利用Capsule重构过程,Hinton等人实现对抗样本的自动检测
选自 arXiv
机器之心编译
机器之心编辑部
胶囊网络(capsule network,CapsNet)可以自动把对抗样本揪出来啦。如果对抗样本让分类器把看起来是🐱的图像识别成了🐶,利用重构过程,capsule 模型可以把这张图像还原成🐶,并且还知道这张被识别成🐶、还原成🐶的图像并不是🐶。这项研究来自 capsule 模型的原作者 Sabour、Frosst 以及 Hinton,相关论文将在 NIPS 2018 的机器学习安全研讨会中展示。
在一般的图像识别过程中,模型只是简单地输出图像的类别,而没有输出图像的特征,甚至并不能内在地、完整地表征图像。这导致了在测试中受到对抗攻击时,除非让人进行对比验证,否则根本不知道出了问题;或者直到出了问题,才知道存在对抗攻击。
Sabour 等人在 2017 年的论文《Dynamic Routing Between Capsules》中表明,通过添加另一个根据姿态参数(pose parameter)和正确的顶层 capsule 特征重建输入图像的网络,可以提升 capsule 网络的判别性能。通过重建网络进行反向传播的导数迫使顶层 capsule 的姿态参数去捕获大量图像信息。利用此类正则化器训练的 capsule 网络不仅能输出类别,还能输出输入的类别条件重建图像。
在近期由 Nicholas Frosst、Sara Sabour、Geoffrey Hinton 等人的研究论文中指出,重建子网络可以有效地检测对抗攻击:根据 winning 顶层 capsule 的姿态参数和特征来重建输入,以验证网络正在感知我们期望其在该类典型样本中感知的目标。也就是说,重建图像才是网络真正看到的图像,如图 1 所示。
论文提出了一种和攻击无关的检测技术——DARCCC,它依赖于真实图像和对抗图像的类别重建距离分布之间的差异。作者把 DARCCC 扩展到更标准的图像分类网络(卷积神经网络)后发现,在黑箱攻击和典型的白盒攻击上,本文提出的检测方法在 MNIST、Fashion-MNIST、SVHN 三种图像数据集上效果更好,如图 4 所示。
然而,论文提出的检测方法能够被更为强大的白盒攻击击败。该白盒攻击使用 R-BIM 方法把重建误差考虑在内并反复干扰图像,从而允许良好的重建。然而,这种更强的攻击不会产生与原始图像相似但带有少量附加噪声的典型对抗图像。相反,为了使模型错误地对图像进行分类,对原始图像的干扰必须很大,并通常生成实际上与目标类别其它图像相似的「对抗」图像(这样在定义上就不能称为「对抗」啦,如图 D.4 所示)。此外,对 capsule 网络来说,如果对重建误差施加了足够的权重来避免检测,它通常不可能改变图像,产生所需错误类别。
论文:DARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules

论文地址:https://arxiv.org/pdf/1811.06969.pdf
摘要:本研究展示了一种简单技术:用 capsule 模型检测对抗图像。capsule 模型不仅能够对图像进行分类,还可以利用姿态参数(pose parameters)和正确的顶层 capsule 特征来重建图像。对抗图像与典型的类别预测并不相同,当模型根据对应类别的顶层 capsule 特征重建图像时,它们的重建误差较大。我们在输入图像及其根据顶层 capsule 得到的重建图像间设置 L2 距离的阈值,该方法可以在三种不同数据集上高效检测对抗图像。
对于训练用来重建图像的 CNN 来讲,例如利用最后一个隐藏层(Softmax 之前)的全部或部分输出重建图像,该技术也很有效。我们还探索了更强大的白盒攻击,其将重建误差也考虑在内。白盒攻击能够欺骗我们的检测技术,但要想使模型改变预测类别,白盒攻击必须使「对抗」图像类似其他类别的图像。
方法
在《Dynamic Routing Between Capsules》提出的 CapsNet 中的重建网络中,其采用所有类别 capsule 的姿态参数,并且除了对应预测类别的姿态参数,其它所有值都被 mask 为 0。在训练过程中,研究者优化了输入图像和重建图像在分类损失上的 L2 距离。我们使用相同的重建网络,通过测量输入和预测重建之间的欧式距离来检测对抗攻击。
图 2 展示了一个抽样的自然图像 vs 对抗图像的距离直方图。我们利用两种分布之间的不同并提出 DARCCC 来基于类别重建检测对抗样本。DARCCC 可以基于重建距离的阈值来分辨对抗样本。图 1 展示了真实样本和对抗样本的重建图像;对抗重建和输入图像之间的偏差启发了本研究的方法。

图 1:来自训练好的胶囊网络的预测类别姿态参数的重建,用于实际数据(图左)以及成功地实现对抗目标类别为「1」的数据(图右)。来自对抗性数据的重建类似于输入图像的「1」(图右)。
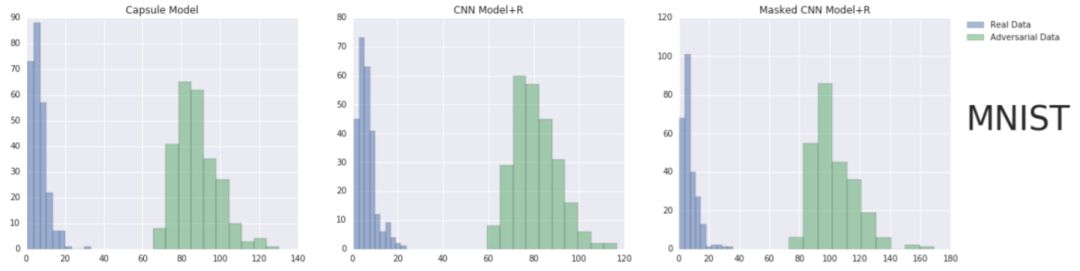
图 2:在 MNIST 的真实数据和对抗数据上,capsule 模型(图左)、CNN+R(图中)、Masked CNN+R(图右)的输入和重建样本之间的 L2 距离直方图。
尽管上述系统是针对 CapsNet 的信息姿态参数而设计的,相同的策略也可以扩展到 CapsNet 以外的模型。通过使用标准的 CNN 并将倒数第二个隐藏层分为对应每个类别的组,我们创建了一个类似的架构「Masked CNN+R」。每个神经元组的和作为对应类别的逻辑值。并且通过 Sabour 等人使用过的相同 masking 操作,这个组自身会被传递到重建子网络。我们还研究了通过忽略 masking 并使用典型「CNN+R」模型来探索类别条件重建的作用,其整个倒数第二层被用于重建。
图 3 画出了三个模型的误差率、攻击检测率和成功攻击检测率。对于所有三个模型,DARCCC 不仅能准确地检测到成功改变类别的攻击(成功攻击检测率),还能检测到无论是否改变类别而进行的图像扰动(攻击检测率)。
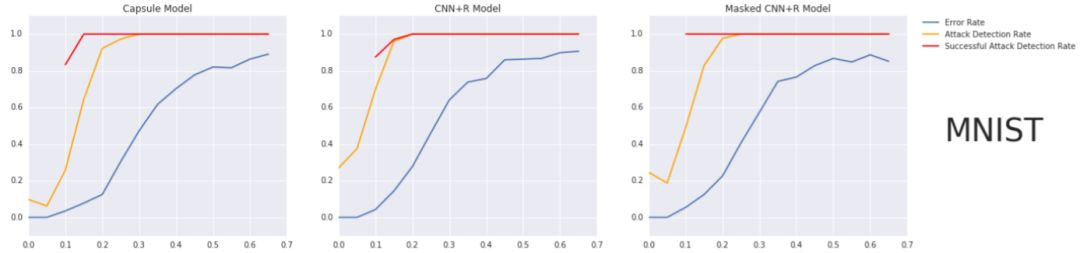
图 3:DARCCC 攻击检测率、成功攻击检测率和黑箱 FGSM 攻击误差率的图示。从图中可以看出,随着误差率的增加,检测率也在增加,并在误差率到达一定程度后能保持几乎 100% 的检测率;此外,DARCCC 对成功攻击的对抗扰动更加敏感。
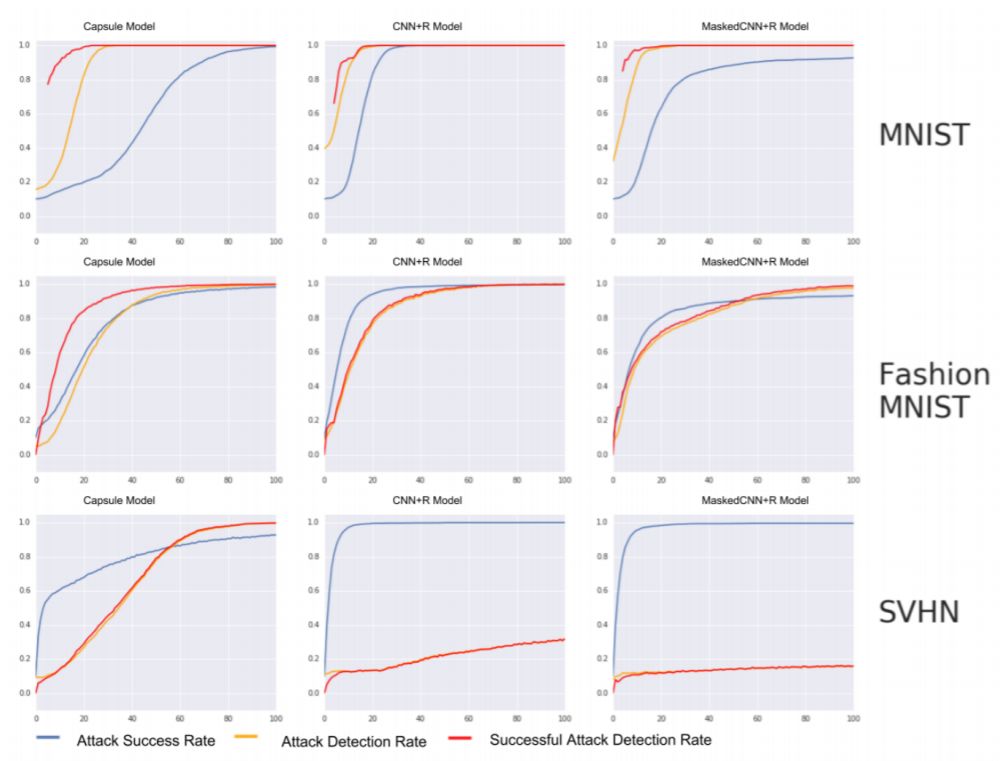
图 4:在不同时间步中,DARCCC 检测率和白盒 BIM 攻击成功率。从图中可以看出,当攻击成功率(蓝色)逐渐增大时,三个模型在 MNIST 和 Fashion MNIST 数据集上都表现不错,都能以很高的概率检测到对抗扰动和成功攻击的对抗扰动;而在 SVHN 数据集上,capsule 模型表现得更好。
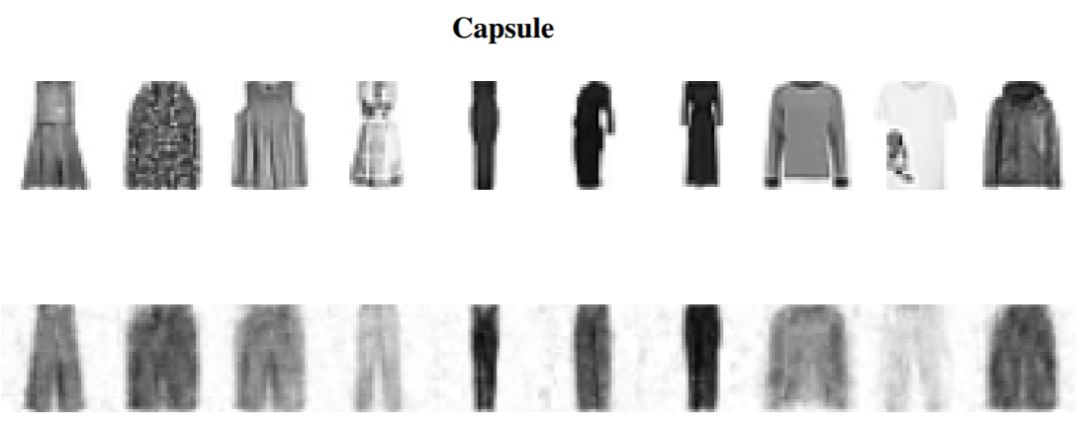


图 D.4:每个模型的初始图像(顶部)和 R-BIM 扰动图像。这些图像能成功地让分类器作出「裤子」目标类别的预测。只有 Capsule 模型攻击需要使用和「裤子」图像相似的初始图像才能实现攻击,并且没有「鞋子」图像能成功让分类器作出「裤子」类别的预测。
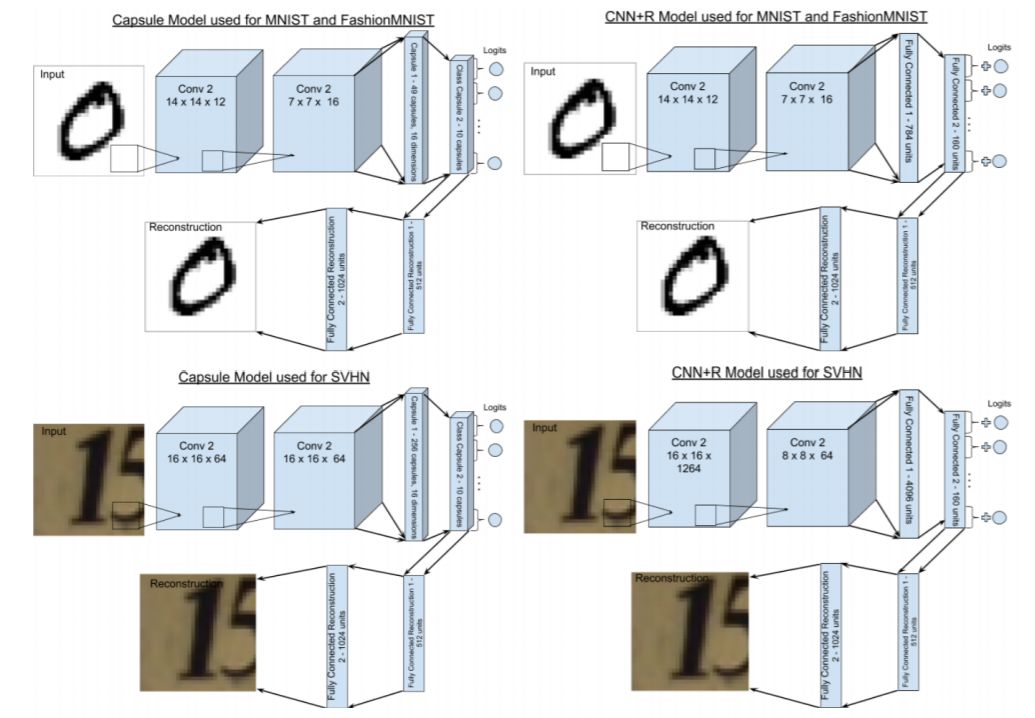
图 A.1:用于重建的 CNN+R 和 Capsule 模型的架构。
所以这篇论文的意义到底是什么呢?简言之,研究者表示:结合重建过程,CapsNet 可以用来自动检测对抗攻击,不需要人力;并且 CapsNet 防御对抗攻击的能力更强,只有和攻击目标很像的对抗样本才更容易成功 CapsNet,这也削弱了样本的对抗性;研究者并没有提出将成功攻击 CapsNet 的样本的预测优化为真实预测的方法,或许这会是下一个值得探索的方向。此外,CapsNet 相对于另外两个基于CNN的重建架构在防御和检测对抗攻击上存在很大的优势,这种优势的根本原因是什么,是不是表征等变性?同样值得深思。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
