深度学习视频超分辨率技术概述

视频超分辨率技术在卫星遥感侦测、视频监控、医疗影像等方面都发挥关键的作用,并凭借在各个领域广阔的应用前景而受到广泛关注。传统的视频超分辨率算法具有一定局限性。随着深度学习技术的愈发成熟,基于深度神经网络的超分辨率算法在性能上取得了长足进步。充分融合视频时空信息可以快速高效地恢复真实且自然的纹理,视频超分辨率算法因其独特的优势成为一个研究热点。本文系统地对基于深度学习的视频超分辨率的研究进展进行详细综述,对基于深度学习的视频超分辨率技术的数据集、评价指标进行了全面归纳。本文将现有视频超分辨率方法按照它们的研究思路分成两大类:基于图像配准的视频超分辨率方法和非图像配准的视频超分辨率方法,并进一步立足于深度卷积神经网络的模型结构,模型优化历程和运动估计补偿的方法将视频超分辨率网络细分为十个子类,同时利用充足的实验数据对每种方法的核心思想以及网络结构的优缺点进行了对比分析。视频超分辨率网络的重建效果在不断刷新的同时,模型的参数量也在逐渐降低,训练和推理速度不断加快。然而已有的网络模型在性能上仍然存在提升的潜能,本文最后对基于深度学习的视频超分辨率技术存在的挑战和未来的发展前景进行了讨论。
http://www.cjig.cn/jig/ch/reader/view_abstract.aspx?flag=2&file_no=202202170000002&journal_id=jig
超分辨率技术(Super-Resolution,SR)是近年来 计算机视觉和图像处理领域中的一个研究热点。其 主要目标是将低分辨率图像(视频)转换为高分辨 率图像(视频)。随着时代发展,人们对图像、视频 都有了更高质量的要求。在传输过程中,由于传输 带宽的限制,需要将视频、图像进行压缩处理。因此 存在细节信息的损失,需要使用相应的手段进行质 量提升。在安全防范方面,视频监控往往受到环境、 设备等因素的影响,获得的视频分辨率较低。超分 辨率技术应用于监视分析(Zhang 等,2010)和人脸 识别(Gunturk 等,2003;Li 等,2018),可以获取 车牌和人脸等感兴趣对象的关键信息。在医疗领域, 超分辨率技术通过恢复医疗影像的特征细节来帮助 病患获得及时准确的治疗。
超分辨率技术主要分为传统方法和基于深度学 习的方法两类。基于插值的超分辨率方法实现简单, 且已经被广泛应用。如最近邻插值法、双线性插值 法和双三次插值法(Dong 等,2015;Niklaus 等, 2017)等,通过利用周围像素点的像素值估计丢失 的像素值,但是这些线性的模型限制住了它们恢复 高频能力的细节。1964 年,Harris 和 Goodman(1964) 提出了 Harris-Goodman 频谱外推法。1984 年 Tsai 和 Huang 等(1984)利用傅里叶变换来实现高分辨率 图像的重建。Liu 和 Sun(2014)也曾提出一种贝叶 斯方法来估计帧间运动,进而重建高分辨率视频。这些算法受限于特定假设,在满足条件的情况下能 够获得比较好的仿真结果。但由于实际场景无法满 足所有假设条件,因此此类算法在实际应用中的效 果并不理想。
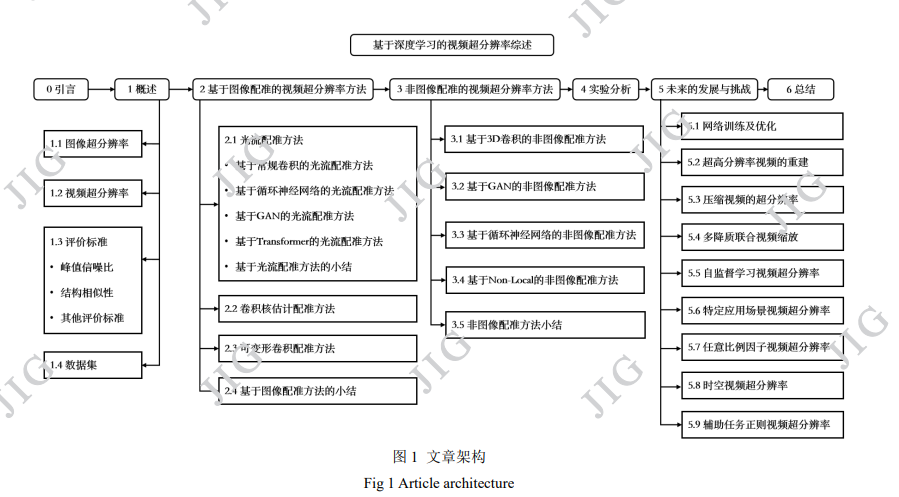
随着高分辨率显示设备的普及,传统的超分辨 率方法由于难以恢复视频和图像中的高频细节信息, 无法满足 4 倍放大因子的需求。而深度学习在图像、 语音、视频以及自然语言等领域取得的巨大成功, 为超分辨率算法研究提供了新的思路。基于深度学 习的超分辨率算法展现出了强大的非线性学习能力, 并使传统超分辨率技术逐渐被取代。文章结构如图 1 所示,基于深度学习的视频超 分辨率方法存在两大关键技术挑战,即相邻帧的配 准和多帧信息的融合重建。图像配准模块的选用与 否是已有方法的最大区别,因此本文从基于图像配 准的方法和非图像配准方法两个方面,全面综述近 年来视频超分辨率方法的现状。多帧信息的融合重 建方式则取决于网络结构,视频超分辨率网络的具 体分类可见图 2。在基于图像配准的方法方面,本文 将其分为基于光流的方法,基于卷积核估计的方法 和基于可变形卷积的方法三类。并进一步对基于光 流的方法细粒度划分为基于常规卷积的光流配准方 法、基于 GAN 的光流配准方法、基于循环神经网络 的光流配准方法和基于 Transformer 的光流配准方 法四种。在非图像配准的视频超分辨率方法方面, 本文将其分为基于 3D 卷积的非图像配准方法、基 于 GAN 的非图像配准方法、基于循环神经网络的方 法和基于 Non-local 的非图像配准方法等四种方法, 并对它们分别进行介绍。
目前,基于深度学习的图像超分辨率算法的综 述较多(Wang 等,2020;Singh 等,2020;Yang 等, 2019;Li 等,2022),而基于深度学习的视频超分辨 率的文献综述工作尚未引起广泛关注。吴(2017), 何(2011)等对基于传统方法的视频超分辨率进行 了综述,其中关于深度学习的方法涉及较少。Liu 等 (2020)对基于深度学习的视频超分辨率方法进行 了综述,但其对各个方法的实验总结分析较少,大 多是对网络结构和训练方法的阐述。近两年,视频 超分辨率迅速发展,RLSP(Fuoli 等,2019)、RRN (Isobe 等,2020)、OVSR(Yi 等,2021)等方法通 过设计轻量级网络可以实时地重建高分辨率。BasicVSR(Chan 等,2021)、IconVSR(Chan 等, 2021)、BasicVSR++(Chan 等,2021)等在性能上 实现了重大突破,展现出了惊人的结果。Transformer 在 CV 领域大放异彩,在视频超分辨率领域迅速得 到了学者们的关注,然而这些方法在 Liu 等(2020) 综述中尚未被提及。深度学习的视频超分辨率研究 仍在进一步发展,我们试图通过本篇文章,对该领 域既有的研究成果进行概述提炼,希望为日后视频 超分辨率重建相关领域的研究提供参考和帮助。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VSR” 就可以获取《深度学习视频超分辨率技术概述》专知下载链接



