KDD 2020 | 优势特征蒸馏在淘宝推荐中的应用

本期我们来看一篇又双叒叕来自于阿里巴巴的工业paper,被KDD 2020所接收。一眼望去题中有两个关键词,Privileged Features 和 Distillation,来,我们逐个击破。

论文:https://arxiv.org/abs/1907.05171
通俗版
先说Distillation,大家心里可能就已经有了一个初步的模型框架了。没错,蒸馏嘛,就是这样:
额,错了错了,是这样:
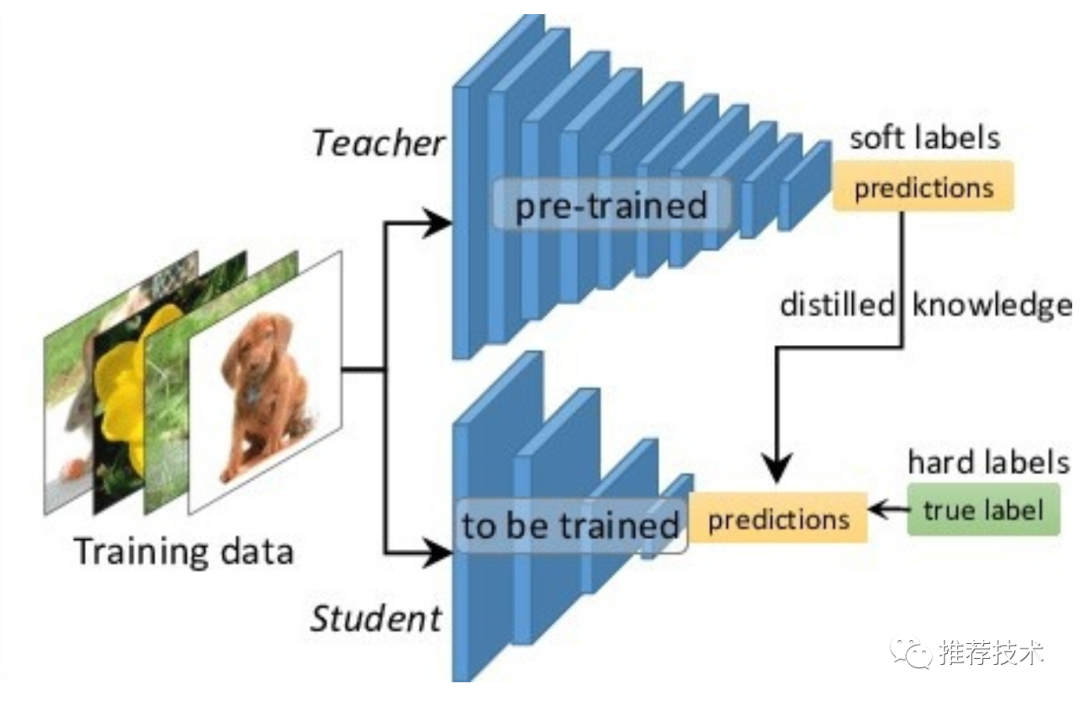
所以就是一个老师教学生好好学习的过程,用专业点的话说,就是知识迁移。
那啥叫Privileged Features?作者说,你们之前模型用的那些在线特征啊,Naive,比如你知道用户停留时长这个指标对于CVR的预测有多重要吗?你可能会说了,线上服务时我们没法拿到停留时长这样的后验特征啊,那为了保持线上线下特征的一致性,只能忍痛割爱。你说对了,这种信号强,但又不听话只能离线获取的特征,就叫优势特征。
于是本文的工作就是让老师去学习这些不听话的特征,然后把知识嚼碎了喂给学生,让学生在预测过程中获得更好的效果。

再来详述一下这个过程。在离线环境下,会同时训练两个模型:一个学生模型和一个教师模型。其中教师模型额外利用了优势特征,则准确率更高。将教师模型蒸馏出来的知识传递给学生模型,辅助其训练,提升学生的准确率。线上服务时,只用学生模型进行部署,由于输入中不依赖优势特征,则保证了线上线下特征的一致性。本文中的蒸馏知识是通过教师模型中的最后一层输出进行传递。作者给这个模型起名为PFD。
和一般的蒸馏模型(MD)不同的是,一般我们在MD中,教师和学生用的是相同的输入特征,而模型复杂度有差异,比如教师模型往往用更深的深度网络,来指导浅层网络的学生模型。在PFD中,教师和学生的网络模型是一致的,输入特征却不一致。MD和PFD的对比如下图:
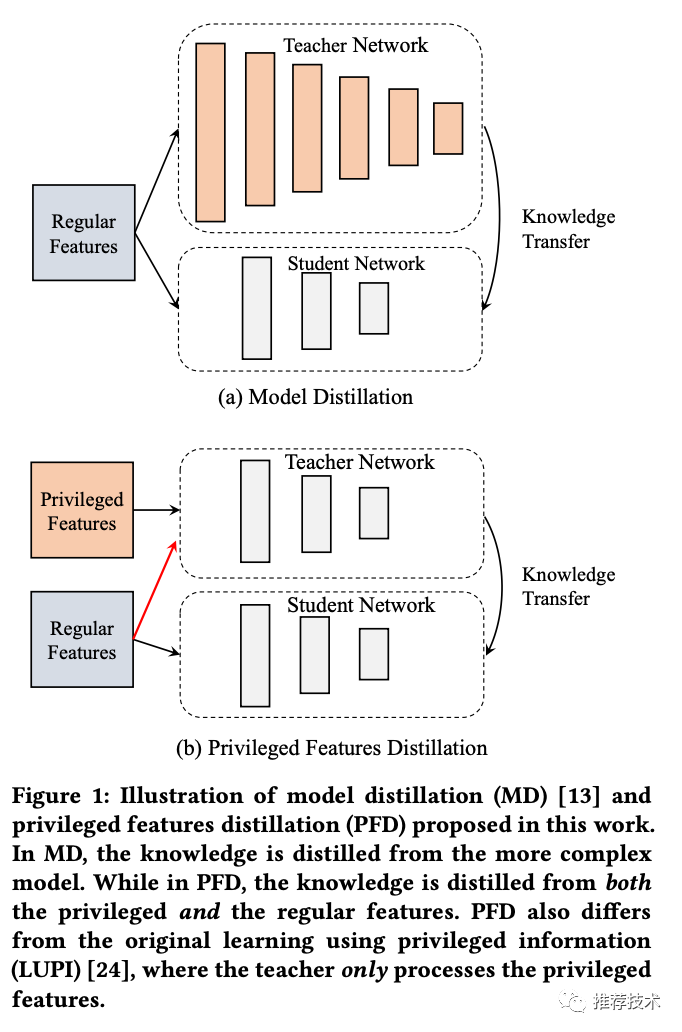
当然啦,作者也尝试了MD+PFD的套餐组合,进一步升级了模型,取得了更好的效果。叠加大法就是好~

效果自然是棒棒咯。本模型在手淘的信息流推荐场景,运用在了粗排阶段的CTR预估、和精排阶段的CVR预估两个阶段上。在AB测试下,粗排阶段的CTR有5%的提升,精排阶段的CVR有2.3%的提升。
其实这篇文章的解析到此可以结束了,但不排除有一些积极向上的同学,一定非常想了解模型的细节和更多的奥妙之处,那,那我也只能勉为其难继续啃原文(非常期待以后有中文写作的会议。。。)

专业版
好了,下面进入VIP用户时间。VIP多了些啥?先给你们画个大饼。
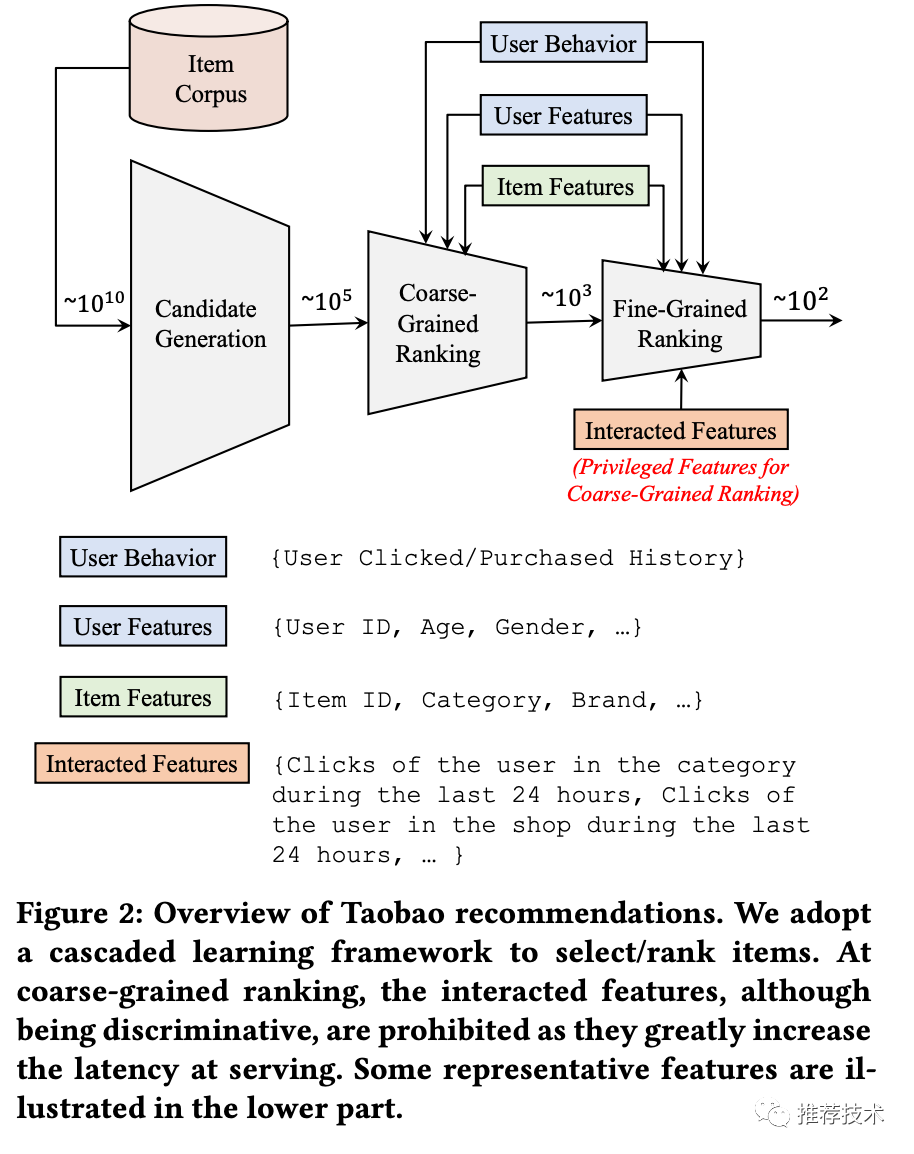
来看,这张图就是手淘推荐的流程框架图。所有的商品从入池到推荐给用户,会经历三个阶段:召回、粗排、精排。这三个阶段待打分的商品数会逐渐减少,模型会越来越复杂。
粗排:作为夹心饼干的中间层,粗排其实是有点小尴尬的。粗排的做法是传统的内积模型,把用户侧和商品侧作为双塔,在请求时,把用户侧的向量和候选商品向量进行内积运算,从而对商品池做粗筛。有一些交叉特征是对粗排效果影响明显的,比如用户在过去24个小时内在待预估商品类目下的点击次数。但是复杂的交叉特征会增加线上的推理延时,所以不能作为常规特征来训练。于是交叉特征就成为了粗排阶段的优势特征。

精排:在精排阶段,用户在商品页的行为对CVR的预估非常有用,但是线上服务时是无法获取这类后验特征的。于是在精排CVR预估中,这类特征就是优势特征。

蒸馏:下面介绍蒸馏方法。令X表示普通特征,X*表示优势特征,y表示标签,L表示损失函数,则特征蒸馏的目标函数抽象如下:
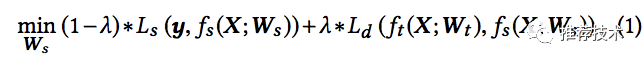
其中下标s表示student,d表示distillation,t表示teacher。从公式可以看出,教师网络的输入里包含普通特征和优势特征。这个公式下是将教师网络先训练好,然后指导学生网络。也可以同步更新教师网络和学生网络,减少训练时长,则公式如下:
作者提到了这种方法可能带来训练的不稳定,尤其是训练初期,教师模型自己还没有学好,就来指导学生模型,是有可能导致训练偏离正常的。因此λ参数就很重要,初期可以设为0。算法流程如下:

统一蒸馏:走到这里,可以考虑将MD和PFD合在一起做进一步提升了。更强的教师模型怎么选择呢?这里感觉还是比较巧妙的,本文直接拿精排的CTR模型来做粗排的教师模型,所以也就是让粗排反向学习精排的打分结果。
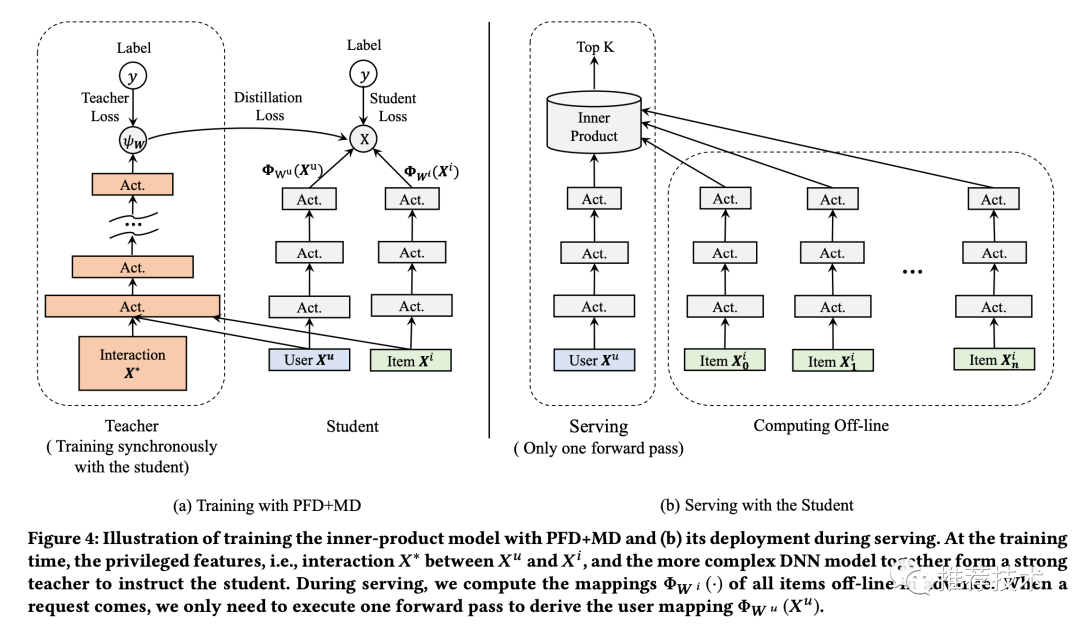
在精排阶段的蒸馏,还是如之前所述,主要是考虑了一些后验特征。那整个粗排+精排阶段的模型框架,就是这样:
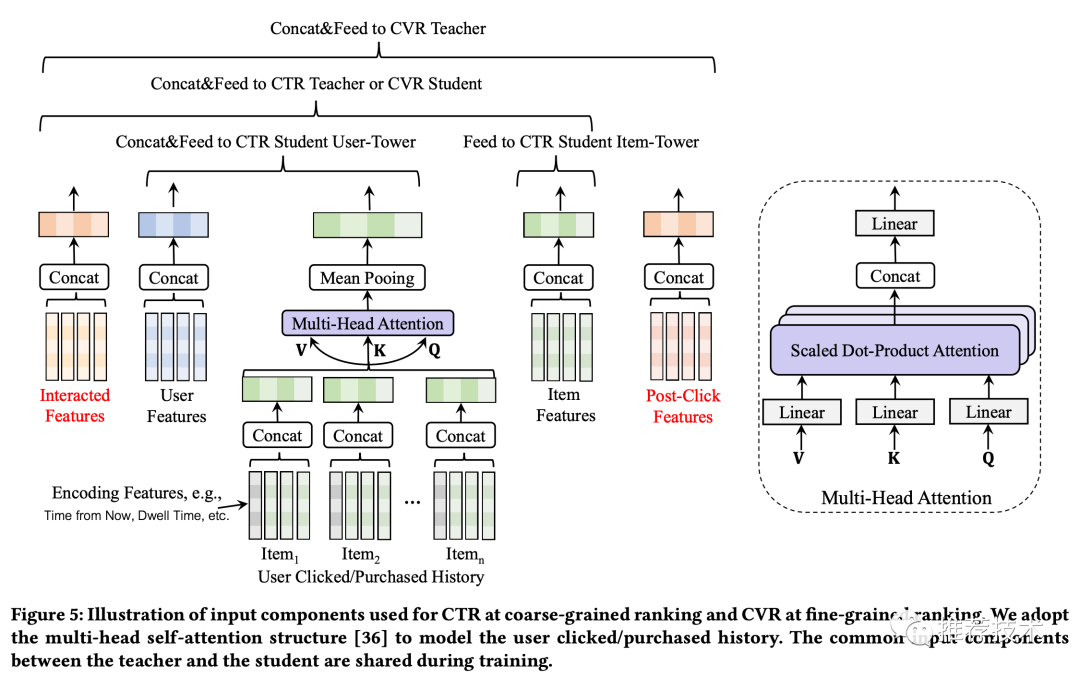
别慌,你品,你细品,一定是能看懂的。
实验:实验部分我们主要看下AUC,毕竟我们知道,在现在推荐模型已经比较成熟的情况下,AUC的提升已经日趋艰难。一个很明显的现象是,随着训练天数的增多,模型的优势会增大。
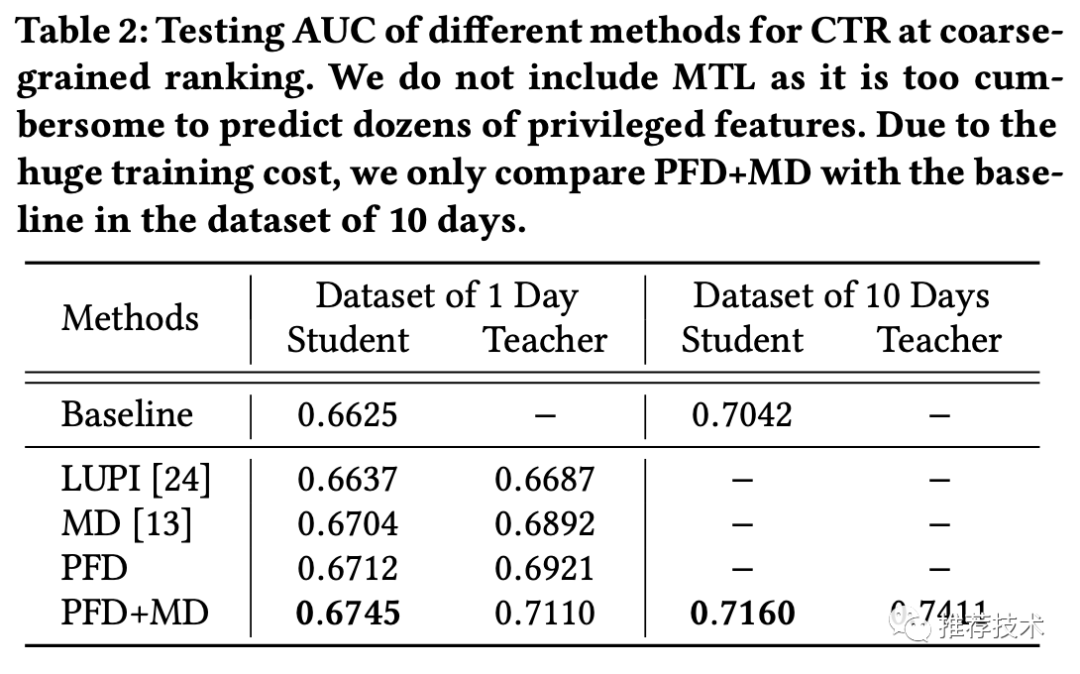
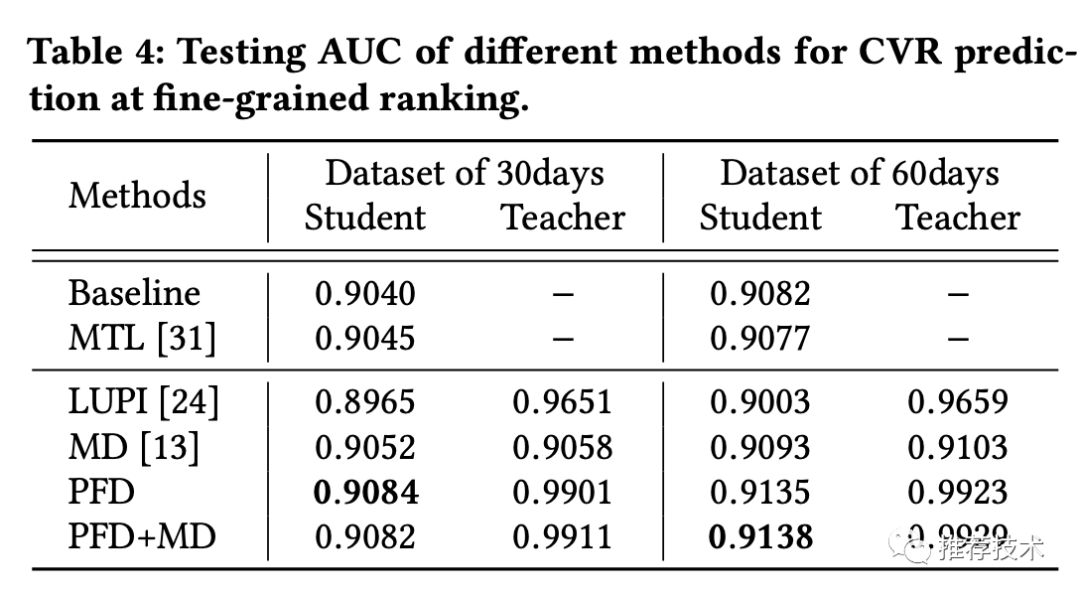
线上的效果也有相应的提升,在一开始我们就总结了,粗排阶段的CTR有5%的提升,精排阶段的CVR有2.3%的提升。
好了,到了总结时间。总的来讲这篇文章不难读,思路也比较朴素,对于工业应用还是比较有借鉴意义的。难度可能还在于实践,毕竟教育是一件很困难的事情,老师自己什么水平知道不?老师的教育水平怎样知道不?学生学成啥样知道不?学生在外怎么造作知道不?这些都是不可控因素。不管怎样,了解了蒸馏大法在推荐中的应用,也是埋下了一颗种子,提供了一个思路,不多说,撒花,庆祝~!

参考文献
1. Privileged Features Distillation at Taobao Recommendations
推荐阅读
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


