一阶段实例分割新思路
特例化的时间序列模型特征重要度度量
Cascade EF-GAN:以局部焦点进行渐进式面部表情编辑
ELECTRA:预训练文本编码器 作为鉴别器而不是生成器
FOAL:用于心脏运动估计的快速在线自适应学习
PolarMask:一阶段实例分割新思路
论文名称:PolarMask: Single Shot Instance Segmentation with Polar Representation
作者:Enze Xie
发表时间:2019/12/24
论文链接:https://arxiv.org/pdf/1909.13226.pdf
推荐原因
本文的研究意义:
在本文中,作者介绍了一种新的单实例分割方法——PolarMask,该方法完全卷积且网络结构简单,可以最大限度的将其嵌入到大多数现成的检测方法中使用。通过PolarMask方法可以将实例分割问题转化为研究中心分类和极坐标距离回归的轮廓预测问题。此外,作者还对处理高质量采样的中心示例和密集距离回归优化进行了探索,发现采用该方法可以显着提高性能并简化训练过程。最后作者通过实验证明了提出的PolarMask框架在实例分割任务中是明显优于其他的方法。

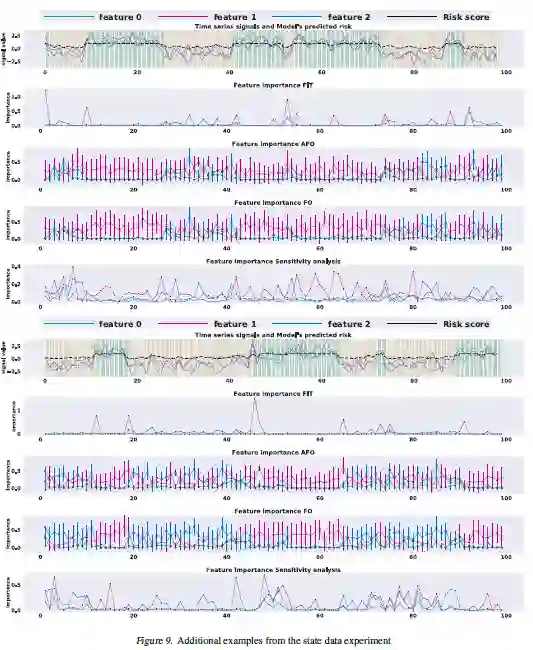
特例化的时间序列模型特征重要度度量
论文名称:What went wrong and when? Instance-wise Feature Importance for Time-series Models
作者:Sana Tonekaboni /Shalmali Joshi /David Duvenaud /Anna Goldenberg
发表时间:2020/3/5
论文链接:https://arxiv.org/abs/2003.02821
推荐原因
1 核心问题:
本文主要研究的是探究在时间序列模型中,何种特征在哪个时间段对预测结果影响最大的问题。
2 创新点:
在在时间序列分析中,大部分特征重要度的分布模型都把注意力放在全局级别的重要度中,但是,全局级别的的重要度可能无法产生对个体样本实例的局部解释,此类模型不利于用户理解某个特例的模型结果。本文的工作则聚焦在时间序列中例子级别的特征重要度,提出了一个通用的时间序列观测重要度度量方法。该方法在个体历史数据的分布中采样,基于合理的反事实上的积分,去估计了在观测前后预测分布的差异来度量重要度。根据该方法,可以得到在不同时间上的相关特征复杂度,并且可以得到每个特征最有影响力(重要度最高)的特定时间点。
3 研究意义:
(1)本文将得到的重要度度量,和基于梯度的解释,注意力机制以及其他基准在模拟和临床ICU数据的结果进行了比较,说明了本文的方法可以生成最精确的结果(2)同时,本模型还具有价格低廉,通用的特点(3)并且可以使用在任意复杂时间序列模型和预测器中(4)最后,本文提出的设计是唯一一个对时间序列中每一个特征都可以确定其重要时间点的方法。
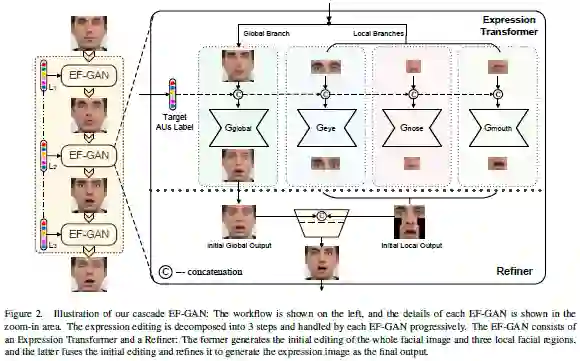
Cascade EF-GAN:以局部焦点进行渐进式面部表情编辑
论文名称:Cascade EF-GAN: Progressive Facial Expression Editing with Local Focuses
作者:Wu Rongliang /Zhang Gongjie /Lu Shijian /Chen Tao
发表时间:2020/3/12
论文链接:https://arxiv.org/abs/2003.05905
推荐原因
这篇论文被CVPR 2020接收,考虑的是面部表情编辑的问题。
生成对抗网络易于在表达密集区域周围产生伪影和模糊,且在处理诸如从愤怒到笑的转换时,常会引入不希望的重叠伪影。为克服这些局限性,这篇论文提出级联表情聚焦生成对抗网络(Cascade Expression Focal GAN,Cascade EF-GAN),能以局部表情为重点进行渐进式面部表情编辑。引入局部焦点后,Cascade EF-GAN可以更好保留与身份相关的特征和眼睛、鼻子、嘴巴周围的细节,从而进一步减少生成的面部图像中的伪影和模糊。此外,通过将大型面部表情转换分成多个小面部表情,这篇论文还设计了一种新的级联转换策略,这有助于抑制重叠的伪像并在处理大间隙表情转换时产生更逼真的编辑效果。在两个公开面部表情数据集上进行的大量实验表明,Cascade EF-GAN具有出色的面部表情编辑性能。

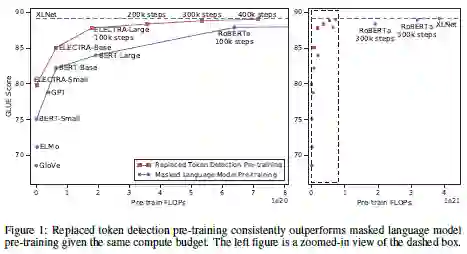
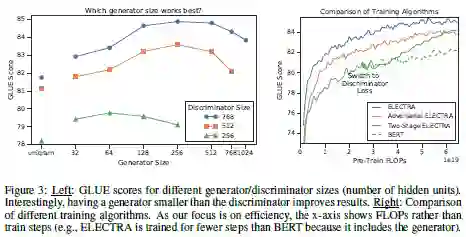
ELECTRA:预训练文本编码器 作为鉴别器而不是生成器
论文名称:ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
作者:Kevin Clark /Minh-Thang Luong /Quoc V. Le /Christopher D. Manning
发表时间:2020/9/24
论文链接:https://openreview.net/pdf?id=r1xMH1BtvB
推荐原因
本文重点:随着bert的爆发,现在在NLP领域众多的预训练语言模型已经成为当下的热点,这篇论文完成了类似的工作
创新点:在NLP领域拥有语言模型 (LM)和掩码语言模型(MLM),其中BERT就是掩码语言模型。而本论文提出了一种新的任务replaced token detection,它像语言模型,又像掩码语言模型。它像MLM一样训练一个双向模型,也像LM一样学习所有输入位置。它使用伪token替换真实的token。首先使用一个生成器预测句中被mask掉的token,接下来使用预测的token替代句中的[MASK]标记,然后使用一个判别器区分句中的每个token是原始的还是替换后的。
研究意义:他超过了之前的BERT和XLNET模型。
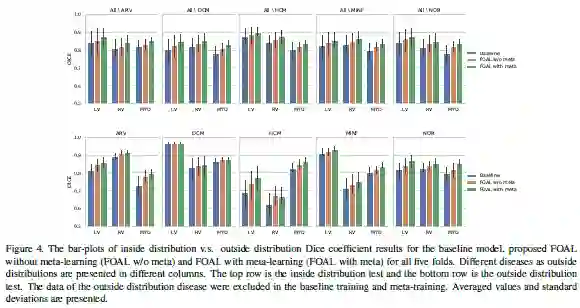
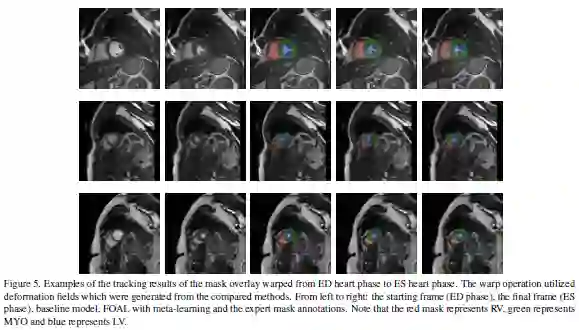
FOAL:用于心脏运动估计的快速在线自适应学习
论文名称:FOAL: Fast Online Adaptive Learning for Cardiac Motion Estimation
作者:Yu Hanchao /Sun Shanhui /Yu Haichao /Chen Xiao /Shi Honghui /Huang Thomas /Chen Terrence
发表时间:2020/3/10
论文链接:https://arxiv.org/abs/2003.04492
推荐原因
这篇论文被CVPR 2020接收,考虑的是心脏运动估计的问题。
心脏MRI视频动态估计对于评估人体心脏的解剖结构和功能至关重要。在临床部署中,由于训练和测试数据集之间分布不匹配,深度学习模型的性能急剧下降。这篇论文提出了一种新的快速在线自适应学习(Fast Online Adaptive Learning ,FOAL)框架,包括一种基于在线梯度下降的优化器,该优化器由元学习器进行优化。元学习器使在线优化器能够执行快速而强大的调整。这篇论文通过在两个公共临床数据集上的广泛实验评估了所提方法。结果表明,与离线训练的跟踪方法相比,FOAL准确性更高。