使用嵌入来做个性化的搜索推荐:来自Airbnb

作者:Mihajlo Grbovic
编译:ronghuaiyang
这是Airbnb的一篇经典文章的解读,使用房屋的嵌入来做搜索推荐,这篇文章也是KDD2018的best paper,思路很清楚:把房屋用嵌入向量来表示,两个技巧:全局正样本和市场内负采样,很有效,离线评估指标:预定前的平均点击数量,非常的贴近业务。确实值的重温一遍。
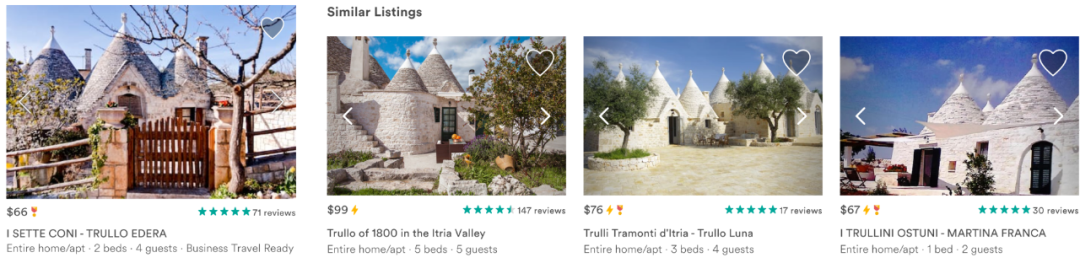
Airbnb的市场中包含了数以百万计的房屋,潜在客户通过复杂的机器学习模型搜索生成的结果来探索这些房屋,这些机器学习模型使用超过几百信号来决定在一个特定的搜索页面上,房屋是如何进行排序的。一旦客户查看了某个房子,他们要么返回,要么可以浏览类似的房子继续进行搜索,推荐的房子都是和用户查看的房子类似的。总的来说,搜索排名和相似房屋的推荐驱动了我们99%的预订转化。
在这篇博文中,我们描述了我们在Airbnb开发和部署的一种房屋嵌入技术,目的是改进搜索排名中的相似房屋推荐和实时个性化。嵌入是Airbnb房屋从搜索会话中学习到的向量表示,它允许我们衡量房屋之间的相似性。它们有效地编码了许多房屋的特征,例如位置、价格、房屋类型、结构和风格,所有这些都只使用了32个浮点数。我们相信,个性化和推荐的嵌入方法对于任何类型的在线市场中都是非常强大和有用的。
嵌入的背景知识
在许多自然语言处理(NLP)应用中,传统的语言建模方法将单词表示为高维稀疏向量,这种方式已经被学习单词嵌入的神经语言模型所取代,即通过使用神经网络来得到单词的低维表示。这些网络是通过直接考虑词序和它们的共现性来训练的,这里基于一个假设,即句子中经常出现在一起的单词也具有更多的统计相关性。随着用于单词的表示学习的高度可扩展的CBOW和Skip-gram语言模型的发展,嵌入模型已被证明,在对大型文本数据进行训练后,在许多传统语言任务中可以获得最先进的性能。
最近,嵌入的概念已经从单词表示扩展到NLP领域之外的其他应用中。来自Web搜索、电子商务和市场领域的研究人员已经认识到,就像可以通过将句子中的单词序列作为上下文来训练单词嵌入一样,也可以通过将用户操作序列作为上下文来训练用户操作的嵌入。例如,学习物品点击或购买或查询以及广告点击的表示。这些嵌入随后被用于Web上的各种推荐。
房屋的嵌入
假设我们给定一个数据集,有N个用户的点击会话,每个会话表示为 s= (L₁,…, Ln)∈S,定义为一个用户不间断的点击序列。只要用户连续两次单击之间的时间间隔超过30分钟,就会启动一个新会话。给定这数据集,其目的是学习一个32维的实数向量表示:v(Li)∈R²³,每个房屋都是不一样的,同时,类似的房屋在嵌入空间中靠的较近。
房屋嵌入的维数被设置为d = 32,因为我们发现这是离线性能(在下一节中讨论)和将向量存储在搜索机器的RAM内存中以进行实时相似度计算所需的内存之间的一个很好的平衡。
有几种不同的训练嵌入的方法。我们将重点介绍一种称为负采样的技术。它首先将嵌入初始化为随机向量,然后通过滑动窗口的方式阅读搜索会话,通过随机梯度下降来更新它们。在每一步中,它滑动窗口的中心房屋向量,让它更靠近正上下文向量,这些正上下文向量是在同一个滑动窗口(比如长度为5)中,中心向量之前和之后的向量,推动它远离负上下文向量,也就是随机选择的房屋,大概率和滑动窗口的中心房屋是没什么关系的。
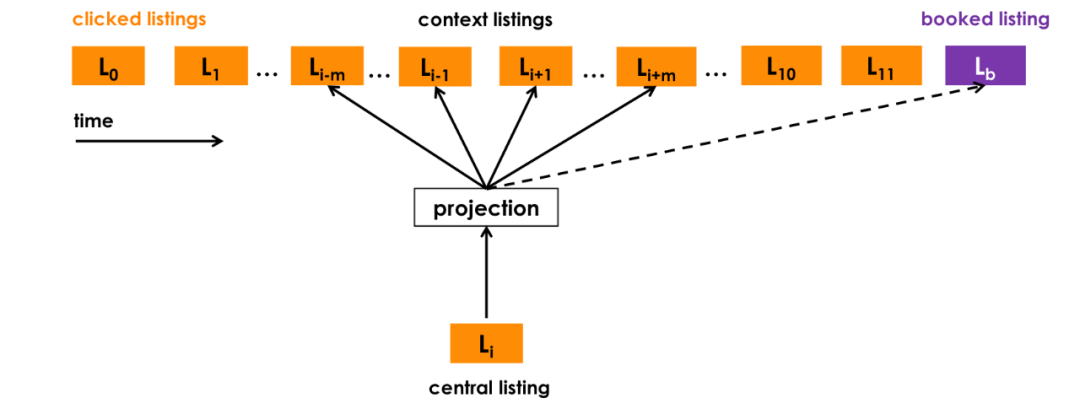
为了简单起见,我们将跳过训练过程的细节,重点解释我们为使这种方法适应我们自己的用例所做的一些修改:
-
使用已预订的房屋作为全局上下文:我们使用用户以预订为结束的会话来调整优化的过程,以便在每个步骤中,我们不仅能预测相邻的已单击的房屋,而且还预测最终已预订的房屋。当窗口滑动时,一些房屋会进入和离开上下文集合,而预订的房屋始终作为全局上下文(虚线)保留在其中,并用于更新中央清单向量。 -
自适应集中搜索:在线旅游预订网站的用户通常只搜索单一市场,即他们希望去的位置。因此,对于给定的中心列表,正样本上下文主要由来自同一市场的房屋组成,而负样本上下文主要由来自不同市场的房屋组成,因为它们是从整个房屋库中随机取样的。我们发现这种不平衡会导致学习市场内的次优相似性。为了解决这个问题,我们建议添加一组随机负样本*Dmn,*从滑动窗口的中心房屋的市场中采样。
综上所述,最终优化目标可表示为:
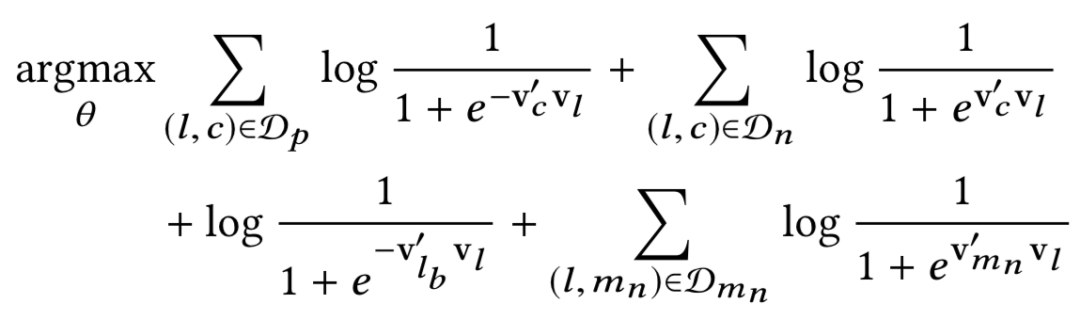
其中:
-
l是中心房屋,需要更新的向量为v(l)。 -
Dp是正样本对的集合(l,c),表示(中心房屋,上下文房屋),这两个向量需要拉近。 -
Dn是负样本对的集合(l,c),表示(中心房屋,随机房屋),这两个向量需要拉远。 -
lb是预定了的房屋,被当成是全局上下文,需要和中心房屋彼此拉近。 -
Dmn是市场内负样本对集合(l,mn),表示(中心房屋,市场内随机采样的房屋),这两个向量需要拉远。
使用上面描述的优化过程,我们学到了Airbnb上的450万个活跃房屋的嵌入,使用了超过8亿次搜索点击会话,产生了高质量的房屋表示。
嵌入冷启动,每天都有新的房源由房东创建并在Airbnb上发布。些房屋没有嵌入,因为它们没有出现在我们的训练数据中。为了创建新房屋的嵌入,我们找到了3个地理位置最接近的房屋,它们具有嵌入,并且与新房屋具有相同的房屋类型和价格范围,并计算它们的平均向量。
嵌入到底学到了什么?
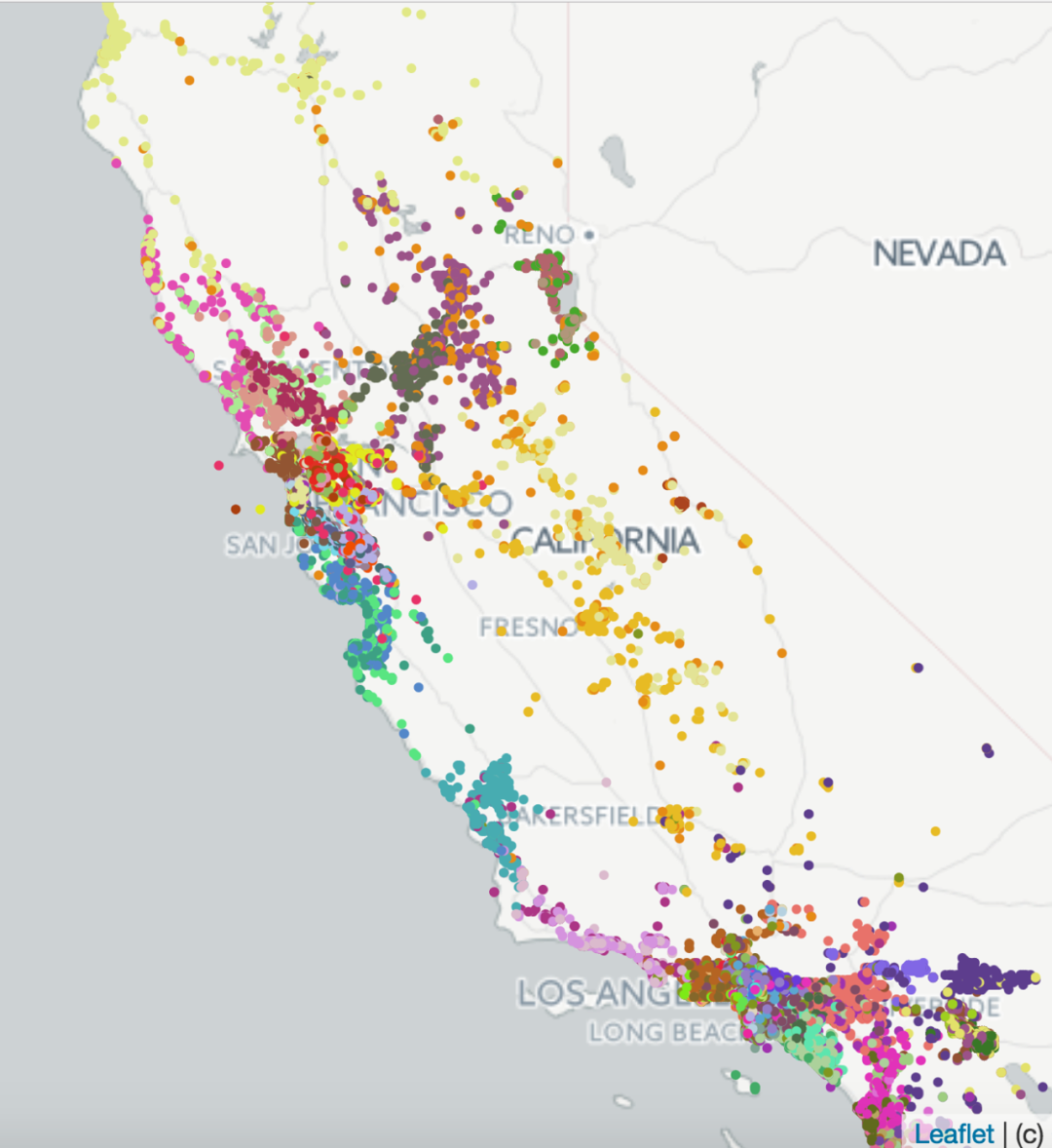
为了评估嵌入所捕获的房屋的特征,我们以几种方式对它们进行了研究。首先,为了评估地理相似性是否被编码,我们在已学习的嵌入上执行k-means聚类。左边的图显示了在加利福尼亚产生的100个聚类,证实了来自类似位置的列表是聚集在一起的。接下来,我们评估了不同类型的房源(全屋、私人房、共享房)和价格区间之间的平均余弦相似性,并证实了同类型房源和价格区间之间的余弦相似性要比不同类型房源和价格区间之间的余弦相似性高得多。因此,我们可以得出结论,这两个房屋的特征在已学习的嵌入中也得到了很好的编码。
虽然有些房屋特征(如价格)不需要学习,因为它们可以从房屋元数据中提取,但是其他类型的房屋特征(如结构、风格和感觉)则很难以房屋特征的形式提取。为了评估这些特征,并能够在嵌入空间中进行快速而简单的探索,我们开发了一个内部相似性探索工具,如下面的视频所示:https://youtu.be/1kJSAG91TrI
这个视频提供了许多嵌入的例子,可以找到相同建筑结构的相似房屋,包括船屋、树屋、城堡等。
房屋嵌入的离线评估
在用实际搜索流量上测试嵌入推荐应用之前,我们进行了几次离线测试。我们还使用这些测试来比较几个经过不同方式训练的嵌入,以快速做出关于嵌入维度、算法修改的不同想法、以及训练数据构造、超参数选择等方面的决定。
评估训练出的嵌入的一种方法是,根据用户最近的点击,测试他们在推荐用户将要预订的房屋方面做得有多好。
更具体地说,我们假设我们得到了最近点击过的房屋和需要排序的候选房屋,其中包含用户最终预订的房屋。通过计算被点击房屋和候选房屋的嵌入之间的余弦相似性,我们可以对候选房屋进行排序,并观察已预订房屋的排序位置。
在下图中,我们显示这样一个评估的结果,搜索结果基于在嵌入空间的相似性重新进行排序,预订了的房屋的排序结果序是按照每次预定前的点击数量的平均值来计算得到,最多追溯到预定前的17 次点击。
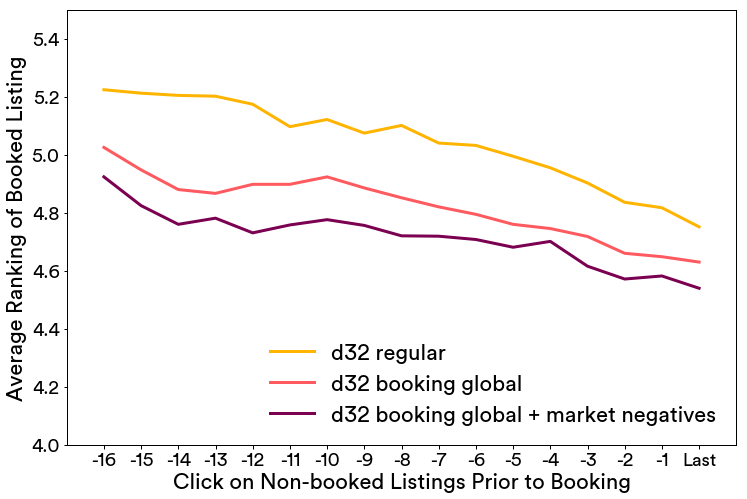
我们比较多个嵌入版本,1)d32正则,对原来的算法没有任何的修改。2) d32预订全局上下文 使用预定作为全局上下文进行训练。3)d32预订全局上下文+市场内负采样 使用预定作为全局上下文和市场内负采样进行训练。从持续较低的预订房屋前的平均点击次数我们可以得出结论,第3个模型优于其他两个嵌入模型。
使用嵌入进行相似性房屋推荐
Airbnb的每个房屋页面都包含相似房屋推荐,会推荐与之相似的房屋,并在相同的日期提供这些房屋。
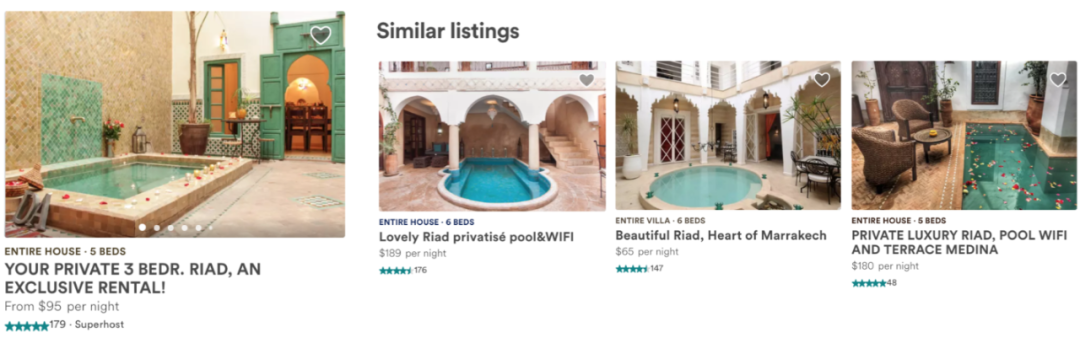
在测试embeddings时,针对相似房屋的现有算法包括调用我们的主搜索排名模型,搜索给定房屋的相同位置,然后过滤相同的价格范围和房屋类型。
我们进行了一个A/B测试,将现有的相似房屋算法与基于嵌入的解决方案进行了比较,在该解决方案中,通过在房屋嵌入空间中查找k个最近邻来生成相似的房屋。更精确地说,给定学习过的房屋嵌入,通过计算来自同一市场的所有房屋之间的余弦相似性,可以找到给定房屋的相似房屋。相似度最高的k=12个房屋显示为相似房屋。
A/B测试显示,基于嵌入式的解决方案使相似房屋的CTR增加了21%,并且4.9%的客人发现他们最终在相似房屋中进行了预订。
使用嵌入在搜索中实现实时个性化
到目前为止,我们已经看到嵌入可以有效地计算房屋之间的相似性。我们的下一个想法是利用此功能实时在会话中实现个性化搜索排名,的目的是给客人更多类似于那些我们认为他们喜欢的房屋,少给那些我们认为他们不喜欢的。
为了实现这一点,我们为每个用户收集并实时维护两组短期历史事件(使用Kafka):
-
Hc:用户在过去2周内点击的一组房屋id。 -
Hs:用户在过去两周跳过的一组房屋id,其中我们将跳过的房屋定义为那些排名高但用户跳过的房屋,跳过了之后去点击那些排名低的房屋。
接下来,每当用户进行搜索时,为每一个候选房屋计算2个相似度:
-
EmbClickSim:候选房屋嵌入和用户点击的房屋嵌入之间的相似性(来自Hc)。
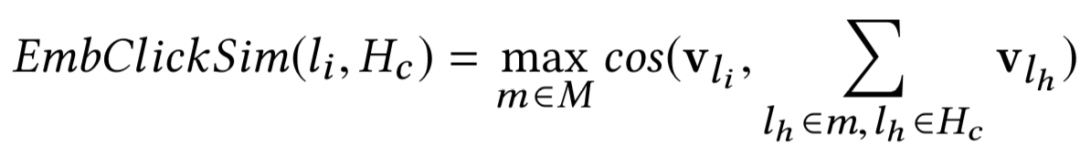
具体地,我们计算了来自Hc中的市场级别的中心房屋之间的相似性,并选择最大相似性。例如,如果Hc包含来自纽约和洛杉矶的房屋,这两个市场的房屋的嵌入将被平均,形成一个市场级的中心。
-
EmbSkipSim : 候选房屋嵌入和用户跳过的房屋嵌入之间的相似性(来自Hs)。
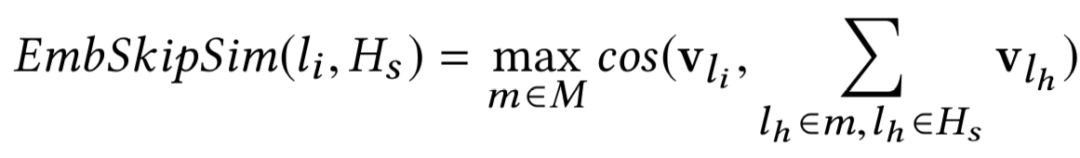
接下来,这两个相似度度量被引入,作为搜索排名机器学习模型在对候选房屋进行排名时考虑的附加信号。
首先,使用这个两个嵌入相似性特征以及其他搜索排名的特征,我们可以创建一个新的带标签的数据集来进行模型的训练,然后继续训练一个新的排名模型,我们可以在当前生产中进行排序模型的A / B测试。
为了评估新模型是否学会了按照我们的意图使用嵌入相似性特征,我们在下面绘制了它们的部分依赖关系图。这些图显示了如果我们只修改了一个特征(一个我们正在检查的特征),那么候选列表排名得分会发生什么变化。
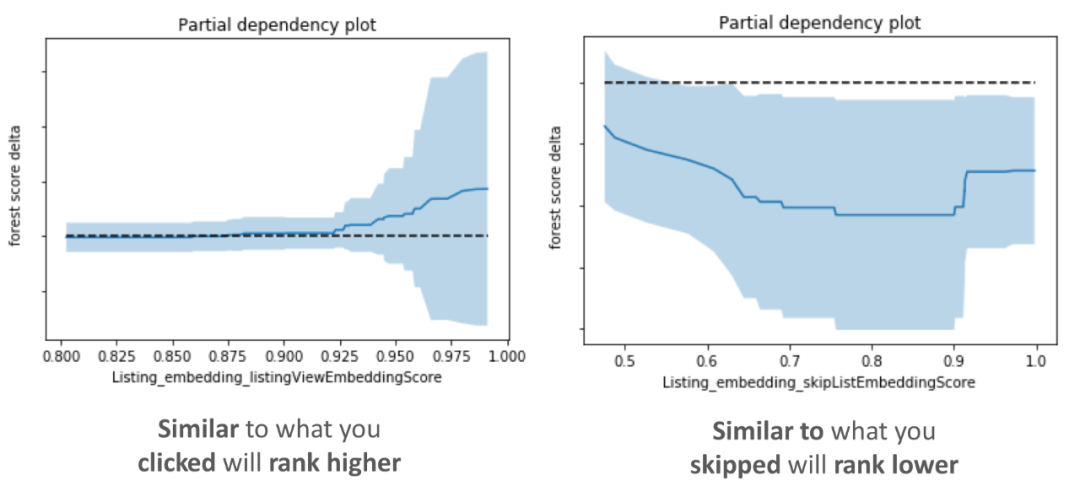
在左边的子图中可以看到,EmbClickSim的值越大(房屋与用户最近点击的房屋相似),模型得分越高。
在右边的子图中可以看到,EmbSkipSim的值越大(房屋类似于用户跳过的房屋,即不喜欢),模型得分越低。
来自部分依赖关系图的观察证实,特征行为符合我们对模型学习的直观预期。此外,新的嵌入特征在模型特征重要度中排名很高,我们的离线测试显示,当嵌入特征添加到模型中时,在保留测试集上的性能指标有了改进。这足以让我们决定进行一项“在线实验”,这项实验非常成功,因此实时个性化嵌入功能在2017年夏天投入生产。

英文原文:https://medium.com/airbnb-engineering/listing-embeddings-for-similar-listing-recommendations-and-real-time-personalization-in-search-601172f7603e
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




