【前沿】自动从CT医疗影像中生成诊断报告,卡内基梅隆大学CMU邢波教授团队最新基于深度学习的医疗影像研究成果
点击上方“专知”关注获取专业AI知识!

【导读】CMU邢波(Eric Xing)团队最近在arXiv上发布新论文,采用深度学习方法自动地从CT医疗影像中生成诊断报告,大大提高医生诊疗效率。写作报告对经验丰富的医生来说也是容易出错的,而且在人口高度密集的国家,写报告对医生来说无疑是费时和繁琐的。为了解决这些问题,其团队研究了医学影像报告的自动生成方法,以帮助医生更准确和有效地生成报告,未来可能对医疗领域产生重大影响。
邢波,生物和计算机双博士。 1988-1993年 清华大学物理学、生物学本科;1994-1999年 美国新泽西州立大学(Rutgers University)分子生物学与生物化学博士;1996-1998年 美国新泽西州立大学(Rutgers University)计算机科学硕士; 2000-2004 美国加州大学伯克利分校(UC,Berkeley)计算机科学博士;现任美国卡耐基梅隆大学(CMU)计算机系副教授,专业方向:计算机科学、统计、机器学习、计算生物学。
邢波教授是卡耐基梅隆大学计算机学院教授,机器学习系副系主任, Petuum公司CEO,Petuum在2016年获得腾讯等公司1500万美金A轮风险投资。在此之前,邢波教授曾主持CMU的一个机器学习和医疗中心,致力于基于自然语言处理,图像和视频分析,计算基因组学以及泛组学等使用多维异质数据源的精准个性化医疗和智慧医院研发,以及包括移动和可穿戴设备,医疗数据隐私安全等应用于医疗行业的大数据技术。
邢波团队将深度学习应用于医疗影像数据的理解和挖掘,但他认为未来深度学习仍只是众多机器学习方法论中的一种。在他看来,深度学习面临的一个主要的问题,是大部分人并不很清楚它在数学模型上的显性形式,也就是说从业者其实并不是很清楚所设计的算法是不是真正决定性的,以一种可复制,可延展,可解释,可理论证明的方式导致了问题的解决。
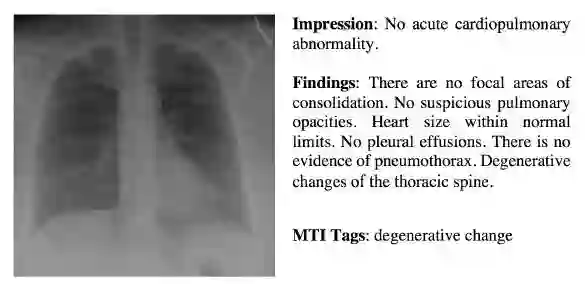
这是一个胸部X光的报告示例,其中包含多个部分的信息。第一个整体印象部分,放射科医师将影像学检查结果,患者临床病史和适应证结合起来,提供诊断简要说明。第二个结果部分列出了影像学研究中所检查身体每个部位的放射学观察和发现。第三个标签部分列出了代表关键信息的关键字。这些关键字使用医学文本索引器(MTI)进行标识。
▌详细内容
常见的医学图像,如放射图和病理图像,广泛应用于医院和诊所,应用于许多疾病的诊断和治疗,如肺炎、气胸、肺间质病变、心力衰竭、骨折、食管裂孔疝等。医学图像的阅读和理解通常由专业的医学人员进行操作。例如,放射图像和病理图像由放射科医师和病理学家解读。他们通过撰写文字报告(如图1所示),叙述在医学成像中对身体各个部位检查的发现,特别是身体每个部位是否正常、异常或潜在异常。对于经验不足的放射科医师和病理学家,尤其是那些在医疗质量相对较低的农村地区工作的人来说,撰写医学影像报告是很困难的。
例如,要正确解读胸部X光图像,需要具备以下技能:(1)全面了解胸部的正常解剖和胸部疾病的基本生理;(2)用固定模式和技巧分析X光照片;(3)时间演化的评估能力;(4)临床症状和临床历史记录的知识;(5)了解与其他诊断结果(实验室结果,心电图,呼吸功能测试)的相关性。
对于有经验的放射科医师和病理学家来说,写医学成像报告既繁琐又费时。在人口大国,如中国,放射科医生可能每天需要读取数百幅放射图像。把每个图像的结果输入计算机大约需要5-10分钟,这占用了他们大部分的工作时间。总之,对于无经验的和经验丰富的医疗专业人士,写成像报告是令人反感的。
这促使其来调查是否有可能自动生成医学图像的报告。为了实现该目标,需要解决若干挑战。
第一,一个完整的诊断报告由多种不同形式的信息组成。如图1所示,胸透的报告包含一个句子,一个段落和一个关键词列表。在统一的框架中生成这种异构信息在技术上要求是很高的。研究团队通过构建一个多任务框架来解决这个问题,该框架将标记预测任务作为一个多标签分类任务,并将长描述(如印象、发现)作为文本生成任务来生成。在框架中,这两个任务共享相同的CNN,共同执行并用于学习视觉特征。
第二,医学图像报告更侧重于叙述发现的异常,因为它们直接指示疾病和指导治疗。如何定位包含异常的图像区域并将正确的描述附加到对应的区域中是具有挑战性的。团队通过引入一个共同注意力机制来解决这个问题,该机制同时关注图像和预测标签,并探索视觉和语义信息的协同效应。第三,成像报告中的描述通常很长,包含多个句子,甚至多个段落。生成如此长的文本是非常困难的。我们不采用单层的LSTM,因为它不能够模拟长单词序列。我们利用该报告的组成,采用分层LSTM生成长文本。结合共同注意力机制,分层LSTM首先生成高级别的主题,然后根据主题产生细粒度的描述。
总体来说,所做的工作的主要贡献有:
提出了一个多任务学习框架,它可以同时预测标签并生成文本描述;
引入一种共同注意力机制来定位异常区域并生成相应的描述;
构建一个分层LSTM用来生成长句子和段落;

整体的生成流程,在传统的CNN-RNN结构的image captioning方法中加入对特定视觉特征的Attention权重。

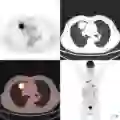
由Ours-CoAttention,Ours-no-Attention和Soft Attention这三种模型生成的诊断结果。带下划线的句子是对检测到的异常的描述。第二个图像是一个横向的X射线图像。前两幅图像是正确结果,第三幅是部分失败案例,最后一幅是失败案例。这些图像都来自测试数据集。
论文:On the Automatic Generation of Medical Imaging Reports
链接:https://arxiv.org/pdf/1711.08195.pdf

(附上专知内容组翻译的摘要和引言,有错误和不完善的地方,请大家提建议和指正)
▌摘要
医疗影像广泛应用于临床诊断和治疗。专业的医生通过阅读医疗影像图来编写医疗调查报告。写作报告对经验丰富的医生来说也是容易出错的,而且在人口高度密集的国家,写报告对医生来说无疑是费时和繁琐的。为了解决这些问题,我们研究了医学影像报告的自动生成方法,以帮助医生更准确和有效地生成报告。
该任务面临以下几个挑战:首先,完整的医学报告包含多种异构的信息形式,包括段落和标记,它们是关键字的列表。第二,医学图像中的异常区域难以识别,生成它们的文本描述更是难上加难。第三,医学报告通常很长,包含多个段落。为了应对这些挑战,我们(1)建立一个多任务学习框架,共同执行标签的预测和段落的生成;(2)提出了一个共同的注意机制,用来区域异常局部化和产生相应的描述;(3)开发了一个分层的LSTM模型来生成长的段落。我们证明了所提出的方法在胸部X光数据集和病理数据集上的有效性。
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃集合】人工智能领域主题知识资料全集[ 持续更新中](入门/进阶/论文/综述/视频/专家等,附查看)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请关注我们的公众号,获取人工智能的专业知识。扫一扫关注我们的微信公众号。


点击“阅读原文”,使用专知!