一文全览,AAAI 2020上的知识图谱

作者 | Michael Galkin
编译 | 丛末
责编 | 贾伟
前几天,AI科技评论发了一篇图机器学习@ICLR 2020的文章。而在近期举行的AAAI 2020 上 图机器学习的研究也仍然是主流方向。在本届 AAAI上共有1591篇接收论文,其中有140篇是与图研究相关的。在此之外还有一些专门就图研究而开展的workshops和tutorials,包括:
-
Workshop on Deep Learning on Graphs (DLGMA) -
Tutorial on GNNs (with slides) -
Tutorial on Differentiable Deep Learning on Graphs (with slides) -
Statistical Relational AI (StarAI)
此外,还有一些图与NLP交叉的workshops/ tutorials:
-
Reasoning for Complex QA (RCQA) -
DeepDial -
DSTC8 -
Tutorial on Explainable AI
由此可见,图研究在当下已经成为主流热门研究领域。简直是「死生之地,不可不察」!
本文将介绍AAAI 2020 上的知识图谱研究。
关注「AI科技评论」微信公众号,后台回复「知识图谱@AAAI2020」下载论文合集。
一、不同风格的知识图谱增强语言模型
将结构化知识融入到语言模型的趋势发生在EMNLP 2019上,而2020年,可以肯定将是知识图谱增强语言模型(KG-Augmented LMs)的一年:更大规模的训练语料将与预训练模型一起出现。

论文链接:https://arxiv.org/pdf/1908.07690.pdf
Hayashi等人在其工作中为自然语言生成任务(以知识图谱为条件)定义了一个隐关系语言模型(Latent Relation Language Models,LRLMs)。知识图谱对关系、实体和关系的表面形式(surface forms)/同义词等有益,且能够在生成token时被融入到概率分布中。也就是说,在每一步中,模型要么从词汇表中提取一个单词,要么使用已知的关系。
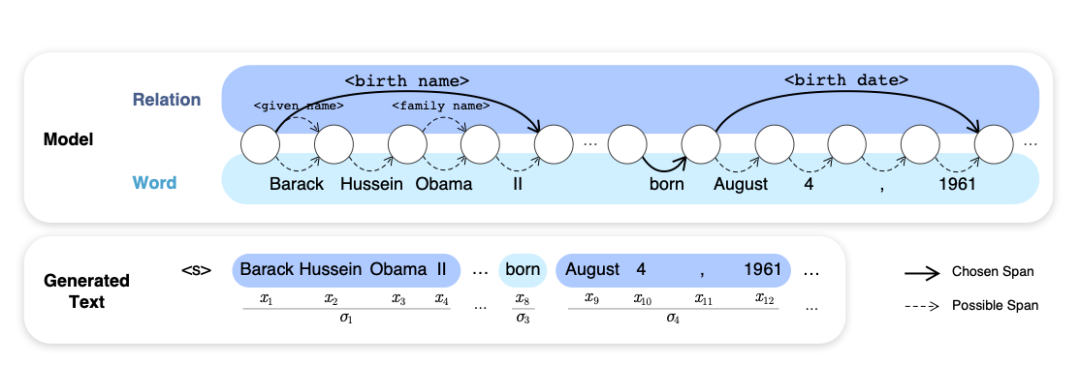
Source: Hayashi et al
最终的任务是生成一个与主题实体一致且正确的文本。LRLMs利用底层图上的知识图谱嵌入来获得实体和关系表示,以及用于嵌入表面形式的Fasttext。最后为了参数化流程,还需要一个序列模型。作者尝试使用LSTM和Transformer-XL来评估LRLM。实验显示,即使是大规模的Transformer也会从知识图谱中受益,性能上升,困惑度下降,生成的文本会比其他方法更具连贯性。It's great work!

论文链接:https://arxiv.org/pdf/1909.07606.pdf
Weijie Liu等人的工作(北大、腾讯和北师大共同完成),提出了一个称为K-BERT的模型,它假设了每个句子(如果有可能)都会用知识图谱中的一个命名实体或关联对来标注。
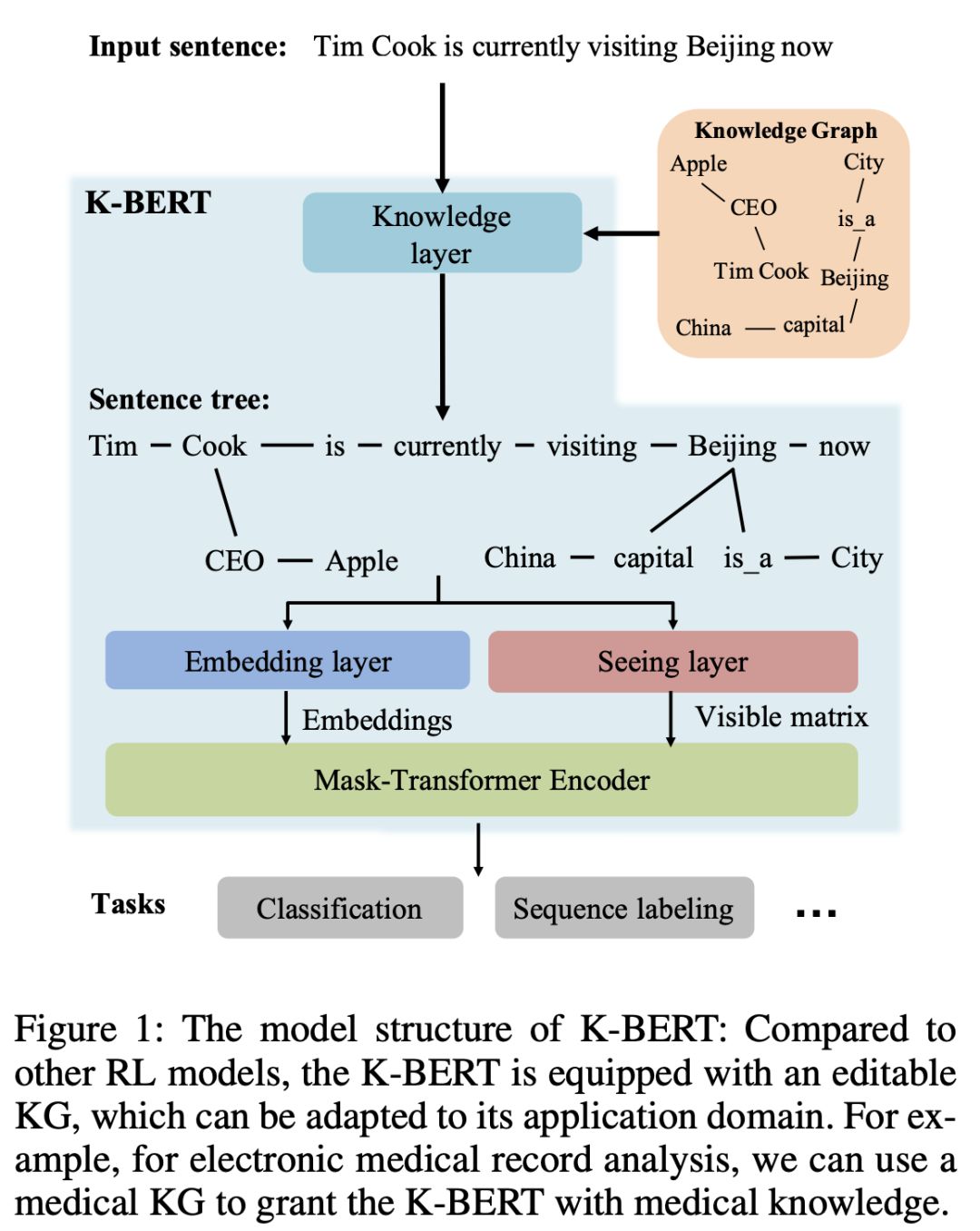
Source: Liu et al
丰富的句子树(如上图所示)随后线性化到一个新的positional-like的嵌入中,并被一个可见矩阵(visibility matrix)所遮盖,这个矩阵可以控制在训练期间输入的哪一部分可以被看到。事实上,作者明确提到,知识融合只在微调阶段发生,而预训练与标准BERT完全一样。作者融合了开放领域和医疗领域的知识图谱,实验观察到所有评估任务在一致性上都有1%-2%的提升。

论文链接:https://arxiv.org/pdf/1907.12412.pdf
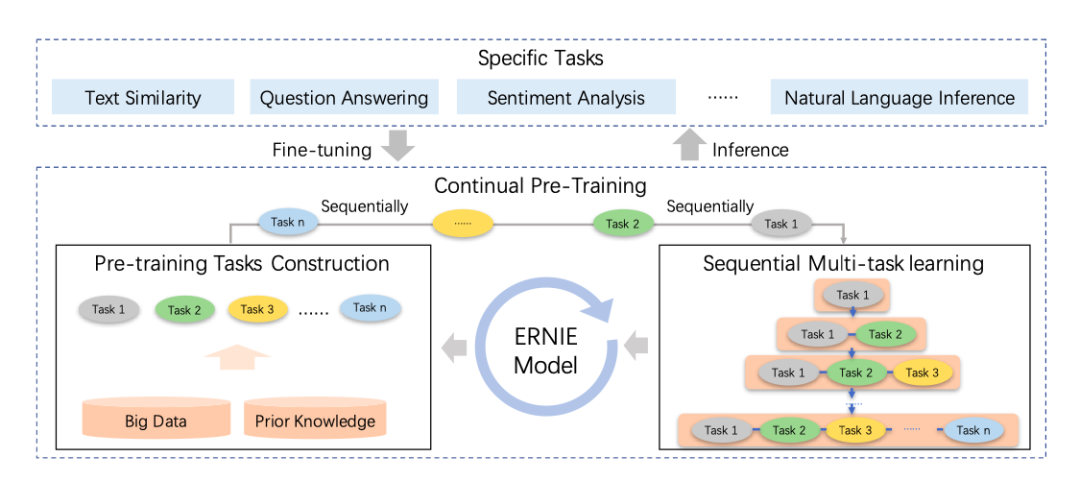
ERNIE 2.0 框架,Source Sun et al.
百度在相似性融合方面做了不少工作,他们在本届AAAI上介绍了 ERNIE 2.0。这是一个整合外部知识的扩展方法,与ERNIE 1.0相比,它可以捕获更多的词汇、语法和语义信息。

论文链接:https://pasinit.github.io/papers/scarlini_etal_aaai2020.pdf
开源地址:http://sensembert.org/
Scarlini等人将BERT与语义网络BabelNet和NASARI一起应用在他们的SensEmBERT模型中,这个模型能够在多种语言中进行词义歧义消除和词义表示。
作者还指出,SensE没BERT在WSD任务中能够更好地支持不常见词,并优于定制的监督方法。目前这个模型是开源的。

论文链接:https://arxiv.org/pdf/1911.12753.pdf
Bouraoui等人进一步对BERT的关系知识进行了评估,即在给定一对实体(例如法国-巴黎)的情况下,它能否预测正确的关系。作者发现,BERT在事实和常识任务中表现良好,在词汇任务中表现也不错,在形态任务中就更出色了。这实际上也是用知识图谱来增强语言模型的一个重要动机。
二、异质知识图谱中的实体匹配
不同的知识图谱都有他们自己的实体建模的模式,换句话说,不同的属性集合可能只有部分重叠,甚至URLs完全不重叠。例如在Wikidata中Berlin的URL是https://www.wikidata.org/entity/Q64,而DBpedia中Berlin的URL是http://dbpedia.org/resource/Berlin。
如果你有一个由这些异质URL组成的知识图谱,尽管它们两个都是在描述同一个真实的Berlin,但知识图谱中却会将它们视为各自独自的实体;当然你也可以编写/查找自定义映射,以显式的方式将这些URL进行匹配成对,例如开放域知识图谱中经常使用的owl:sameAs谓词。维护大规模知识图谱的映射问题是一个相当繁琐的任务。以前,基于本体的对齐工具主要依赖于这种映射来定义实体之间的相似性。但现在,我们有GNNs来自动学习这样的映射,因此只需要一个小的训练集即可。

论文地址:https://arxiv.org/pdf/1911.08936.pdf
Sun等人提出了AliNet模型,这是一个端到端的基于GNN的框架,能够为实体对齐聚合远程多跳邻域。由于模式异质,这个任务变得更加复杂,因为不同知识图谱中相似实体的邻域不是同质的。
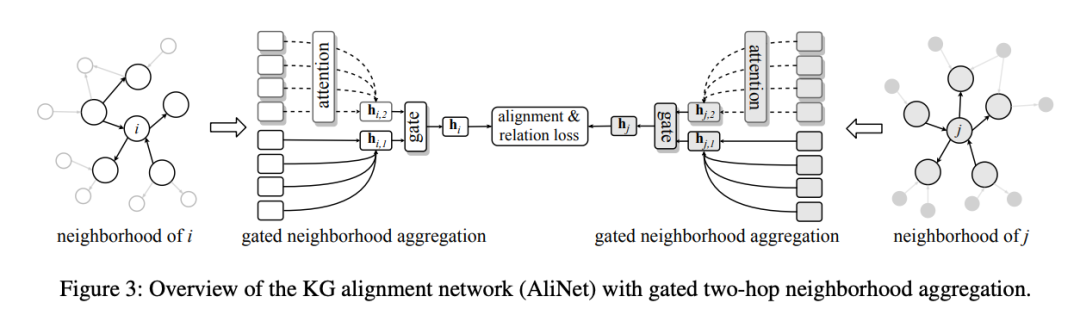
Source: Sun et al
为了弥补这一缺陷,作者建议关注节点的n-hop环境以及具有特定损失函数的TransE-style关系建模。最后,门函数会控制一个节点从1-hop、2-hop、3-hop邻域中获得更多信息。AliNet在DBpedia多语言版、DBpedia -Wikidata、 DBpedia -YAGO等数据集上都进行了评估。众所周知,DBpedia、Wikipedia、YAGO有着完全不同的模式。但他们的结果达到了令人吃惊的90+% Hits@10的预测精度,完全不需要手工哦!

论文链接:https://arxiv.org/pdf/2001.08728v1.pdf
Kun Xu等人研究了多语言知识图谱(本例中为DBpedia)中的对齐问题,在这个问题上基于GNN的方法会陷入“多对一”的情况,当给定一个目标实体时会生成多个候选的源实体。
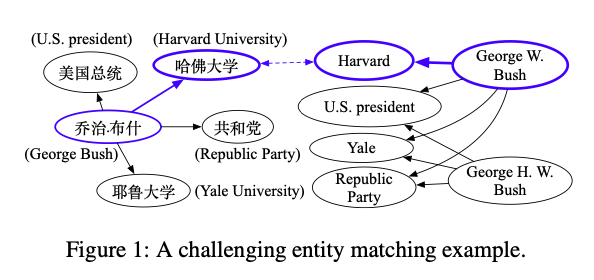
Source: Xu et al
作者研究了如何使GNN编码输出的预测更加具有确定性(因此也即增加Hits@1的评分),他们提出了两种策略:
1、Easy-to-Hard解码,从本质上讲,即一个two-pass过程,第一步会调用一个对齐模型;第二步,把概率值高于阈值 𝛕 的K个候选者添加到基线中,然后再次执行对齐模型。
2、使用匈牙利算法来寻找候选对的最佳分配。由于匈牙利算法具有 O(N⁴) 的时间复杂度,作者先利用概率超过阈值 𝛕 的方法大幅降低了候选子空间,这能够使算法在合理的运行时间里进行。
他们的实验结果表明,底层依赖GNN的模型和任务,可以在Hits@1时能够获得3%-5%的性能提升。
三、知识图谱补全和链接预测
在本届 AAAI 2020 上,有两个发展趋势非常突出:神经–符号计算(neuro-symbolic computation)重回大家的视野并且大热;时间知识图谱(temporal KG)的吸引力也越来越大。

论文链接:https://arxiv.org/pdf/1912.10824.pdf
针对神经–符号范式,Pasquale Minervini 等人在论文中,将神经定理证明(NTPs)扩展为了贪心的神经定理证明(GNTPs)。NTPs 是一个端到端的可微系统,学习规则并在给定知识图谱剩余部分的情况下尝试证明事实。
虽然NTPs 能够实现可解释性,但其复杂性会随着知识图谱的大小急速增长,并且研究者们还无法在较大的数据集(但也谈不上像维基数据那样的整个知识图谱)上对NTPs进行评估。
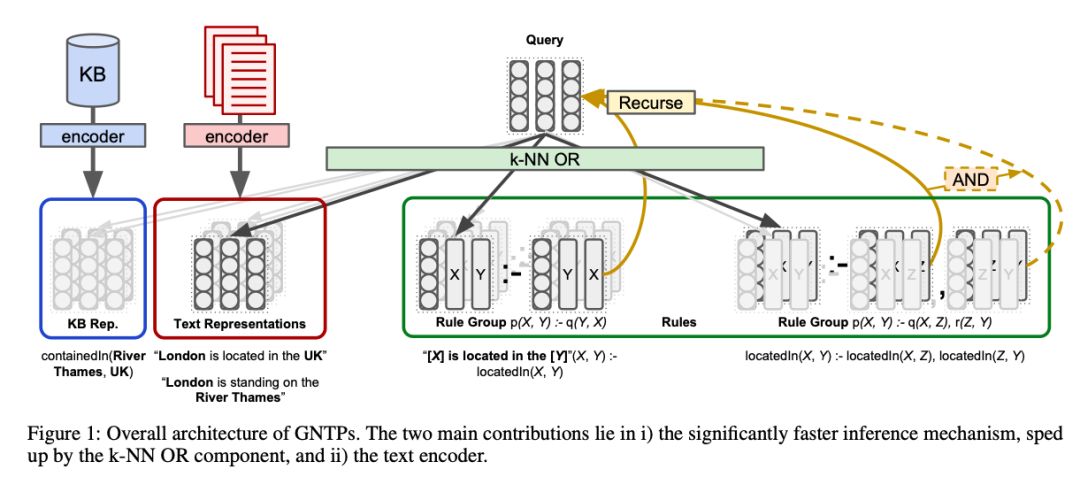
Source: Minervini et al
为了解决这一问题,论文作者推导出了一个贪心的邻近算法(kNN)策略来选择能够最大化证明分数的事实,从而GNTPs 更具可扩展性得多。同时,除了 (s,p,o) 三元组外,作者还可以用自然语言来表示规则,例如“伦敦坐落于英国”。
在链接预测任务的实验过程中,作者发现,即便只用一个简单的嵌入模型对上述提到的文本编码,也能够得到明显更好的结果。

论文链接:https://arxiv.org/pdf/1907.03143.pdf
知识图谱通常包括仅在一定时间内有效、随后更新为新的值的事实,例如,关于Albert Einstein 配偶的事实,一开始为(Albert Einstein,配偶:Mileva Marić,从1903年到1919年),之后更新为(Albert Einstein,配偶:Elsa Einstein,从1919年到1936年)。
也就是说,根据年份和时间的不同,知识图谱对应的链接有时是正确的,有时是错误的,而这种时间维度在企业知识图谱中,也特别重要。
与仅考虑静态图的传统知识图谱的嵌入方法不同,结合时间知识图谱的嵌入方法要求模型在给定一定的时间窗口下,对链接进行加权。
加拿大皇家银行旗下人工智能研究所 Borealis AI 的研究者 Rishab Goel等人提出了SimplE模型的扩展版本——DE-SimplE,可通过历时实体嵌入来支持知识图谱的时间维度,其中实体维度 D 外的 𝛾d 维度可以捕获时间特征,而(1-𝛾)d 维度则能够捕获静态的知识图谱特征。
当然随着时间的推移,我们会看到动态知识图谱的模型也会日益发生变化。

论文链接:https://arxiv.org/pdf/2001.00461.pdf
来自西门子中国研究院和慕尼黑大学的研究者 Marcel Hildebrandt等人从新的视角研究事实分类,让人眼前一亮。在论文中,他们提出采用R2D2算法中的辩论动态(Debate Dynamics )方法,其中两个Agent 通过证明或反驳给定的三元组进行“辩论”,同时最终由一个 Judge (作为一个二元分类器)决定三元组是真还是假。
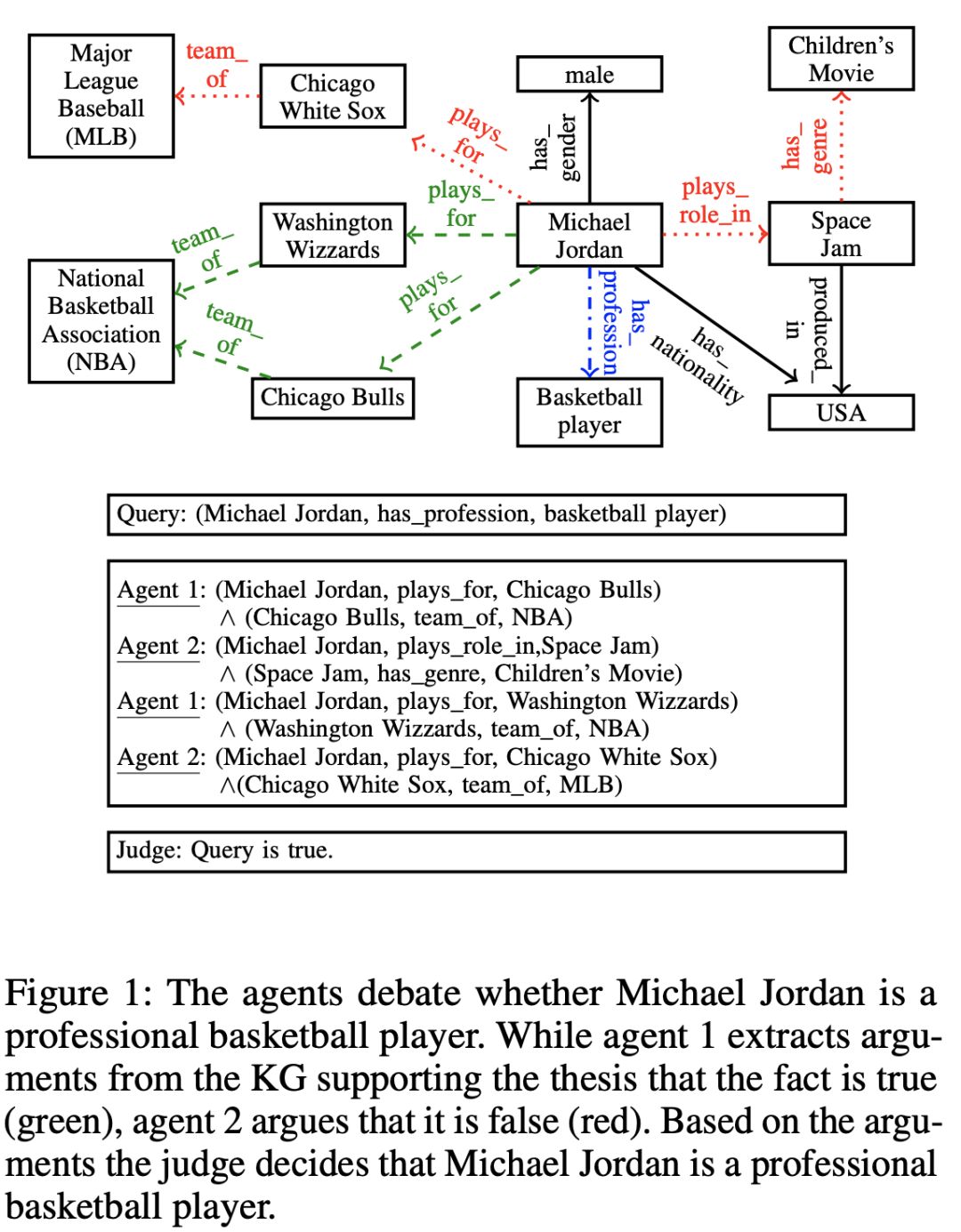
Source: Hildebrandt et al
该系统经过强化学习训练,除了三元组分类外,还能够通过调整来完成链接预测任务。
作者也开展了一项调查,以找到人类评估者评估检察官和辩护人提出的论据的方法。而作为规则挖掘系统中的一个普遍问题,R2D2 的扩展性也将会是一个有趣的研究主题。

论文链接:https://arxiv.org/pdf/1910.02915.pdf
常识知识图谱如ConceptNet、ATOMIC现在也已经在许多自然语言处理任务中得到应用,但是至今还未对其链路预测和补全特点进行深入研究。
艾伦人工智能研究所的研究者Chaitanya Malaviya 等人在论文《Commonsense Knowledge Base Completion with Structural and Semantic Context》中展示了,例如 DistMult 或 ConvE 等传统的知识图谱嵌入算法,由于知识图谱的稀疏性( 例如数据集FB15K-237的密度大概是1.2e-3,平均入度为 17;而 ATOMIC的密度为 9e-6 ,平均入度为2.25),得到的结果并不好。
作者认为,研究者还需要考虑到结构和语义的上下文,从而在其提出的模型中,使用R-GCN来聚合邻域信息以及使用BERT 来编码短语和文本。
除此之外,作者还对R-GCN的诱导边界(概率分数超过了一定的阈值)和子图采样进行了综合实验。
这篇论文读起来非常有冲击力,架构清晰、概念解释到位、具有完整的实验和分析,这项研究工作可以说是非常好了!
此外,一些短论文提出的算法,或许也会对大家有所帮助,例如:

论文链接:https://arxiv.org/pdf/1911.00219.pdf
这篇论文提出了ConvE的优化版本——InteractE,其结合应用了各种重塑策略和循环卷积,在基准测试中的表现始终优于 ConvE。

论文链接:https://arxiv.org/pdf/1911.09419.pdf
Zhang等人在其提出的模型 HAKE 中对 RotatE 算法进行了扩展,以更好地对知识图谱的层次关系建模,从而能够在更广泛项的嵌入内,找到更窄的项嵌入。
四、基于知识图谱的对话 AI 和问答
今年AAAI 2020 会议还举办了主题为“Dialogue State Tracking”的研讨会 (DSTC8),该议程汇聚了来自Google Assistant、 Amazon Alexa和 DeepPavlov 研究团队的对话 AI 领域的专家。
在 DSTC研讨会中,社区的研究者致力于获得更大、更丰富的数据集,同时也致力于解决更复杂得多的任务。

论文链接:https://arxiv.org/pdf/1909.05855.pdf
谷歌软件工程师Abhinav Rastogi等在论文中,提出了Schema-Guided Dialogue (SGD)数据集。迄今为止,SGD数据集是最大的多领域数据集,拥有 16个不同领域超过 1.6万个对话。SGD数据集中的数据没有统一的格式,16个领域的数据从 Freebase获取,各自都有自己的格式表述。
事实上,这个数据集如此之大,以至于没有人能够穷尽其中可能存在的槽值,或者保证其测试集能够覆盖所有可能的服务/槽/值组合数据。
这种情况下,大家可能希望能够有一些零样本状态可以追踪到这些组件。
下图展示了 25 个挑战赛团队实现的结果,他们将基线的最低分数从20–60%提高到了86–99%,可喜可贺:
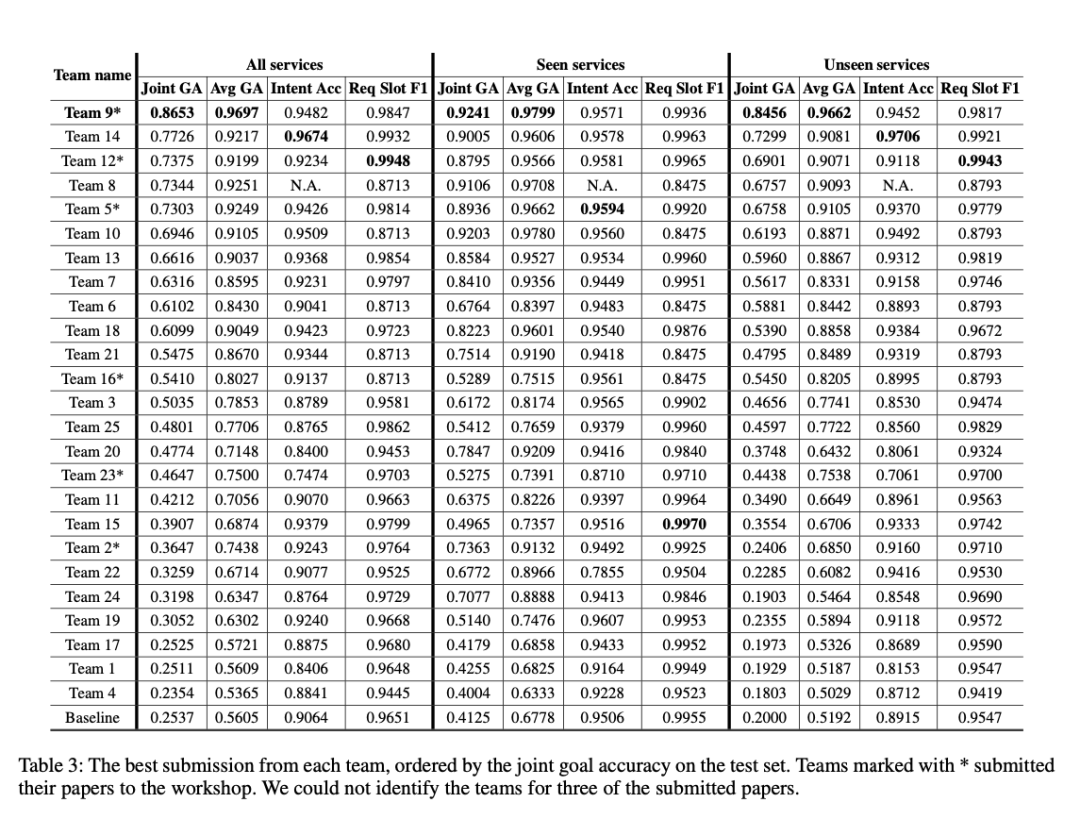
Source:https://arxiv.org/pdf/2002.01359.pdf
下面介绍一些令人激动的知识图谱应用。

论文链接:https://arxiv.org/pdf/1912.07491.pdf
西南科技大学、中国科学院、腾讯 AI Lab等机构联合发表的论文中,提出了一种被称作TransDG的模型,可用于闲聊对话机器人的回应生成,其中主要的方法是,从在SimpleQuestions、Freebase和 ConceptNet数据集上经过训练的 KGQA 系统迁移事实知识。
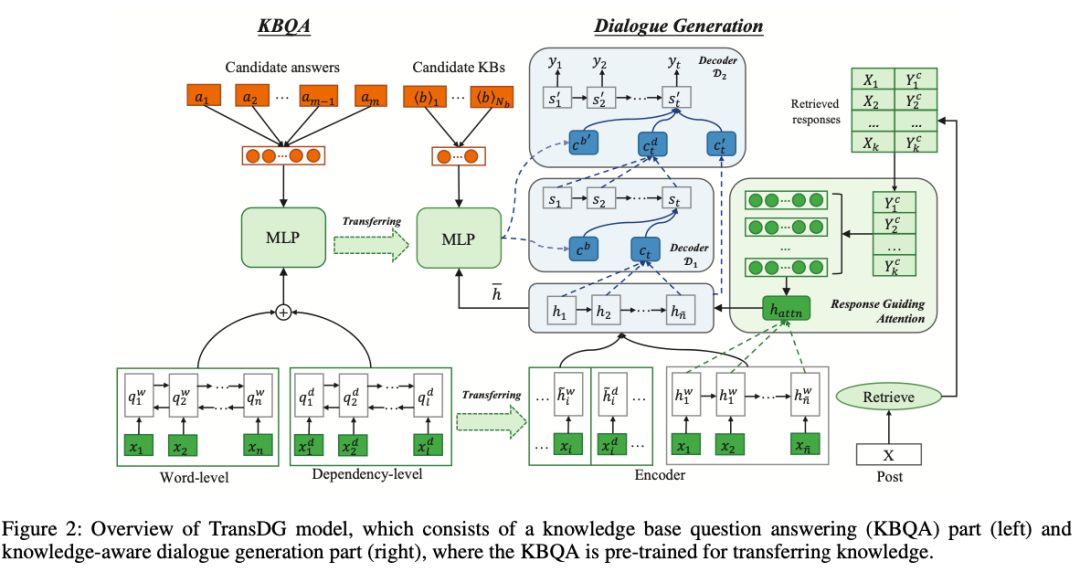

论文链接:https://arxiv.org/pdf/1912.01496.pdf
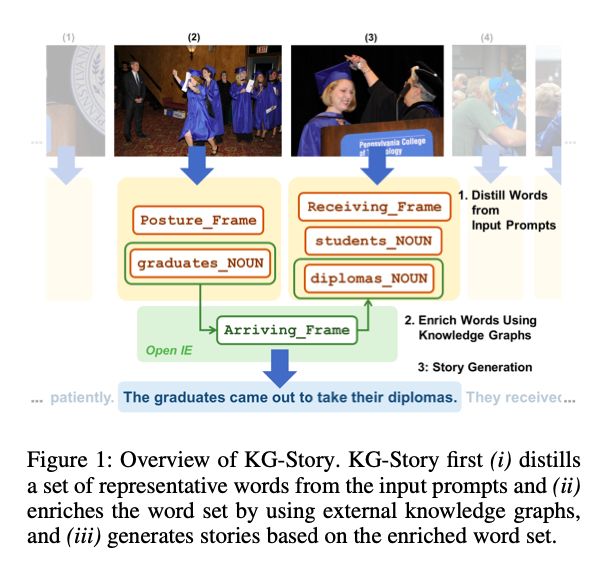
科罗拉多大学、国立中央研究院、宾夕法尼亚州立大学等机构联合发表的论文定义了一个“看图讲故事”的框架——KG-Story,该框架能够基于连续的图片,生成一个连贯的文本描述。此外,该框架采用知识图谱进行自我丰富,有助于图像场景的理解和文本生成。
在知识图谱问答领域,南京大学孙亚伟等人在《 SPARQA: Skeleton-based Semantic Parsing for Complex Questions over Knowledge Bases》论文中,针对知识图谱的复杂问答任务,提出了一种基于 Skeleton的语义短语表示和解析方法—— SPARQA。
作者通过 Skeleton 理解一系列最小化的语义单元(如VP、NP、PP等等)和一些依附关系,其中依附关系创建了查询树的原型(随后会被实例化并发送到一个知识图谱查询引擎中)。此外,他们还在 Freebase知识库中的GraphQuestions 和 ComplexWebQuestions 上对该方法进行了评估。

论文链接:https://arxiv.org/pdf/1909.05311.pdf
在常识问答领域,中国科学院Shangwen Lv等人在论文中,使用常识知识库ConceptNet和维基的 IR 库挖掘了一些证据知识,并通过 GCN将这些知识传递。另一方面,基于 XLNet 的推理模块解码问题、选择以及找到的证据,已获得联合表示。该方法获得的 F1 分数为 75.3%,目前排名第 2 !
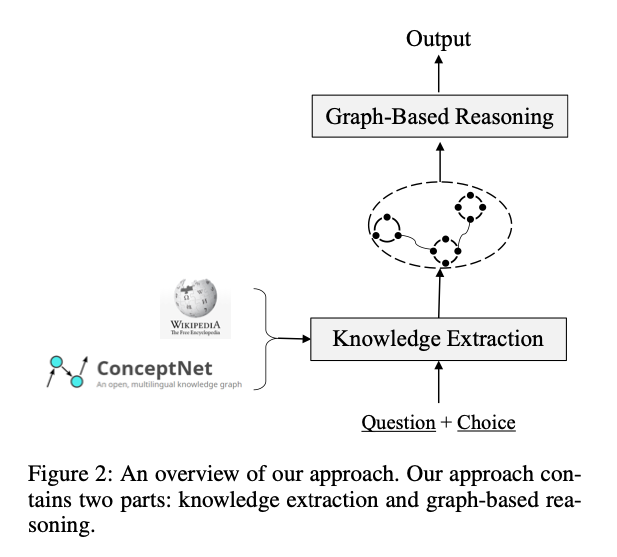
Source:Lv et al.
五、结语
本文主要介绍了下知识图谱在自然语言相关任务中的应用。当然,知识图谱在其他领域也有应用,例如在计算机视觉中,知识图谱能够帮助构架场景图;在生物信息学中,知识图谱有助于该领域的分子研究。
日益壮大的图机器学习社区,现在已经在日益对该领域展开深入研究,大家感兴趣地话可以搜集相关的资料进行了解,例如 GitHub 上就有一个图机器学习的文献库(https://github.com/naganandy/graph-based-deep-learning-literature),汇总了来自顶尖会议和来自Telegram的图机器学习频道的相关论文。
针对图机器学习,Sergei Ivanov也写过一篇关于图机器学习2020 年发展趋势的文章,非常不错。
AAAI 2020 之后,ICLR 2020 也将在今年 4 月份如期而至,相信会出现更多令人耳目一新的关于知识图谱的论文,大家拭目以待!







