学界 | 结合生成式与判别式方法,Petuum新研究助力医疗诊断
Petuum 专栏
作者:Shiyue Zhang、Pengtao Xie、Dong Wang、Eric P. Xing
机器之心编译
参与:Panda
在过去一年中,我们看到了很多某种人工智能算法在某个医疗检测任务中「超越」人类医生的研究和报道,例如皮肤癌、肺炎诊断等。如何解读这些结果?他们是否真正抓住医疗实践中的痛点、解决医生和病人的实际需要? 这些算法原型如何落地部署于数据高度复杂、碎片化、异质性严重且隐含错误的真实环境中?这些问题常常在很多「刷榜」工作中回避了。事实上,从最近 IBM Watson 和美国顶级医疗中心 MD Anderson 合作失败的例子可以看出,人工智能对医疗来说更应关注的任务应该是如何帮助医生更好地工作(例如生成医疗图像报告、推荐药物等),而非理想化地着眼于取代医生来做诊断,并且绕开这个终极目标(暂且不论这个目标本身是否可行或被接受)之前各种必须的铺垫和基础工作。因此与人类医生做各种形式对比的出发点本身有悖严肃的科学和工程评测原则。这些不从实际应用场景出发的研究,甚至无限放大人机对战,对人工智能研究者、医疗从业者和公众都是误导。
知名人工智能创业公司 Petuum 近期发表了几篇论文,本着尊重医疗行业状况和需求的研究思路,体现出了一种务实风格,并直接应用于他们的产品。为更好地传播人工智能与医疗结合的研究成果,同时为人工智能研究者和医疗从业者带来更加实用的参考,机器之心和 Petuum 将带来系列论文介绍。本文是该系列第四篇,介绍了使用机器学习方法基于实验室检测数据协助医疗诊断的研究成果。
误诊是指诊断决策不准确,是一种时有发生的情况。每年都有大约 1200 万美国成年人经历误诊,其中有一半可能造成伤害。实际上,有多达 40500 成年病人在重症监护病房(ICU)中死于误诊。误诊的一大主要原因是对临床数据的次优解读和使用。如今,医疗数据包含了实验室检测数据、生命体征、临床记录、药物处方等等,数据之多有时让医生难以应付。在各种各样的临床数据中,实验室检测数据发挥了重要的作用。据美国临床实验室协会(American Clinical Laboratory Association)称,实验室检测数据在诊断决策中的重要程度超过 70%。不幸的是,全面理解实验室检测结果并发现其中潜藏的临床应用价值却并非易事。对实验室检测数据的错误解读是诊断过程中出问题的主要地方。
实验室检测数据为何难以理解?原因有两方面。首先,缺失值是普遍存在的情况。在某个时间点只仔细检查一小部分实验室检测数据的情况很常见,此时其它大多数监测数据都被忽略了。这些数据的缺失让医生无法了解病人临床状态的全面图景,从而得到次优的决策。其次,这些实验室检测数据的值具有复杂的多变量时间序列结构:在入院期间,在某个特定时间要检查多个实验室检测数据以及同一种检测可能需要在不同时间点检查多次。这些多变量时间数据在时间和检测维度上都表现出了很复杂的模式。了解这些模式对诊断而言具有很高的价值,但在技术上却颇具难度。
在这项工作中,我们研究了如何利用机器学习(ML)的能力来自动从复杂的、有噪声的、不完整的和不规则的实验室检测数据中自动提取模式,从而解决上述问题并得到一种用于协助诊断决策的端到端诊断模型。在实验室检测数据基础上用机器学习方法执行诊断的研究已有先例。在这些方法中,处理缺失值、发现多变量时序中的模式、预测疾病这三大主要任务通常是分开执行的。但是这三大任务是紧密关联的并且可以互相提供帮助。一方面,更好地填补缺失值可以让我们发现更有信息的模式,这能提升诊断的准确度。另一方面,在模型训练期间,对诊断的监督可以为模式发现提供指导,这又能进一步影响对缺失值的填补,从而可以调整被发现的模式和被填补的值,使之适用于诊断任务。分别执行这些任务无法考虑到它们的协同关系,从而会得到次优的解决方案。之前的研究还存在另一个局限:它们往往是在一种判别式结构(discriminative structure)中提出的——从原理上看,这种结构无法很好地处理缺失值问题和学习可泛化的模式。
论文:结合生成式和判别式学习,根据实验室检测数据得出医疗诊断(Medical Diagnosis From Laboratory Tests by Combining Generative and Discriminative Learning)

论文链接:https://arxiv.org/abs/1711.04329
摘要:计算表型研究(computational phenotype research)的一个主要目标是执行医疗诊断。在医院里,医生依靠大规模临床数据来进行诊断决策,其中实验室检测数据是最重要的资源之一。但是,实验室检测数据的纵向性和不完整性给这种数据的解读和应用带来了显著的挑战,这可能会导致人类医生和自动诊断系统得出有害的决策。在这项工作中,我们利用了深度生成模型来处理复杂的实验室检测数据。具体而言,我们提出了一种端到端的架构,其涉及到一个用于学习稳健且可泛化的特征的深度生成变分循环神经网络和一个用于学习诊断决策的判别式神经网络模型,而且这两个模型的训练是联合进行的。我们的实验所采用的数据集涉及到 46252 个病人以及用于预测 50 种最常见诊断的 50 种最常用检测。实验结果表明我们的模型 VRNN+NN 的表现显著(p<0.001)超过了其它基准模型。此外,我们还表明:比起通过纯粹的生成模型所学到的表征,通过联合训练学习到的表征具有更丰富的信息。最后,我们发现我们的模型填补缺失值的方式好得让人惊讶。
贡献
在这篇论文中,我们开发了一种端到端的深度神经网络来根据实验室检测数据执行诊断。我们的模型将三种任务无缝地整合到了一起并能联合执行它们——这三种任务分别是填补缺失值、发现多变量时序数据中的模式和预测疾病。我们的模型结合了机器学习领域两种主要的学习范式:生成式学习和判别式学习;其中生成式学习组件被用于处理缺失值和发现稳健的且可泛化的模式,而判别式学习组件则被用于根据生成式学习过程中发现的模式来预测疾病。我们在 46252 份 ICU 病人就诊数据上对我们提出的模型进行了评估,结果表明我们的模型实现了(1)比基准模型显著(p<0.001)更优的诊断表现,(2)对缺失值的更好填补,(3)在实验室检测数据上的更好的模式发现。
方法
数据预处理
本研究所用的数据来自公开可用的 MIMIC-III。它来自 46252 位病人的实验室检测结果,其中包含住院记录和门诊记录。每个住院时间阶段都有 1 到 39 个对应的 ICD-9(国际疾病分类,第九版)编码,本研究只考虑了其中主要的诊断。这个数据集共有 2789 种不同的诊断和 513 种各不相同的实验室检测。因为某些诊断和检测是相当罕见的,所以我们将我们的研究限制在了 50 种最常见的诊断和 50 种最常用的实验室检测上。我们以每天的日期为标准对检测结果进行了分组,并最终得到了 30931 个住院记录的时间序列,其中每一个都标注了一种疾病的 ID,分别是从 0 到 49。这些时间序列的长度从 2 到 171 不等,而我们关注的是最近的 100 天。图 1 给出了这 50 种疾病的 ID 所对应的样本的数量。我们对该数据集进行了 5 次随机切分,每一次我们都按特定比例将该数据集分成了训练集(Train)、开发集(Dev)和测试集(Test),它们的比例为 65%:15%:20%。因此,这三个集合中的样本的数量分别为 20105、4640 和 6186。
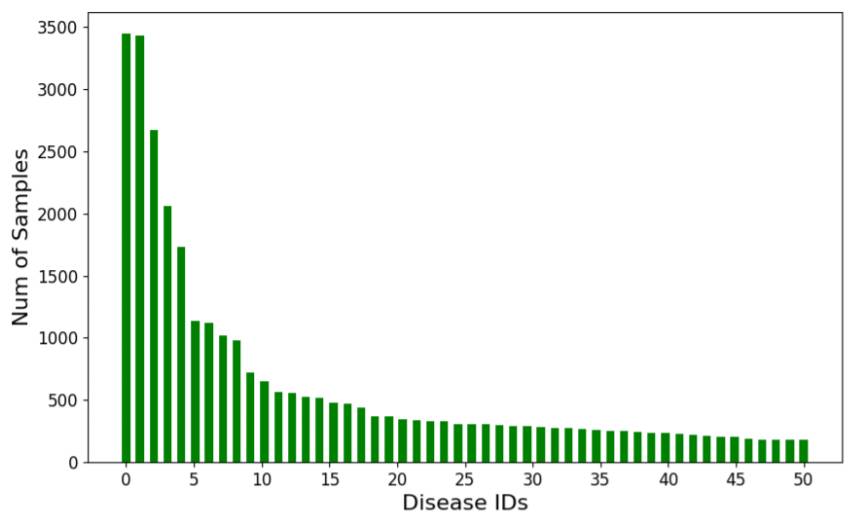
图 1:疾病 ID 对应的样本的数量
有些检测数据加了离散的类别值,比如「ABNORMAL(异常)」和「NORMAL(正常)」,我们将这些类别换成了整型值,比如用 0 表示「ABNORMAL」,用 1 表示「NORMAL」。检测结果用 Z 归一化(Z-normalization)进行了归一化处理,即每个检测值都减去均值,然后再除以标准差。注意,病人不会每天把每种检测都做一遍,所以我们的数据中缺失值是很普遍的。图 2 给出了一个病人的实验室检测记录的例子。可以看到其中有大量缺失值。对整个数据集进行简单的统计后发现,值的平均缺失率大约为 54%,也就是说在每天的记录中,50 项实验室检测中平均仅有 27 项有值。在我们实验中,我们起初都用 0 来填补这些缺失值。在应用了 Z 归一化之后,这些值的均值都变成了 0。所以零填补就等同于均值填补。此外,因为我们的模型处于神经网络框架内,所以零输入不会给计算引入额外的偏差。注意,在基准模型中,这种零填补方法表现得像是缺失值问题的解决方法,而在我们的模型中,它表现得像是缺失值的指示器,然后这些缺失值会由深度生成模型进行进一步的处理。

图 2:一位病人的实验室检测记录示例。y 轴对应于我们所用的 50 项实验室检测。x 轴表示记录的时间。绿点表示有值,否则就缺失值。
模型架构
我们在本研究中提出了两种模型,分别表示为 VAE+NN 和 VRNN+NN。其中前者是一个静态模型,可以证明深度生成模型的贡献;后者则是一个时间模型,是对深度生成学习方法的延展,从而可学习长期时间依赖(long-term temporal dependency)。

图 3:我们的模型的架构:(a)VAE+NN 的架构,(b)VRNN+NN 的架构
VAE+NN
其中 VAE(变分自编码器)是用于处理缺失值和发现模式的生成模型,标准的神经网络(NN)则被用作分类器,如图 3(a) 所示。
VRNN+NN
其中 VRNN(变分循环神经网络)用于生成按顺序排列的隐藏特征,NN 模型则会根据这些隐藏特征的平均来得出决策,如图 3(b) 所示。
基准
为了进行比较研究,我们构建了几种基准模型,分别表示为 NN、AE+NN、RNN+NN。其中 NN 和 AE+NN 用于与 VAE+NN 模型进行比较,我们想知道在表征单个特征向量时深度生成模型是否能有更好的表现。RNN+NN 模型与之前研究中的模型结构类似,它被用于与我们的 VRNN+NN 模型进行比较。
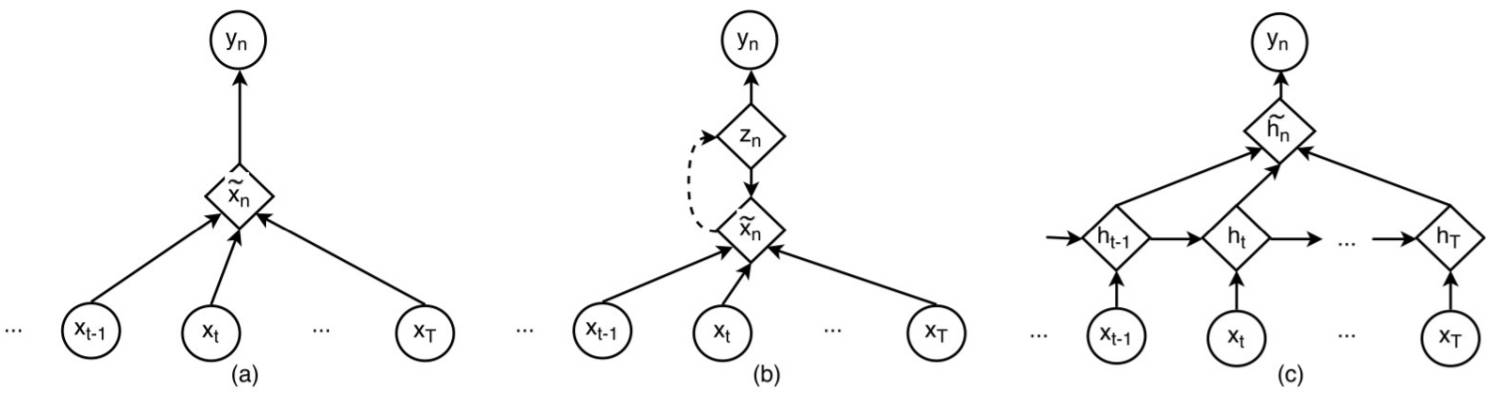
图 4:基准模型的模型架构:(a)NN 的架构,(b)AE+NN 的架构,(c)RNN+NN 的架构
NN
NN 模型就是一个简单的多层感知器(MLP),如图 4(a) 所示。
AE+NN
AE+NN 基准模型基于标准的自编码器,如图 4(b) 所示。AE 与 VAE 类似,但其结构是确定性的,所以生成能力更差。在这个模型中,我们还将 AE 和 NN 的损失结合到了一起。我们使用了均方误差(MSE)作为 AE 的训练目标。
RNN+NN
RNN+NN 模型如图 4(c) 所示。在这个模型中,RNN 处理原始的时间特征,隐藏状态的平均被用作 NN 的输入。
实现细节
在我们的实验中,模型是在 TensorFlow r1.0 上实现的。所有的 ϕ_τ和 ϕ_d 都是带有一个隐藏层和 ReLU 激活的前向神经网络。隐藏层的大小设置为 64。我们使用了 Adam 作为优化器,其中学习率设置为 0.0005,学习率衰减为 0.99。权衡(trade off)参数 η 在所有实验中都设置为 0.5。
结果
表 1 给出了三组实验的诊断表现。上面一组值是不同模型在诊断任务上的表现,是根据 F1 值和 AUC 的不同变体测定的。此外,为了测试联合训练是否能比无监督生成模型得到更好的表征,来自 VAE、VAE+NN、VRNN 和 VRNN+NN 的表征被用来训练了一个用于诊断决策的新模型。表 1 中间一组数据给出了其结果。最后,为了在缺失值处理方面比较我们的 VRNN+NN 模型和一些启发式填补方法,我们调查研究了四种填补方法:「zero」是基准模型的默认方法,「last&next」、「row mean」和「NOCB」是三种最广为人知的填补方法(据研究 [32]):「last&next」是取前一个已知值和后一个已知值的均值;「row mean」是取前一个病人和后一个病人的均值;「NOCB」是填补反向遇到的下一个观察。

表 1:三组诊断表现;所有结果都以「均值±标准差」的形式给出
为了评估表 1 中的结果是否可靠,我们应用了配对 t 检验(paired t-test)来检查不同模型的表现差异是否具有统计显著性。结果在表 2 中给出。

表 2:在诊断表现上的配对 t 检验的 P 值。注:(p<0.001),(p<0.01),(p<0.05)
因为深度生成模型可以重新构建输入数据,所以我们推测我们的 VRNN+NN 模型有更好的填补缺失值的潜力。为了测试这个推测,我们首先随机丢弃了原始数据中 10% 的值,然后使用训练后的 VRNN+NN 来填补这些故意丢弃的值。结果用 MSE 给出,如表 3 所示,其中也给出了启发式填补方法的 MSE 值。另外也给出了这些方法的配对 t 检验结果。

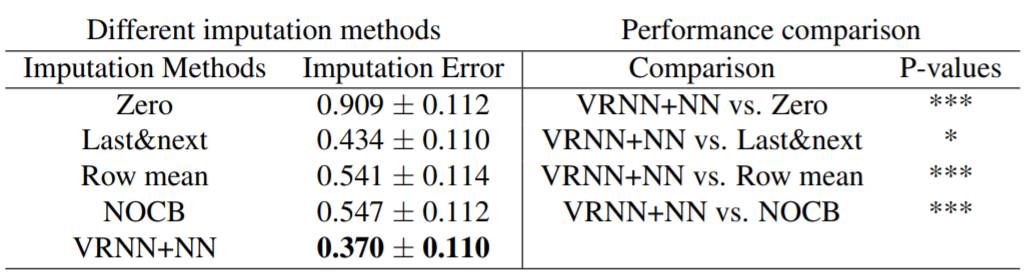
表 3:左部分是不同填补方法的填补误差;右部分是配对 t 检验得到的表现比较。注:(p<0.001),(p<0.01),(p<0.05)
扩展阅读
本文为机器之心经授权编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com