时序异常检测算法概览
编者按:Statsbot CTO Pavel Tiunov简要介绍了最流行的时序异常检测算法,并讨论了它们的优点和缺点。
在Statsbot,我们持续检查异常检测方法这一领域的研究,并据此更新我们的模型。
本文概览了最流行的时序异常检测算法,并讨论了它们的优点和缺点。
本文是为想要了解异常检测技术发展现状的经验不足的读者写的,我们将模型的数学藏在参考链接里,以免吓到读者。
异常的重要类型
时序异常检测通常形式化为根据某种标准或正常信号寻找离群数据点。有很多异常类型,但本文只关注那些从商业角度来说最重要的类型,包括意料之外的峰谷、趋势变动、水平变化(level shift)。
例如,追踪网站的用户数时发现短时间内出乎意料的用户增长,看起来像是一个尖峰。这类异常通常称为加性离群值(additive outlier)。
再举一个例子,服务器挂了,某段时间内的用户数为零或极低。这类异常通常归类为时间变动(temporal change)。
再比如,你正处理某种转化漏斗(conversion funnel),可能会碰到转化率下降。如果发生这种情况,目标测度通常不会改变信号的形状,但会改变某段时期内的总值。取决于变化的特征,这类异常通常称为水平变化(level shift)或季节性水平变化(seasonal level shift)。
基本上,异常检测算法要么将每个时间点标记为异常/非异常,要么预测某一点的信号,并测试这一点的值和预测值的偏离程度,以认定异常。
使用第二种方法的时候,可以可视化置信区间,这对理解异常出现的原因并加以确认很有帮助。
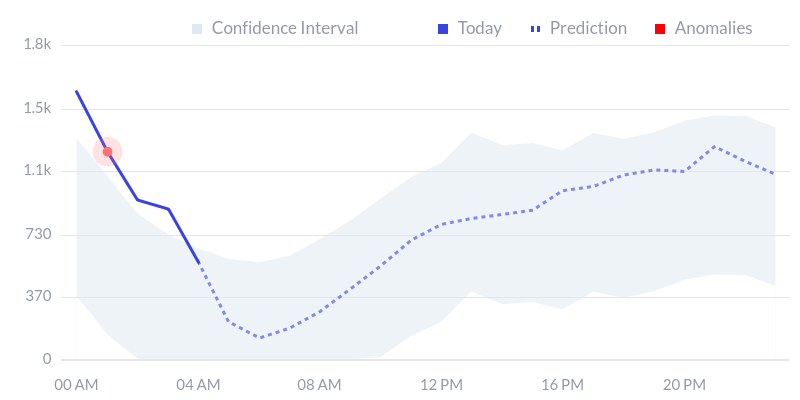
Statsbot的异常报告,虚线为预测,阴影部分为置信区间
下面我们将从应用角度查看寻找不同类型离群值的算法。
STL分解
STL是基于损失的季节性趋势分解过程的简称。这一技术可以将时序信号分成三部分:季节性(seasonal)、趋势(trend)、残余(residue)。
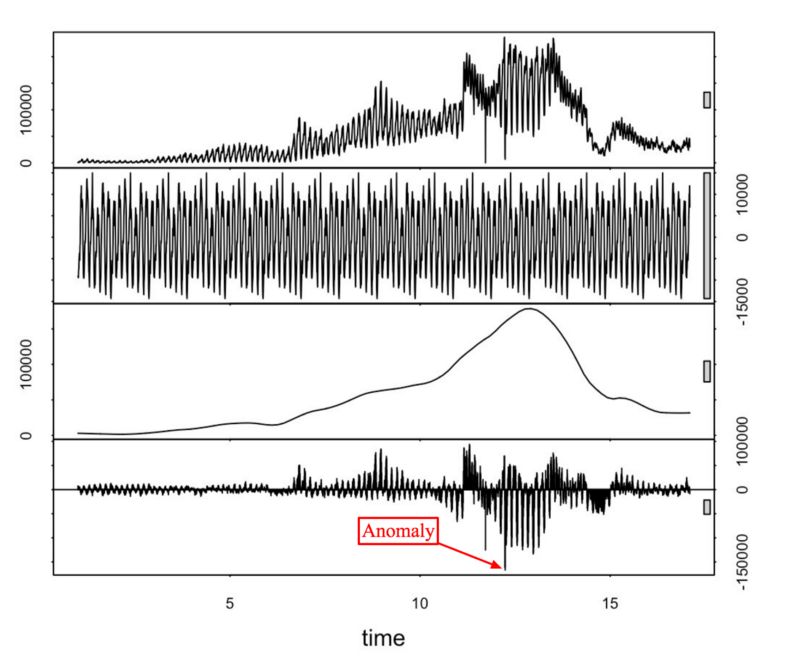
从上往下:原时序,季节性、趋势、残余部分
顾名思义,STL分解适用于季节性时序数据,这是最常见的情形。
如果你分析残余的偏离程度,并引入某种阈值,你会得到一种异常检测算法。
为了得到鲁棒性更好的检测效果,这里应该使用绝对中位差。该方法最先进的实现是Twitter的异常检测库。它使用Generalized Extreme Student Deviation(广义ESD)测试残余点是否是离群值。
优点
这一方法的优点在于简单性和鲁棒性。它可以处理许多不同情况,并且所有异常仍然可以直观地解释。
它主要擅长检测加性离群值。如果想要检测水平变化,你可以转而分析某种移动平均信号。
缺点
这一方法的缺点是调整选项很死板,你只能通过显著性水平调整置信区间。
信号特征剧烈变动是该方法效果不佳的典型场景。例如,追踪原本不对公众开放,随后突然开放的网站的用户数。在这种情形下,你应该分别追踪网站上线前和上线后的异常。
分类回归树
分类回归树(CART)是鲁棒性最好、效率最高的机器学习算法之一。它同样可以应用于异常检测问题。
首先,你可以使用监督学习教树分类异常数据点和非异常数据点。这需要你有标记好的数据点。
第二种方法是使用无监督学习教CART预测时序中的下一个数据点,得到和STL分解方法类似的置信区间或预测误差。你可以使用广义ESD检验或Grubbs检验检查数据点是否位于置信区间之内。
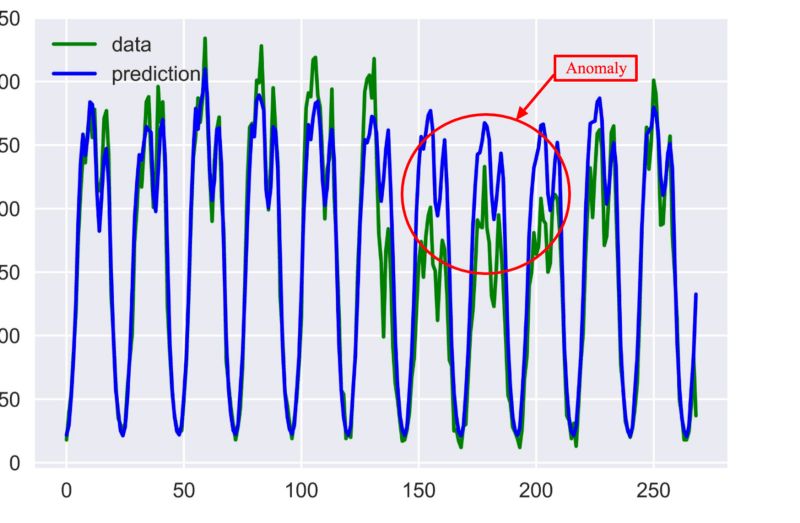
绿色为实际时序,蓝色为CART模型预测的时序,红圈内为检测到的异常
最流行的实现是XGBoost。
优点
这一方法的强项是它不受信号结构限制,可以引入更多的学习的特征参数得到复杂模型。
缺点
这一方法的弱点是特征数的增长很快会影响到算力表现。这种情形下,你应该精心选择特征。
ARIMA
ARIMA(整合移动平均自回归模型)是一个设计得非常简单的方法,但仍然足够强大,可以预测信号并指出其中的异常值。
它的思路是过去的若干数据点加上某个随机变量(通常是白噪声)可以预测下一个数据点。预测数据点可以进一步用来生成新预测,以此类推。显然,它的效果是让信号变得更平滑。
应用这一方法的难点在于你需要通过Box-Jenkins方法选择差异数、自回归数、预测误差系数。
处理新信号时应该创建新ARIMA模型。
另一个麻烦是对信号取差值后得到的信号应该是停滞的。也就是说,信号不应取决于时间,这是一个显著的限制。
创建一个适应离群点的模型,基于t统计量看它是否比原模型更好地拟合数据,这就可以实现异常检测。
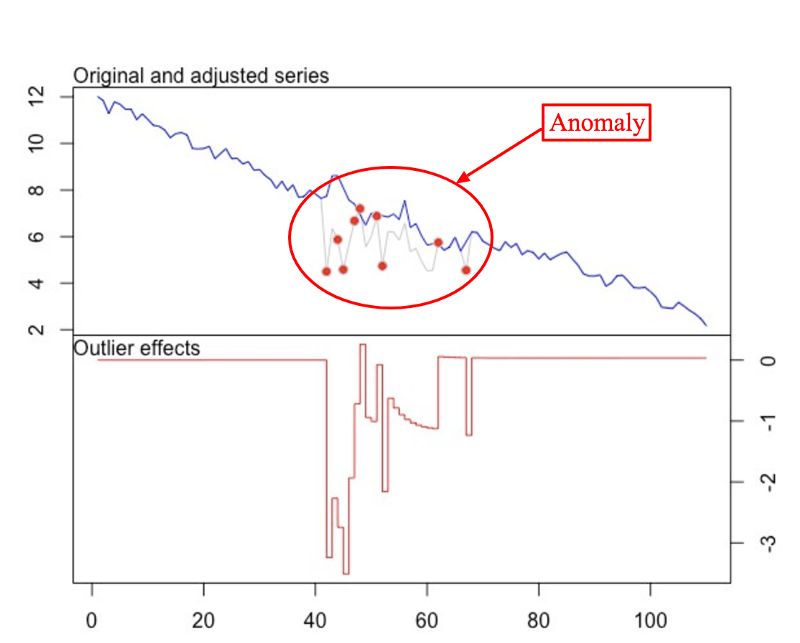
这一方法的实现,大家比较偏爱R语言的tsoutliers包。它适用于你可以为信号找到一个合适的ARIMA模型的情形,可以检测出各种异常。
指数平滑
指数平滑技术和ARIMA方法非常类似。基本指数模型等价于ARIMA (0, 1, 1)模型。
从异常检测的角度来说,我们最感兴趣的是Holt-Winters季节性方法。你需要定义季节性周期,比如一周、一月、一年。
万一你需要追踪多种季节性周期,比如同时追踪周和年,你应该选择其中的一种。通常是选择最短的周期,比如,在周和年之间选择周。
很明显,这是该方法的一个缺陷,会大大影响预测范围。
和STL或CART一样,通过统计学检验可以实现异常检测。
神经网络
和CART的情形类似,神经网络有两种应用方式:监督学习和无监督学习。
由于我们处理的是时序数据,最合适的神经网络类型是LSTM。如果构建得当,这种循环神经网络可以建模时序中最复杂的依赖关系,包括高层季节性依赖。
这一方法在处理耦合的多个时序数据时非常有用(arXiv:1602.07109)。
这一领域仍在研究之中(es2015-56),创建时序模型需要花很多功夫。不过,如果你成功的话,你可能取得突出的精确度。
💡建议💡
尝试最适合你的问题的最简单的模型和算法。
如果最简单的模型不奏效,转向更高级的技术。
从覆盖所有情形的更通用的解决方案开始是一个很有诱惑力的选项,但它并不总是最佳选择。
在Statsbot,我们组合使用从STL到CART和LSTM的不同技术,在不同规模上监测异常。
觉得本文有用?请分享本文,帮助其他人发现这篇文章。
原文地址:https://statsbot.co/blog/time-series-anomaly-detection-algorithms/





