机器学习面试题精讲(二)

上一讲链接:机器学习面试题精讲(一)
4. GBDT
GBDT(Gradient Boosting Decision Tree)又叫 MART(Multiple Additive Regression Tree)。是一种迭代的决策树算法。
4.1 DT:回归树 Regression Decision Tree
GDBT 中的树全部都是回归树,核心就是累加所有树的结果作为最终结果。只有回归树的结果累加起来才是有意义的,分类的结果加是没有意义的。
GDBT 调整之后可以用于分类问题,但是内部还是回归树。
这部分和决策树中的是一样的,无非就是特征选择。回归树用的是最小化均方误差,分类树是用的是最小化基尼指数(CART)
4.2 GB:梯度迭代 Gradient Boosting
首先 Boosting 是一种集成方法。通过对弱分类器的组合得到强分类器,他是串行的,几个弱分类器之间是依次训练的。GBDT 的核心就在于,每一颗树学习的是之前所有树结论和的残差。
Gradient 体现在:无论前面一颗树的 cost function 是什么,是均方差还是均差,只要它以误差作为衡量标准,那么残差向量都是它的全局最优方向,这就是 Gradient。
4.3 Shrinkage
Shrinkage(缩减)是 GBDT 算法的一个重要演进分支,目前大部分的源码都是基于这个版本的。
核心思想在于:Shrinkage 认为每次走一小步来逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易防止过拟合。
也就是说,它不信任每次学习到的残差,它认为每棵树只学习到了真理的一小部分,累加的时候只累加一小部分,通过多学习几棵树来弥补不足。
具体的做法就是:仍然以残差作为学习目标,但是对于残差学习出来的结果,只累加一小部分(step* 残差)逐步逼近目标,step 一般都比较小 0.01-0.001, 导致各个树的残差是渐变而不是陡变的。
本质上,Shrinkage 为每一颗树设置了一个 weight,累加时要乘以这个 weight,但和 Gradient 没有关系。
这个 weight 就是 step。跟 AdaBoost 一样,Shrinkage 能减少过拟合也是经验证明的,目前还没有理论证明。
4.4 GBDT 适用范围
GBDT 可以适用于回归问题(线性和非线性),相对于 logistic regression 仅能用于线性回归,GBDT 适用面更广;
GBDT 也可用于二分类问题(设定阈值,大于为正,否则为负)和多分类问题。
4.5 GBDT 和随机森林
相同点:
都是由多棵树组成;
最终的结果都由多棵树共同决定。
不同点:
组成随机森林的可以是分类树、回归树;组成 GBDT 只能是回归树;
组成随机森林的树可以并行生成(Bagging);GBDT 只能串行生成(Boosting);
对于最终的输出结果而言,随机森林使用多数投票或者简单平均;而 GBDT 则是将所有结果累加起来,或者加权累加起来;
随机森林对异常值不敏感,GBDT 对异常值非常敏感;
随机森林对训练集一视同仁权值一样,GBDT 是基于权值的弱分类器的集成;
随机森林通过减小模型的方差提高性能,GBDT 通过减少模型偏差提高性能。
TIPs:
1. GBDT 相比于决策树有什么优点
泛化性能更好!GBDT 的最大好处在于,每一步的残差计算其实变相的增大了分错样本的权重,而已经分对的样本则都趋向于 0。这样后面就更加专注于那些分错的样本。
2. Gradient 体现在哪里?
可以理解为残差是全局最优的绝对方向,类似于求梯度。
3. re-sample
GBDT 也可以在使用残差的同时引入 Bootstrap re-sampling,GBDT 多数实现版本中引入了这个选项,但是是否一定使用有不同的看法。
原因在于 re-sample 导致的随机性,使得模型不可复现,对于评估提出一定的挑战,比如很难确定性能的提升是由于 feature 的原因还是 sample 的随机因素。
5. Logistic 回归
5.1 LR 模型原理
首先必须给出 Logistic 分布:
u 是位置参数,r 是形状参数。对称点是 (u,1/2),r 越小,函数在 u 附近越陡峭。
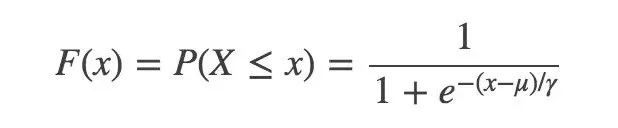
然后,二分类 LR 模型,是参数化的 logistic 分布,使用条件概率来表示:
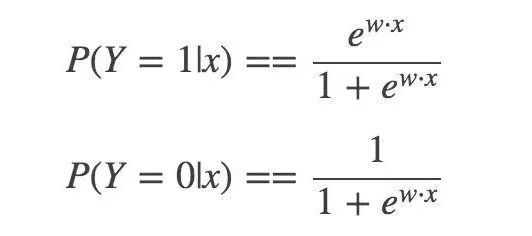
然后,一个事件的几率(odds):指该事件发生与不发生的概率比值:
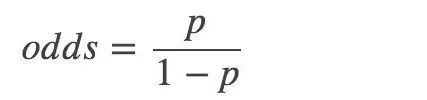
对数几率:
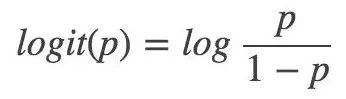
那么对于逻辑回归而言,Y=1 的对数几率就是:
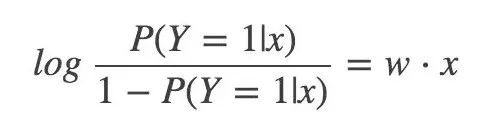
最终,输出 Y=1 的对数几率是输入 x 的线性函数表示的模型,这就是逻辑回归模型。
5.2 参数估计
在统计学中,常常使用极大似然估计法来估计参数。即找到一组参数,使得在这组参数下,我们数据的似然度(概率)最大。
似然函数:
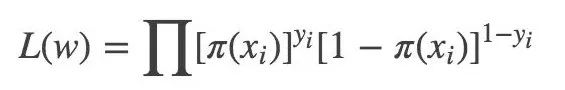
对数似然函数:
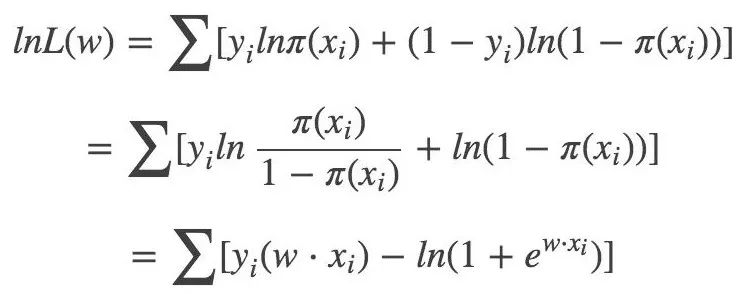
对应的损失函数:
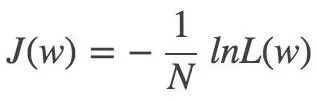
5.3 最优化方法
逻辑回归模型的参数估计中,最后就是对 J(W) 求最小值。这种不带约束条件的最优化问题,常用梯度下降或牛顿法来解决。
使用梯度下降法求解逻辑回归参数估计
求 J(W) 梯度:g(w):
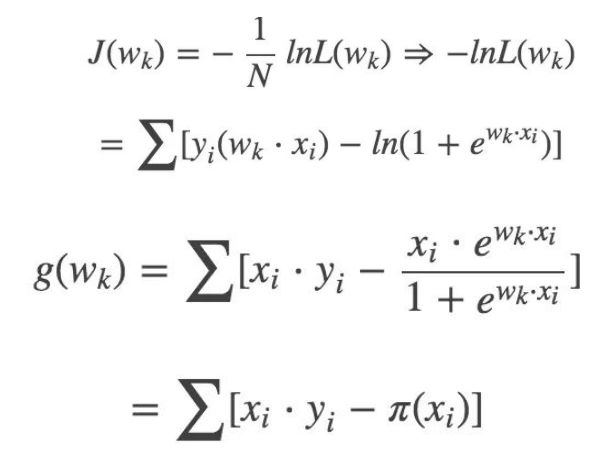
更新 Wk:
$$ W_{k+1} = W_k - \lambda*g(W_k) $$
5.4 正则化
正则化为了解决过拟合问题。分为 L1 和 L2 正则化。主要通过修正损失函数,加入模型复杂性评估;
正则化是符合奥卡姆剃刀原理:在所有可能的模型中,能够很好的解释已知数据并且十分简单的才是最好的模型。
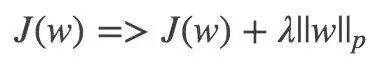
p 表示范数,p=1 和 p=2 分别应用 L1 和 L2 正则。
L1 正则化。向量中各元素绝对值之和。又叫做稀疏规则算子(Lasso regularization)。关键在于能够实现特征的自动选择,参数稀疏可以避免非必要的特征引入的噪声;
L2 正则化。使得每个元素都尽可能的小,但是都不为零。在回归里面,有人把他的回归叫做岭回归(Ridge Regression),也有人叫他 “权值衰减”(weight decay)。
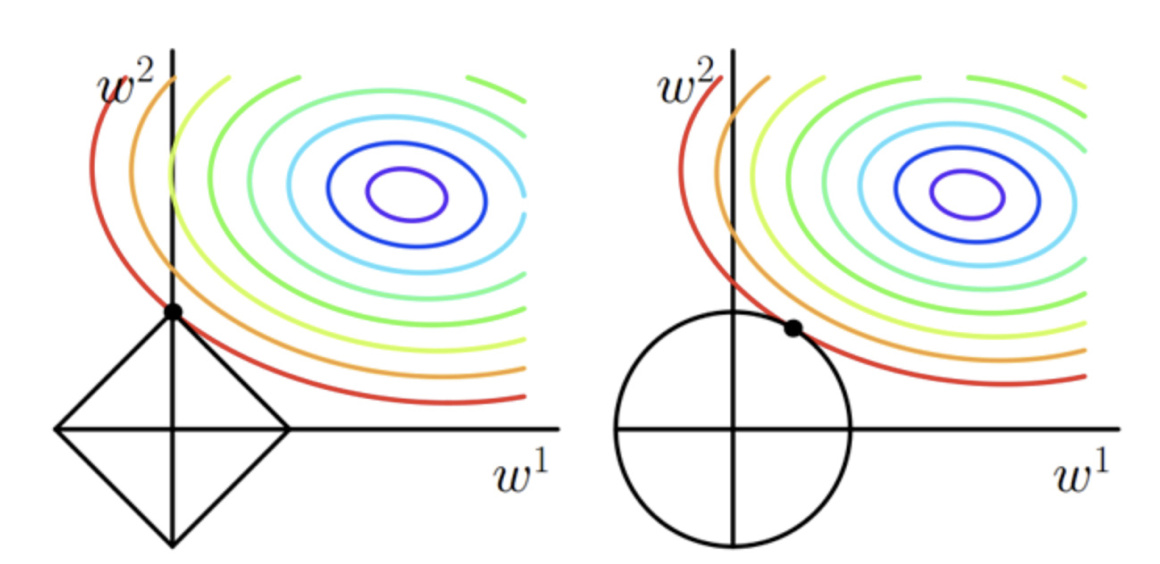
一句话总结就是:L1 会趋向于产生少量的特征,而其他的特征都是 0,而 L2 会选择更多的特征,这些特征都会接近于 0.
5.5 逻辑回归 vs 线性回归
首先,逻辑回归比线性回归要好。
两者都属于广义线性模型。
线性回归优化目标函数用的最小二乘法,而逻辑回归用的是最大似然估计。逻辑回归只是在线性回归的基础上,将加权和通过 sigmoid 函数,映射到 0-1 范围内空间。
线性回归在整个实数范围内进行预测,敏感度一致,而分类范围,需要在 [0,1]。而逻辑回归就是一种减小预测范围,将预测值限定为 [0,1] 间的一种回归模型。
逻辑曲线在 z=0 时,十分敏感,在 z>>0 或 z<<0 处,都不敏感,将预测值限定为 (0,1)。逻辑回归的鲁棒性比线性回归要好。
5.6 逻辑回归模型 vs 最大熵模型 MaxEnt
简单粗暴的说:逻辑回归跟最大熵模型没有本质区别。逻辑回归是最大熵对应为二类时的特殊情况,也就是说,当逻辑回归扩展为多类别的时候,就是最大熵模型。
最大熵原理:学习概率模型的时候,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。
6. SVM 支持向量机
注:面试中只要问到 SVM,最基本也是最难的问题就是:SVM 的对偶问题数学公式推导。
所以想学好机器学习,还是要塌下心来,不仅仅要把原理的核心思想掌握了,公式推导也要好好学习才行。
6.1 SVM 原理
简单粗暴的说:SVM 的思路就是找到一个超平面将数据集进行正确的分类。对于在现有维度不可分的数据,利用核函数映射到高纬空间使其线性可分。
支持向量机 SVM 是一种二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。SVM 的学习策略是间隔最大化,可形式化为求解凸二次规划问题。
SVM 分为:
线性可分支持向量机。当训练数据线性可分时,通过硬间隔最大化,学习到的一个线性分类器;
线性支持向量机。当训练数据近似线性可分时,通过软间隔最大化,学习到的一个线性分类器;
非线性支持向量机。当训练数据线性不可分,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
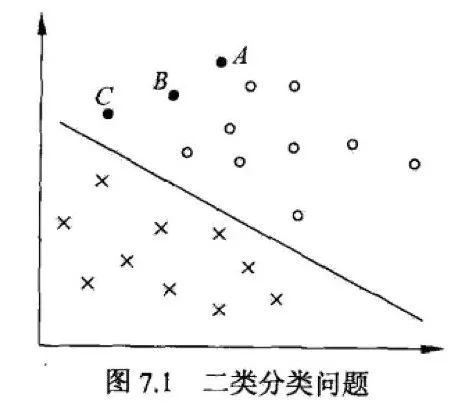
上图中,X 表示负例,O 表示正例。此时的训练数据可分,线性可分支持向量机对应着将两类数据正确划分并且间隔最大的直线。
6.1.1 支持向量与间隔
支持向量:在线性可分的情况下,训练数据样本集中的样本点中与分离超平面距离最近的样本点的实例称为支持向量(support vector)。
函数间隔定义如下:

yi 表示目标值,取值为 +1、-1. 函数间隔虽然可以表示分类预测的准确性以及确信度。但是有个不好的性质:只要成倍的改变 W 和 B,虽然此时的超平面并没有改变,但是函数间隔会变大。
所以我们想到了对超平面的法向量 W 施加一些约束,比如规范化,使得间隔确定,这就引出了几何间隔:

支持向量学习的基本思想就是求解能够正确划分训练数据集并且几何间隔最大的分类超平面。
6.1.2 对偶问题
为了求解线性可分支持向量机的最优化问题:
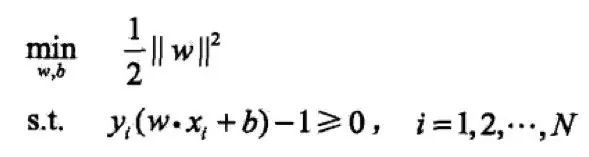
将它作为原始最优化问题,应用拉格朗日对偶性,通过求解对偶问题得到原始问题的最优解,这就是线性可分支持向量机的对偶算法。
本来的算法也可以求解 SVM,但是之所以要用对偶问题来求解,优点是:
一是对偶问题往往更容易求解;
二是自然引入核函数,进而推广到非线性分类问题。
说点题外话,这也是面试中会被问到的一个问题:原始问题既然可以求解,为什么还要转换为对偶问题。
答案就是上述这两点。由于篇幅的愿意,此处就不在展开数学公式的推导了,大家可以参考《机器学习》与《统计学习方法》。
6.1.3 核函数
对于在原始空间中不可分的问题,在高维空间中是线性可分的。
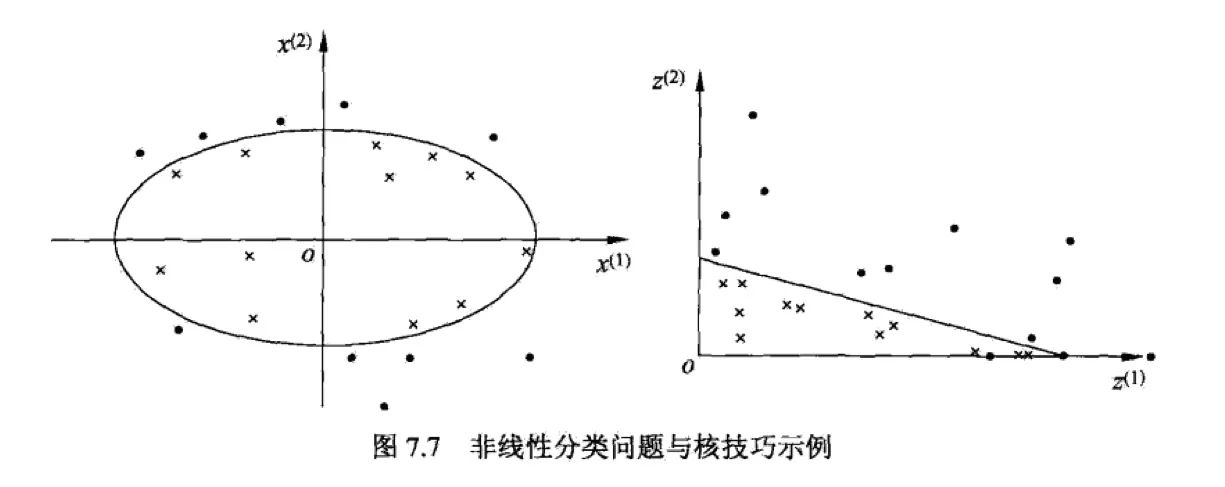
对于线性不可分的问题,使用核函数可以从原始空间映射到高纬空间,使得问题变得线性可分。核函数还可以使得在高维空间计算的内积在低维空间中通过一个函数来完成。
常用的核函数有:高斯核、线性核、多项式核。
6.1.4 软间隔
线性可分问题的支持向量机学习方法,对现行不可分训练数据是不适用的。所以讲间隔函数修改为软间隔,对于函数间隔,在其上加上一个松弛变量,使其满足大于等于 1。约束条件变为:
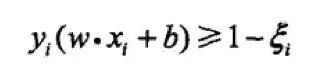
6.2 优缺点
缺点:
时空开销比较大,训练时间长;
核函数的选取比较难,主要靠经验。
优点:
在小训练集上往往得到比较好的结果;
使用核函数避开了高纬空间的复杂性;
泛化能力强。
7. 利用 sklearn 进行实战
使用 sklearn 用决策树来进行莺尾花数据集的划分问题。代码上没有固定随机种子,所以每次运行的结果会稍有不同。
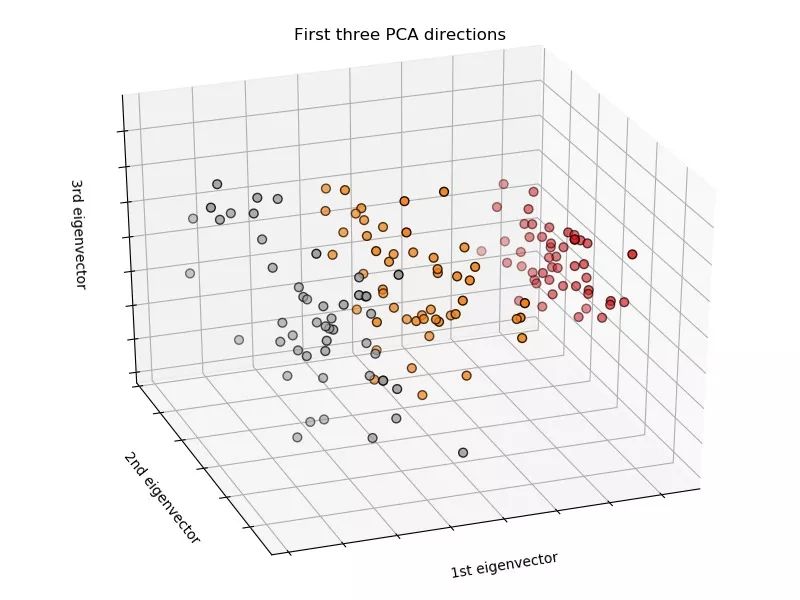
数据集三维可视化:
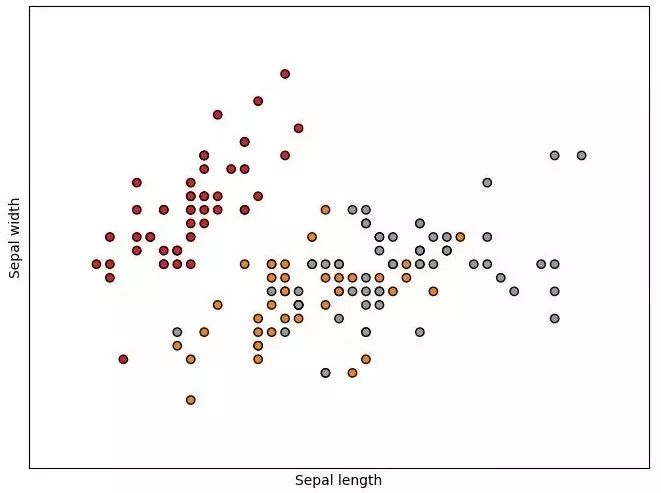
在 Sepal length 和 Sepal width 二维上的可视化:



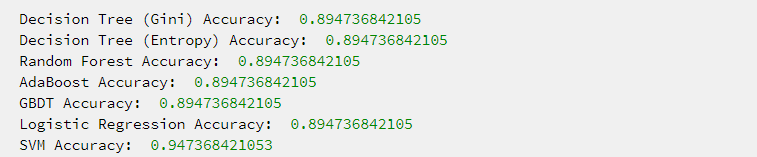
运行结果:
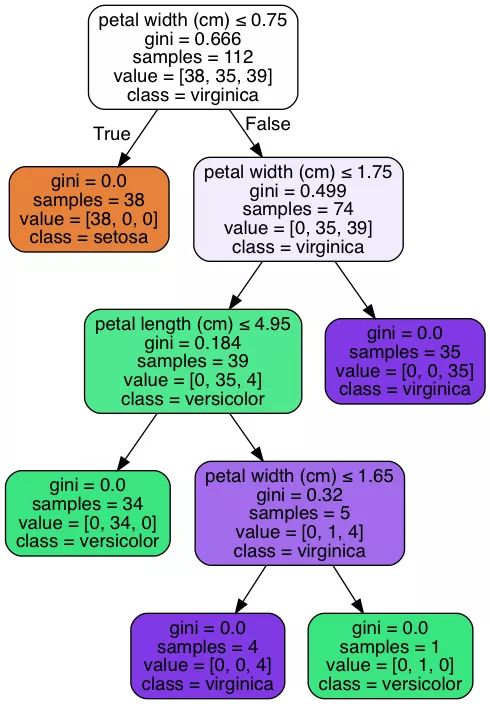
Decision Tree 可视化,也就是生成的决策树:
为帮助对人工智能感兴趣的同学,以及想转行到人工智能领域的在职人士。七月在线特别推出《机器学习集训营(三期)》,课程将以线上+线下(北京、上海两个实战基地)形式,引入BAT专家面对面、手把手教学方式;突出BAT级工业项目实战辅导,一步一步为你演示各个案例的实际操作,即使没有任何基础的同学也可以轻松上手。此外,还提供精讲面试考点,一对一面试求职辅导,从入门到高薪,轻松达成!
本期限100个名额,历时3个月,10多个BAT级工业项目,保障每一位学员所学更多、效率更高、收获更大。
课程详情点击文末“阅读原文”,或扫下方二维码试听






