从XGB到LGB:美团外卖树模型的迭代之路

更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
整体内容会分成以下四个部分阐述:
一、业务背景
二、树模型及现在大家常用的 XGB 模型
三、LGB 模型一些特点以及落地过程当中的问题
四、未来规划
从第三方 TrustData 的数据来看,今年外卖商家版用户数持续增长,日活商家用户达到 91.5 万,显著超出竞对的。美团基本覆盖了市场上 8 成的商家。从外卖用户的角度来看,从 2017 年初已来美团外卖用户的 30 日复访天数也是长期较高的。所以我们在商户量和用户留存两个点上做的还是不错的。
下面我们看下一个典型业务里面可能会遇到的跟预估相关的问题,大概分为几方面:
第一,用户增长,我们怎么样进行新用户的吸引,获得更多 DAU
第二,用户进来之后,会有流量承载和流量分发模块,提供更好的体验
第三,商业变现,当一个平台成长到一定阶段以后,会进行商业化
第四,商户赋能,最近比较火,比如说我们商家需要进行一些活动,广告主进行广告购买,我们就需要提前给它做针对性建议,平台掌握了大量的数据,可以通过算法方式进行优化。
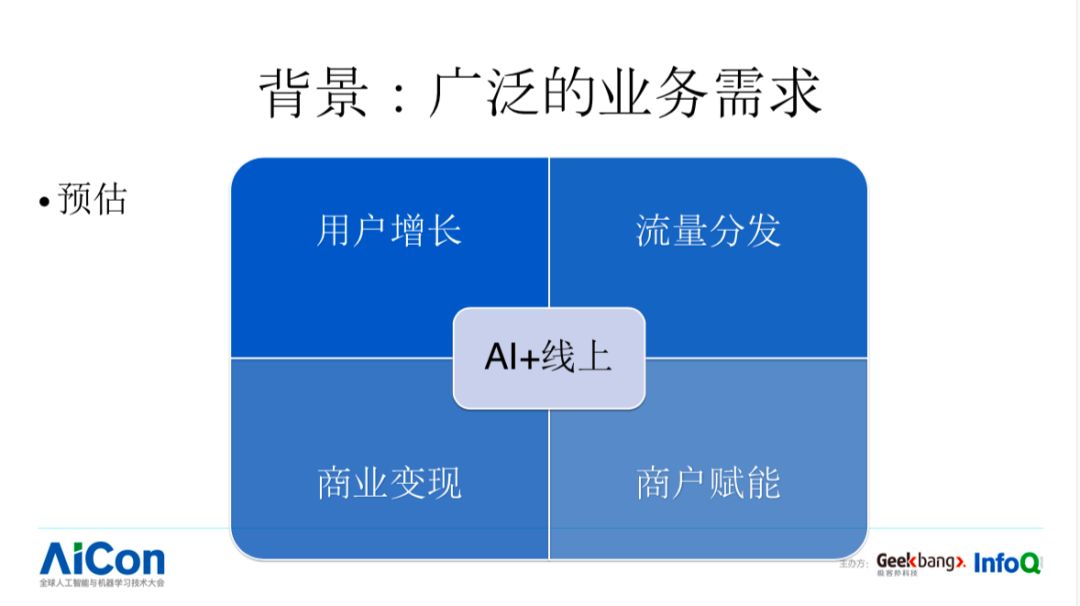
综合下来,在外卖业务,或者说大部分业务,都会遇到几大类问题,每一大类问题背后都有核心的算法在进行支撑,可能都会用到预估的技术。
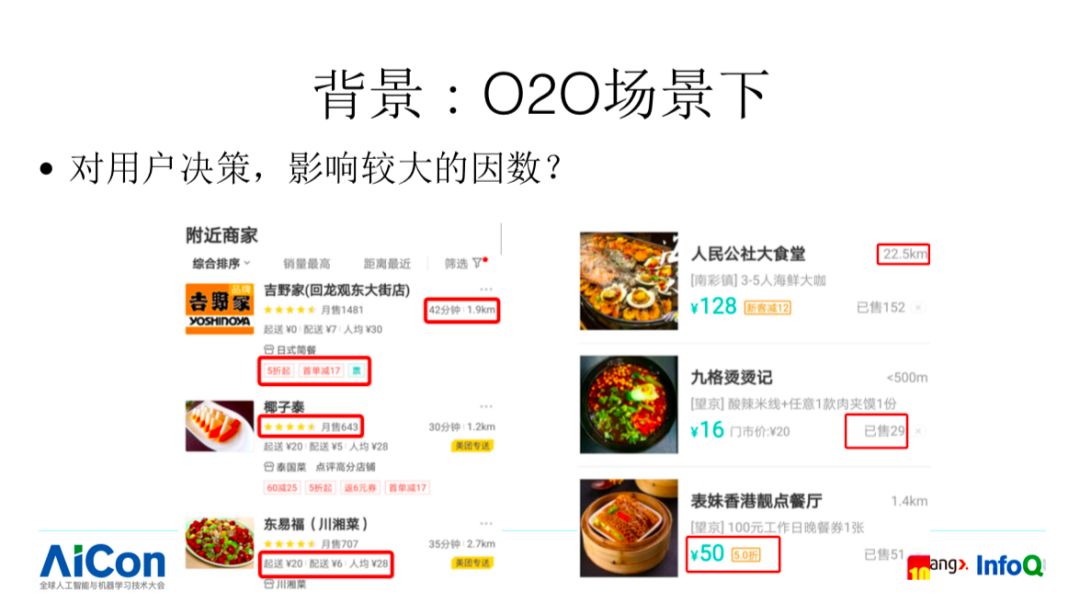
下面我们就直接进入今天的主题,从 XGB 到 LGB:美团外卖树模型的迭代之路。我们看下 O2O 场景下,对用户决策影响较大的因素,比如配送距离 (你不想等很久,你会关注配送距离),配送时间和商户的一些优惠情况,同时用户也会关注平均的销售情况,总共销售多少。这些都是连续类型特征,比较适合非线性模型。由于这样的业务特点,在美团点评的 O2O 场景下面,很多业务都在大规模使用树模型。
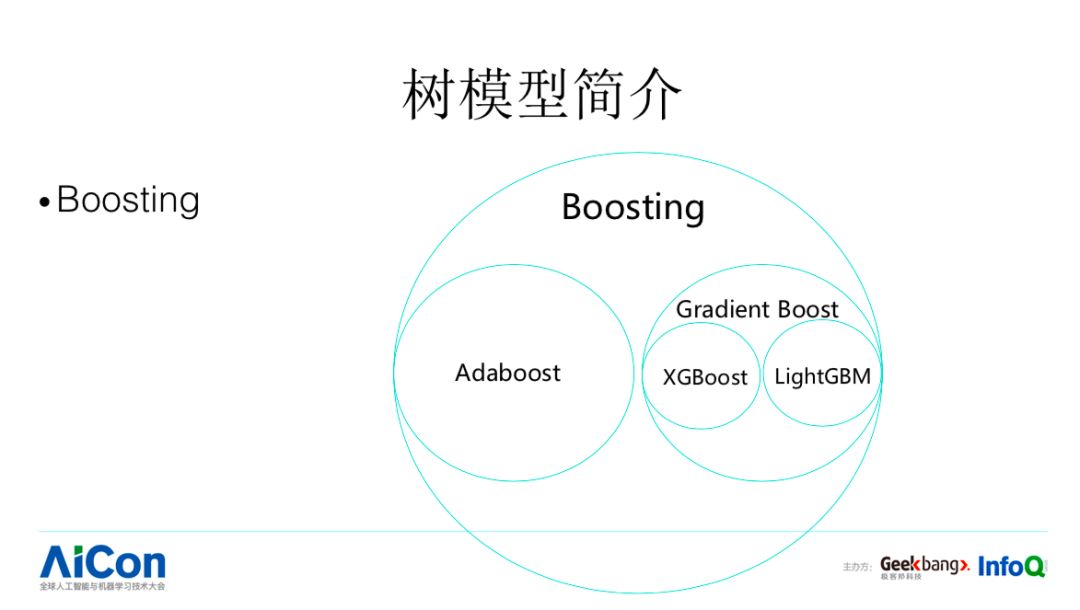
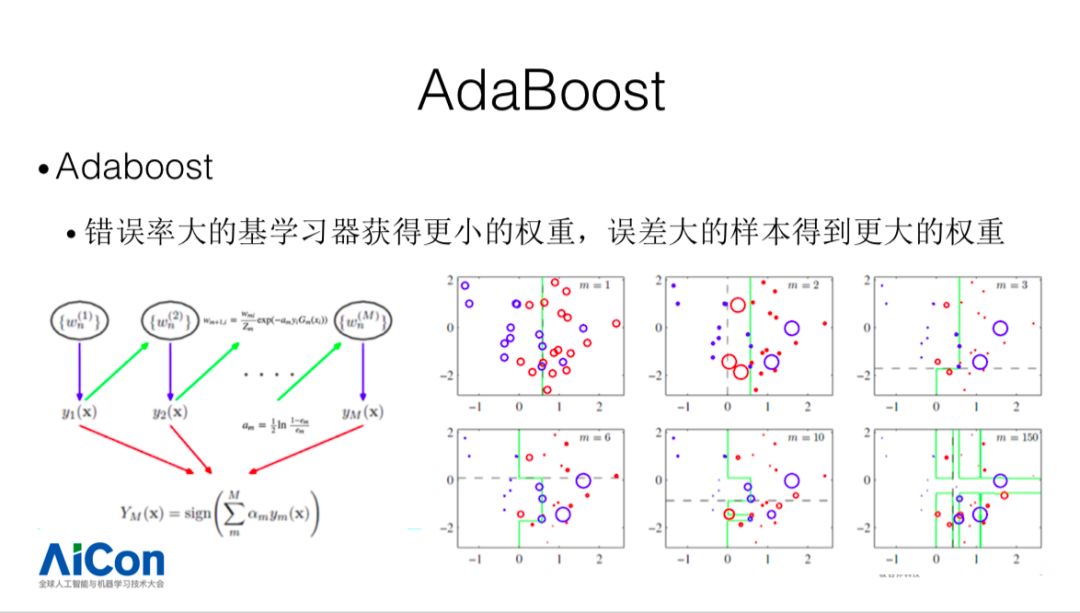
我们今天主要集中在树模型的迭代优化,我们看一下树模型以及 XGB 的简述。Boosting 目前有两种类型,Adaboost 和 Gradient Boost。Adaboost 中,错误率大的基学习器获得小的权重,误差大的样本得到更大的权重,这里可以使用错误率设置它们对应的权重,通过这种方法提升弱分类器在组合过程当中的效果,组合成更加强大的分类器。
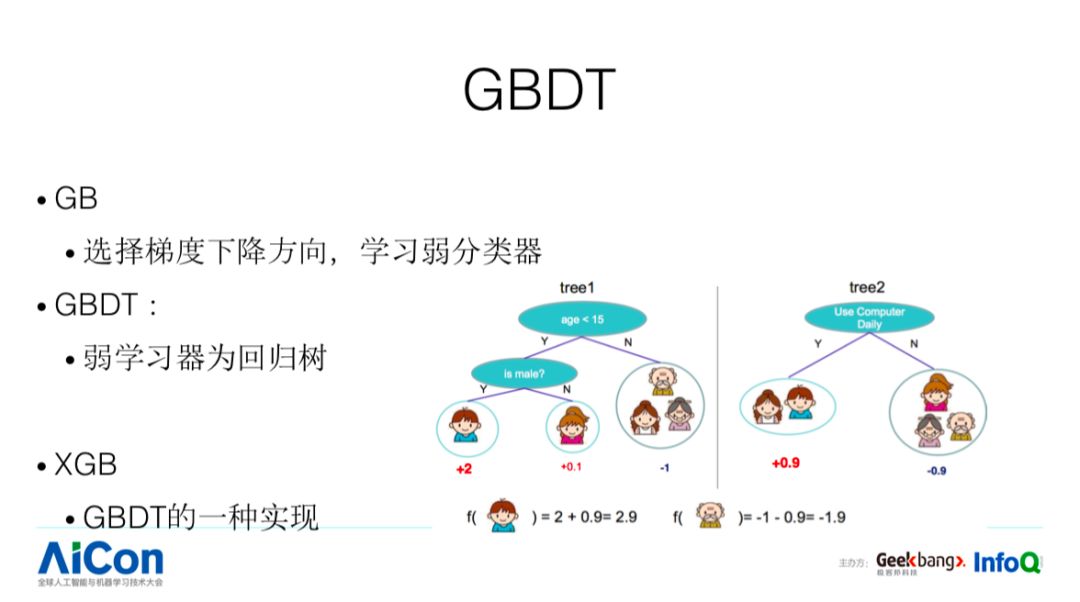
我们今天介绍的 XGB、LGB 都是 GBDT 的方法。GB,选择梯度下降方向,学习弱分类器。GBDT 的弱学习器为回归树,举一个例子。这个地方需要预测一个人对电脑、游戏感兴趣的程度,我们需要学习 N 棵树,每棵树学习过程当中都有分裂节点,这个时候我们需要选择 Splite Feature 和对应的 Split Value,比如这个人对应的年龄,以及你是大于 20 还是大于 30,根据这个进行往左走还是往右走,我们会把多棵树叶子节点上面的 Predict Score 进行组合,得到最终的 Predict Score,这是树模型简单的描述。XGB、LGB 只是树模型的不同实现方式,XGB 有什么优点呢?

一是针对 Loss 做了二阶泰勒展开,收敛速度更加快。
二是引入正侧项,进一步防止过拟合。
三是按叶子加和。
四是极小值解析解。
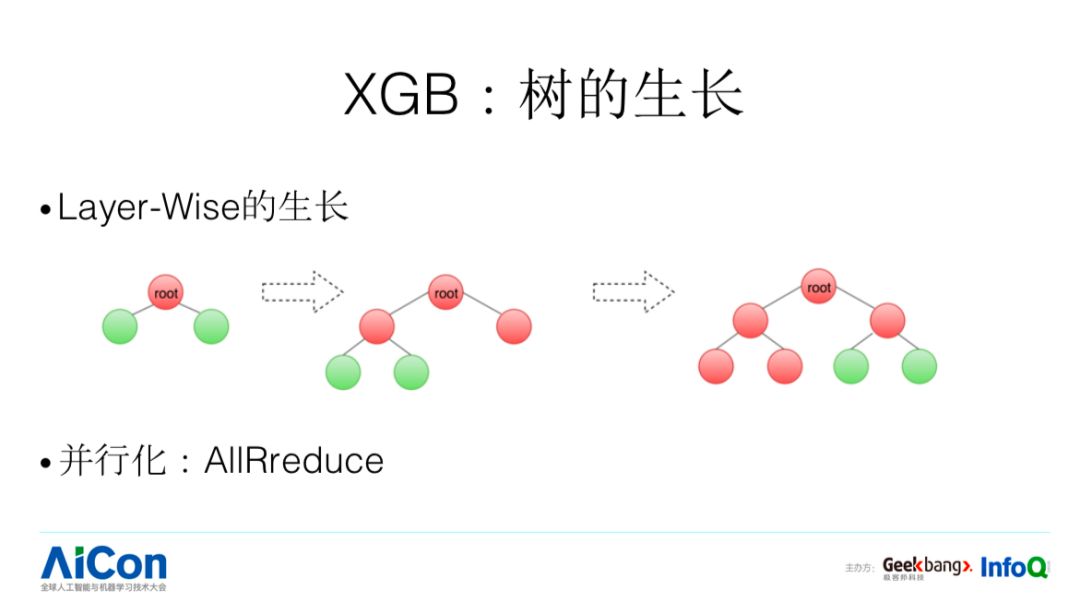
除此以外,这是其他一些特点,它跟传统的 GBDT 一样,采用 Layer-wise 的方式生长。接下来看一下落地过程中遇到的一些问题。
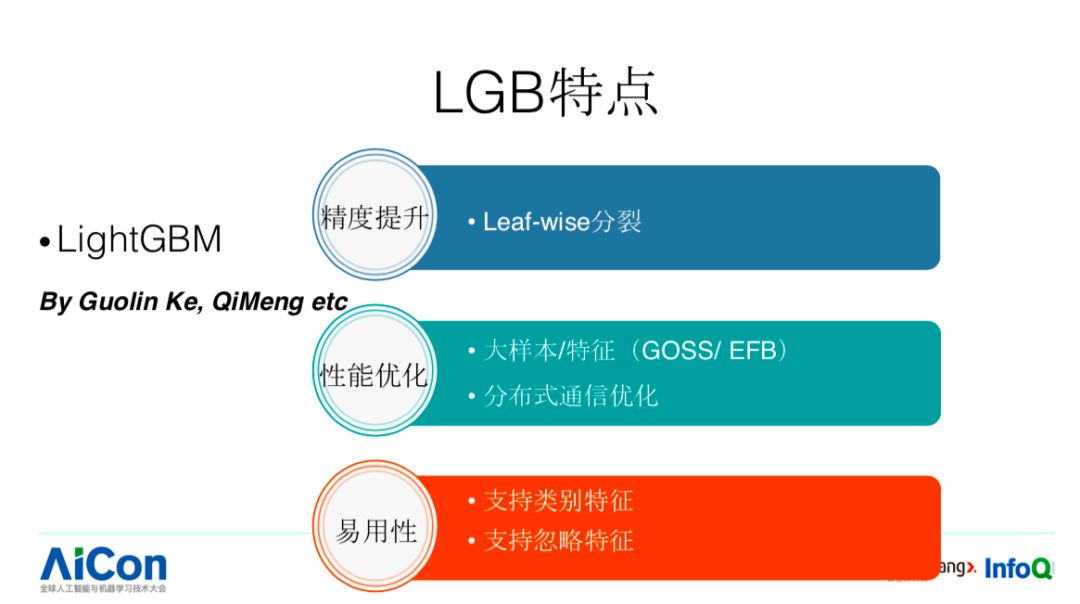
LGB 的微软研究院的同学们的工作,相对于 XGB 在几个方面会有所改进。
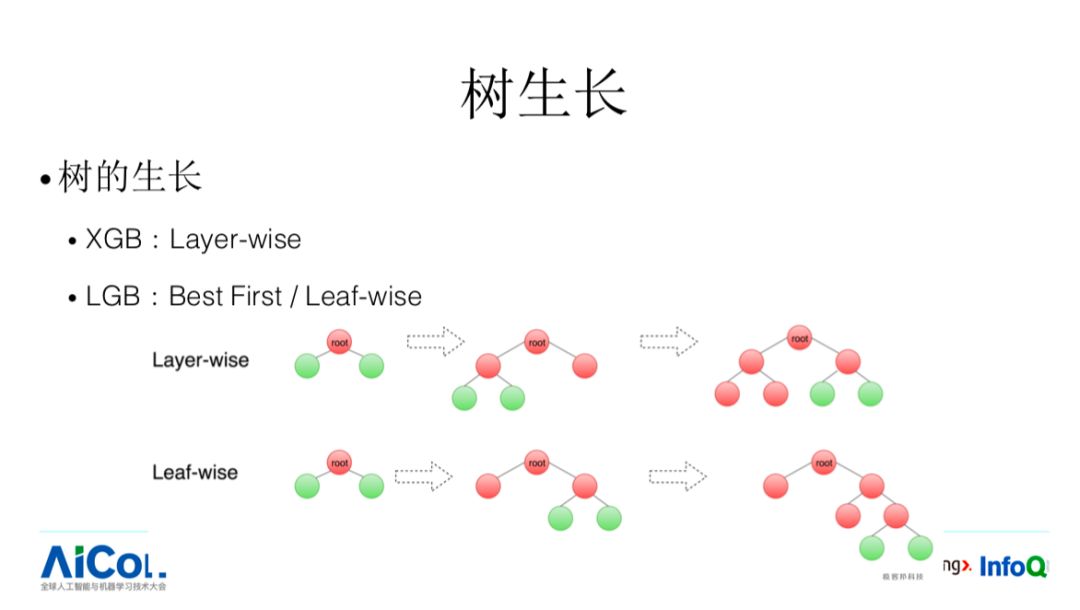
首先是精度方面,采用 leaf-wise 分裂。我们看整个树的生长方式,整个 XGB 是 layer-wise 生长方式,这是正常的生长方式。这里面会有什么小问题呢?它不能保证我当前最优的分裂是被优先进行选择的。比如说,A 节点它可以进行分裂,B 节点也可以进行分裂,B 节点的分裂收益更加大但高度更加深的话,有可能由于高度限制,按层进行生长方式下它可能不会被生长出来。针对这样的问题,LGB 就把这种生长方式改成 Leaf-wise,这样可以做到优先选择最优的分裂点,Best First。
第二个,核心点是计算加速,我们需要进行计算加速的时候要看性能受限在哪块,树模型在进行计算的时候,基本上受两方面因素影响。
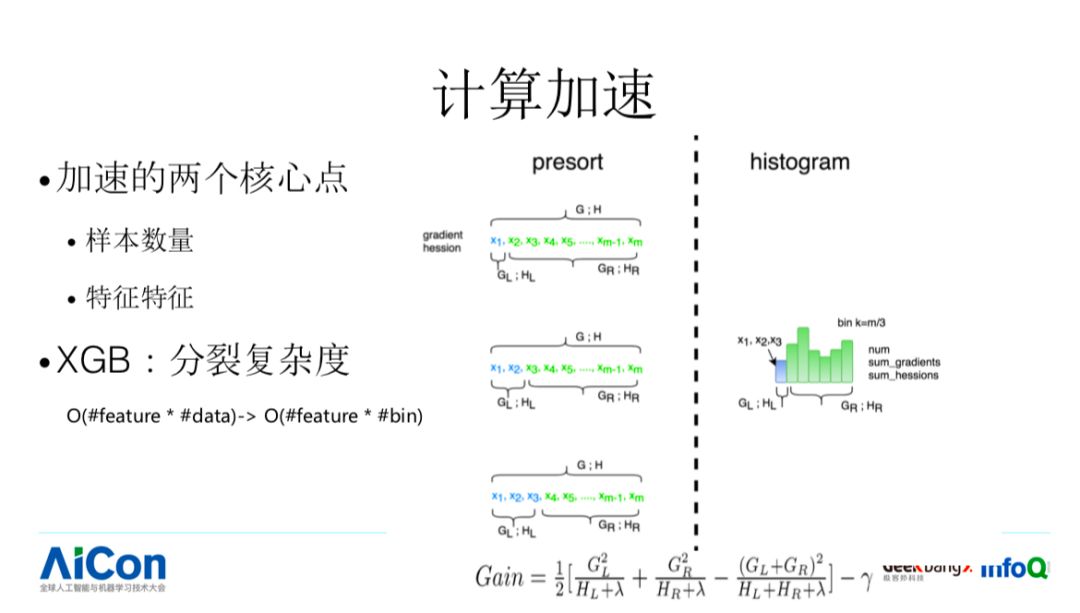
有 N 个 feature,我需要挑选出来一个,每个 feature 内部还有 M 个对应的 Split Value,我需要过一遍 data,这个工作量是非常大的,一个简单的优化方式是,我可以把我对应的 Split Value 进行分桶,在分裂的时候不需要过每个 date,我们提前做好预先计算就可以了。
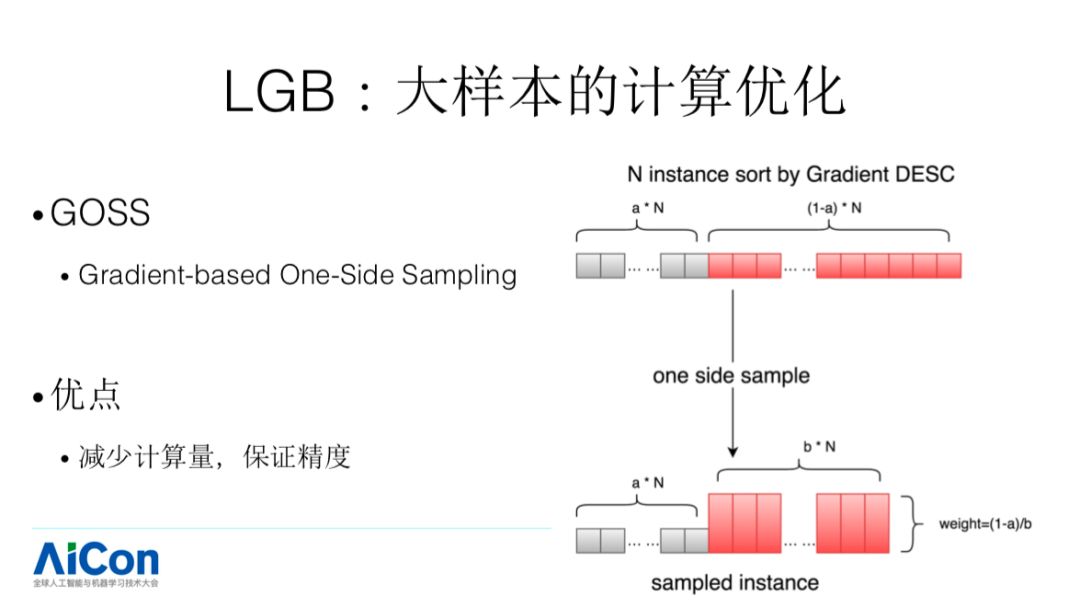
我们再来看一下,在样本量非常大的时候怎样进行优化的,这个方法叫 GOSS,假设我们有 N 个 sample,每个 sample 都有梯度值,对我们迭代影响比较大的都梯度值较大的 sample。所以它根据阈值,会分两部分,LGB 会对梯度值较小的部分进行采样,这个就是加速发生的地方。这样的一个优化,特别是针对于样本非常不均衡的场景下,可能带来的提升会比较大。例如,联盟情况下点击率在千分之几,这种情况带来的加速比较大。
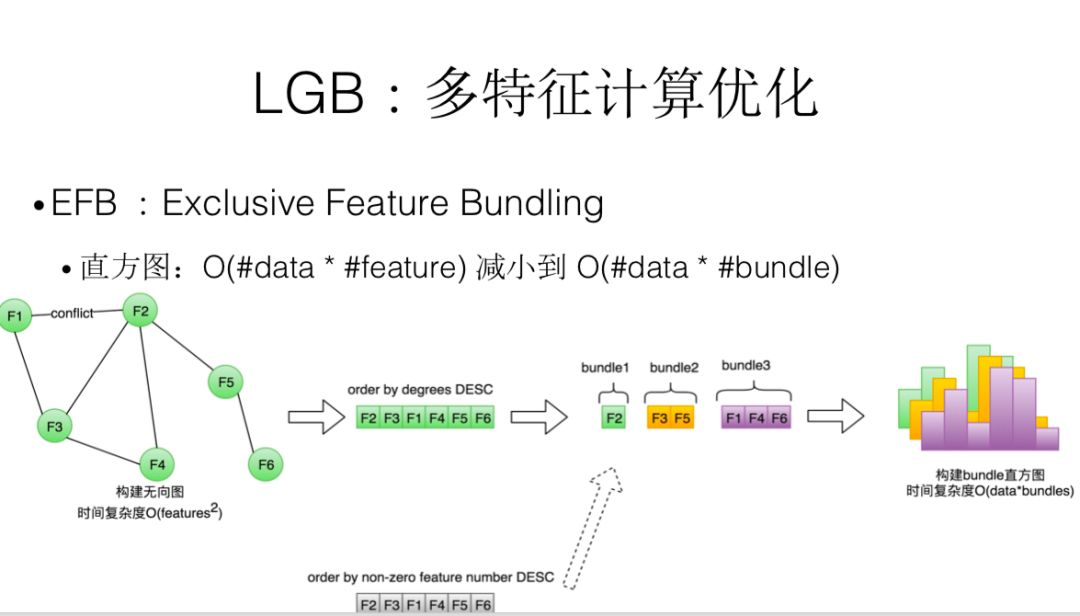
针对 feature 比较多的,它会把很多 feature 绑在一起,这个背后思考是什么?因为我们在进行分裂的时候,我会变 N 个 feature,如果有些 feature 它们共现程度不是很高,我就可以把这几个 feature 绑在一起。比如 A 和 B 两个共现程度不高,在分裂的时候可以把这两个 feature 绑定在一起考虑。整个算法分为四步,首先构建一个无向图,根据任意两个 feature 之间的冲突或贡献的次数,在这个无向图里我们会根据度进行降序排列。如果加入一个新 feature 的时候,它对应的冲突个数大于一个阈值,我们就新开一个 bundle。
接下来,看一下网络通信部分。
我们在 XGB 里面需要进行网络通信的有哪几块?第一个是直方图求和部分。第二个是每个 worker 找到了分裂点,我们怎么样寻找全局的最优的分裂点,这两部分都需要进行网络通信。XGB 对应的方法是有容错的 AllReduce。比如说,我们需要进行求和的时候,这是最经典的方案,假设我们有七个节点,每个节点会收集它的左孩子和右孩子传过来的结果,同时会跟自己的本身的结果进行求和,这样的话就得到整个左子树的和,他会把这样的结果再去往上发,最终到根节点,他就可以知道全局节点的和是多少,这是 bottom up 的过程。
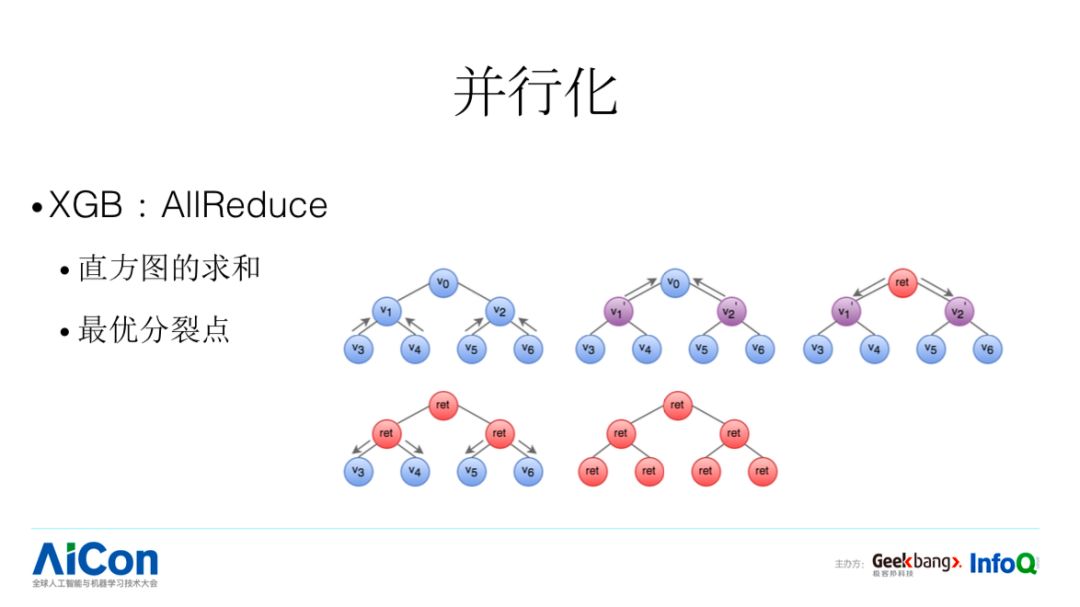
第二步,把这个结果告诉其他的 worker,这是一个 bottom down 的过程。每个节点接受父亲节点的结果,同时往下进行分发。AllReduce 的方式是大规模分布式的 Batch Learning 中最常用的通信方式。接下来我们看看 LGB 针对这块做了哪些优化。
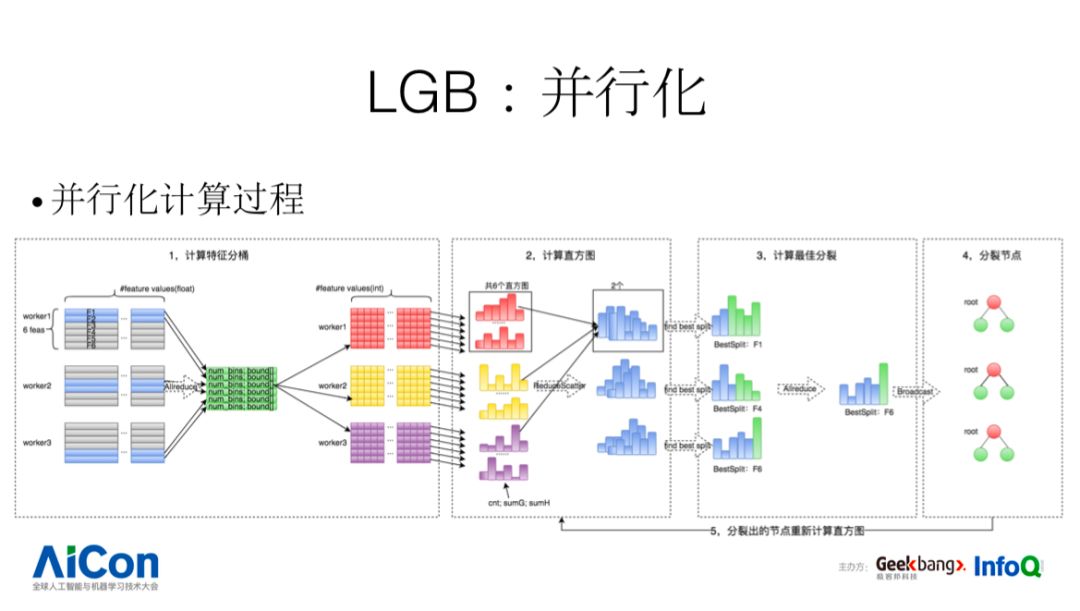
并行化,分为五步:
第一步,使用本地数据计算特征分桶,并将特征值压缩为 int 桶号;
第二步,本地计算所有特征的直方图,通过 reducescatter 得到每个 work 分配到的那两个特征的全局直方图;
第三步,每个 work 求出本地最优分裂(最优分裂节点,分裂的特征,以及特征的分裂阈值);通过全局归约得到全局最优分裂;
第四步,每个 work 根据全局最优分裂对本地模型进行分裂。计算叶子节点的权重;
第五步,重新计算分裂出的叶子节点的直方图,重复 2,3,4 步骤直到收敛;
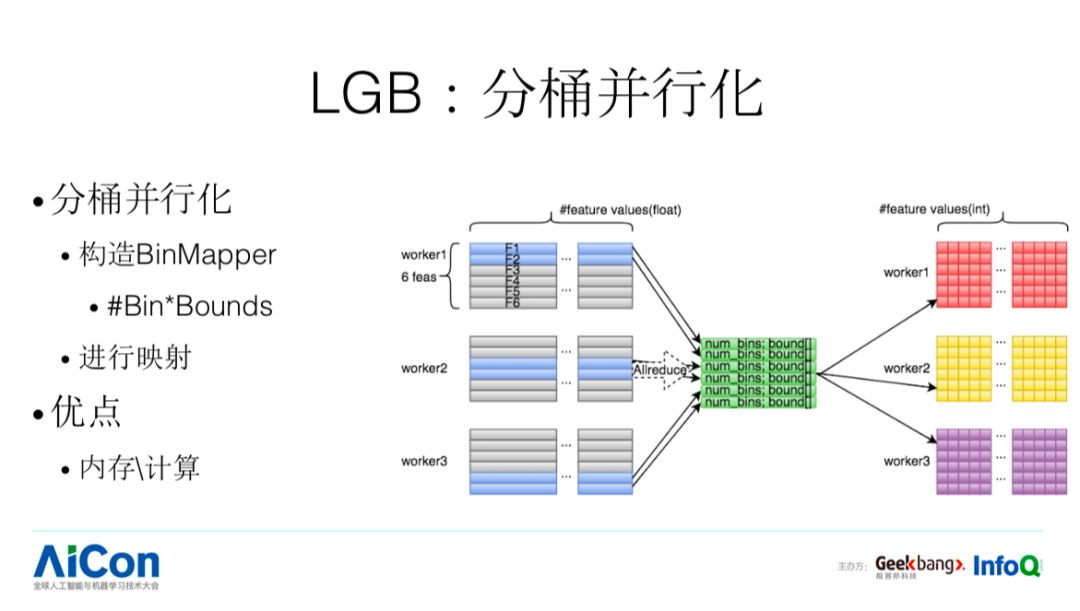
计算特征分桶是求直方图的先决条件,给定每个特征要分成的桶数,计算每桶的特征值上下界。在分布式计算中,每个 work 计算自己负责的特征的 bin_mapper,之后再通过 allreduce 得到所有特征的 bin_mapper。最后可以根据 bin_mapper,将 float 的特征值映射到 bin 中,就可以用 int 桶编号来表示。
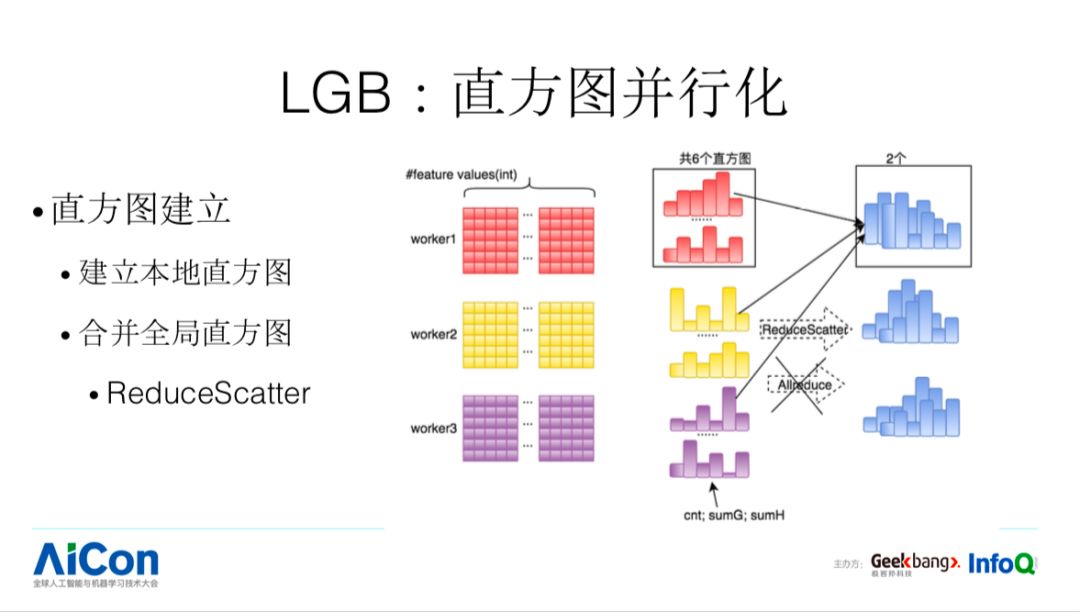
本地建立所有特征的直方图,每个特征直方图可以通过遍历已经编码为 bin_id 的数据快速实现,最终得到 6 个直方图,包含样本数,以及样本的一阶二阶导数之和。
合并全局直方图,传统的 xgboost 在这里使用一个 allreduce 操作使每个 work 都同步了 6 个全局直方图。但实际上每个 worker 其实只需要关心自己分得的特征的直方图,这里 lightGBM 对 AllReduce 操作进行优化,使用 ReduceScatter 算法,最终每个 worker 只得到自己分配到的特征的直方图,有效的降低了数据通信量,提高了训练效率。
举例:4 个 worker,R0-R3,总共 8 个特征,每个 work 已经计算完本地直方图,下面要进行合并直方图。
通过递归调用,一半一半的进行归约操作,优点是大大减少了通信量,不需要向 AllReduce 每次都需要传递所有的信息,这个通信量是巨大的,缺点是只能用于 2^k worker,后面我们会讲到针对这一问题的解决方案。

每个 worker 得到分配到的两个的特征的全局直方图之后,即开始在本地遍历叶子节点和特征,计算本地的最大分裂增益及分列方式。
之后 xgboost 通过 allreduce 方式计算全局最优分裂,而 lgb 采用 allgather+ 本地 reduce 操作得到全局最优分裂

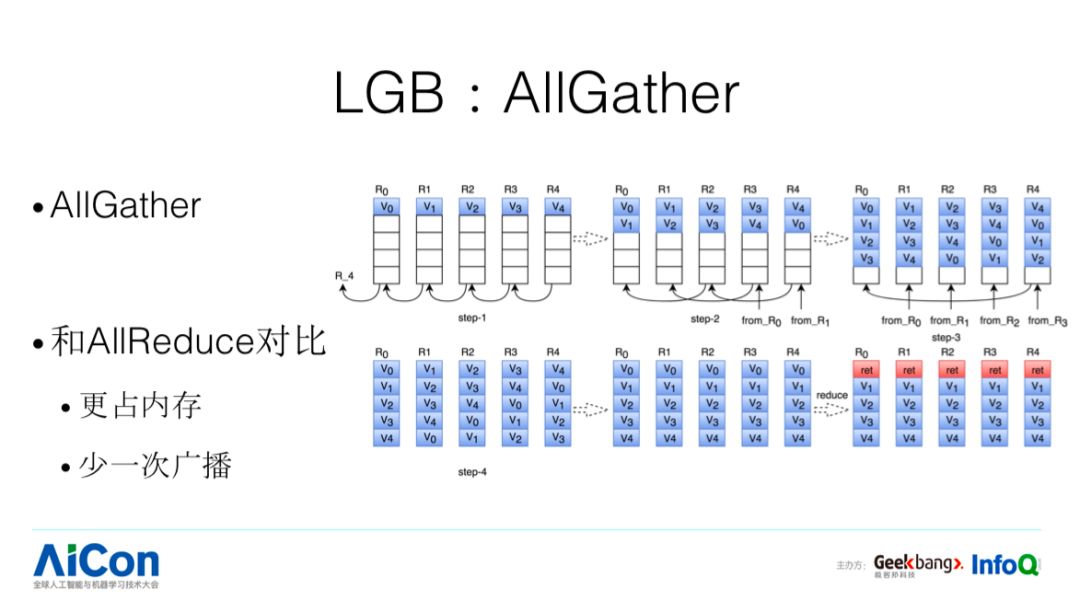
接下来我们看下 AllGather:
整个 AllReduce 有两个过程 bottom up 和 bottom down, 完成本地计算之后,我们需要把多个本地计算结果挑出全局最优特征,这个在 XGB 里面也是基于 all reduce 实现的。在 LGB 里面使用 all Gather。假设我们有四个节点,第一步 R1 给 R0,第二步 R2 同步给 R0,这个时候 R0 的 V0 是自己的,V2、V3 从 R2 拿的,五个节点的内容 R0 知道了四个。最终通过补全的方式,比如 R4 把剩下的几个结果一一补到对应的位置上去,通过这样的过程,每个节点都知道整个集群里面我对应的结果是怎么样。然后我在本地做一次 reduce 操作,这样每个节点都知道全局的结果。
在存储和计算上面,AllGather 和 AllReduce 相比有什么不一样呢:存储上,左节点接收一个,右节点接收一个,累计的结果往上传,看过 AllReduce 代码后我们会发现这个只需要一份内存 +Buff 的空间,比较节约空间,AllGather 呢?只要有几个节点,我就会存储几个结果;计算上,和 AllReduce 对比,少一次 BottomDown 广播;综上 AllGather 会更加吃内存、速度会更加快,而树模型本身占的空间并不大,这个也是 AllGather 在树模型上适用的原因。
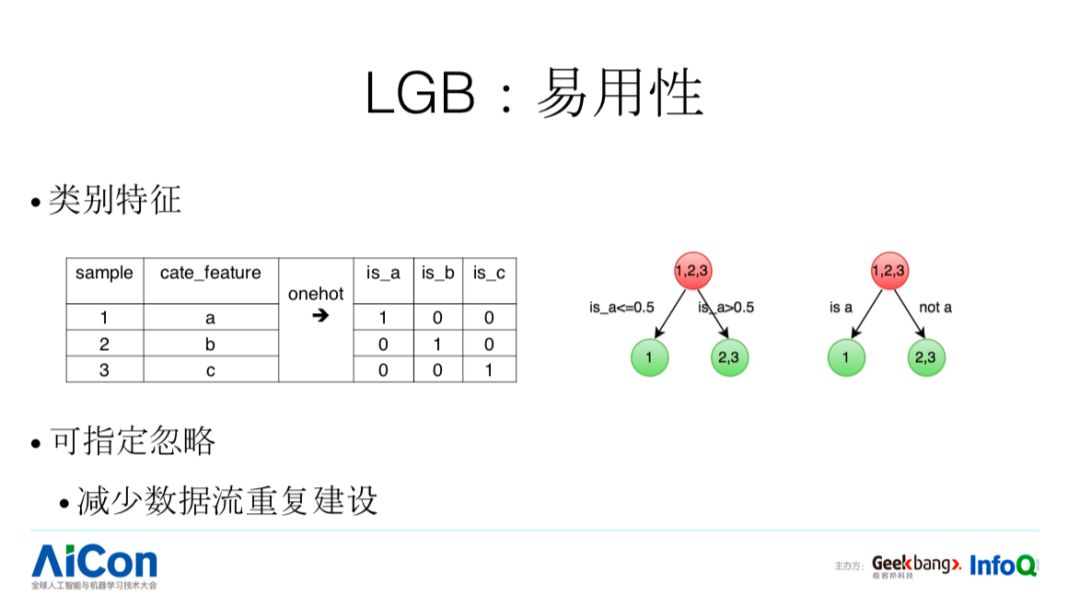
我们再看 LGB 易用性。传统的类别特征(见 PPT),可指定忽略。这样的特点在实际业务应用过程会带来什么样的好处呢?例如我们要调研多个特征的时候,我们就可以建一条数据流,通过制定忽略的方式,得到不同特征的调研结果,这样可以减少数据流建设的成本。
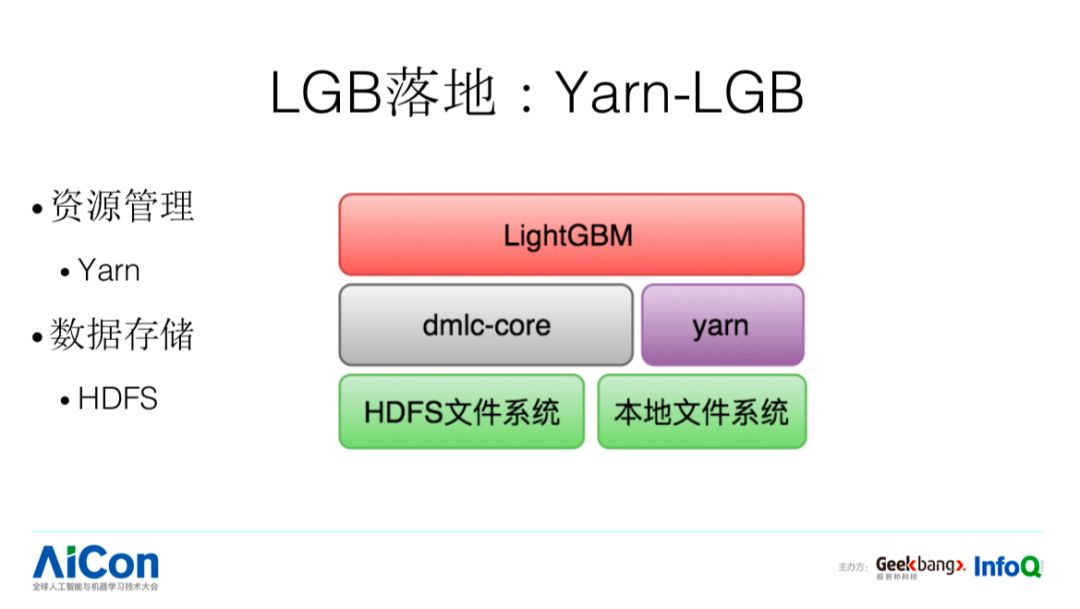
在工业界场景下,我们对数据存储和资源调度也做了一些定制,使用 HDFS 作为分布式存储,使用 Yarn 做资源的调度;
此外,我们还做了一些其他优化。ReduceScatter 比较强的依赖于我的节点必须是 2 的 N 次方,很多情况下不一定是 2 的 N 次方,针对这种情况我们可以看下速度变化情况,64 个节点情况下直方图求和的时间,XGB 是 13 毫秒,LGB 是 2 毫秒,如果变成 65,LGB 从 2 毫秒变成 28 毫秒,针对这个可以做一些优化,使用 VirtualRank+ReduceScatter 的方法,使得时间从 28 毫秒降到 3 毫秒。

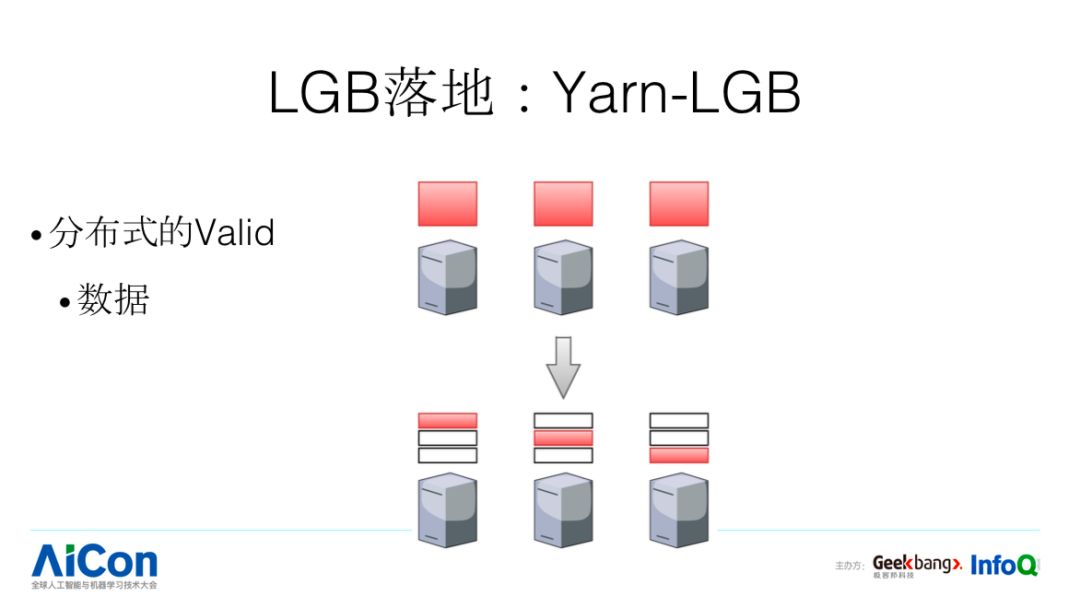
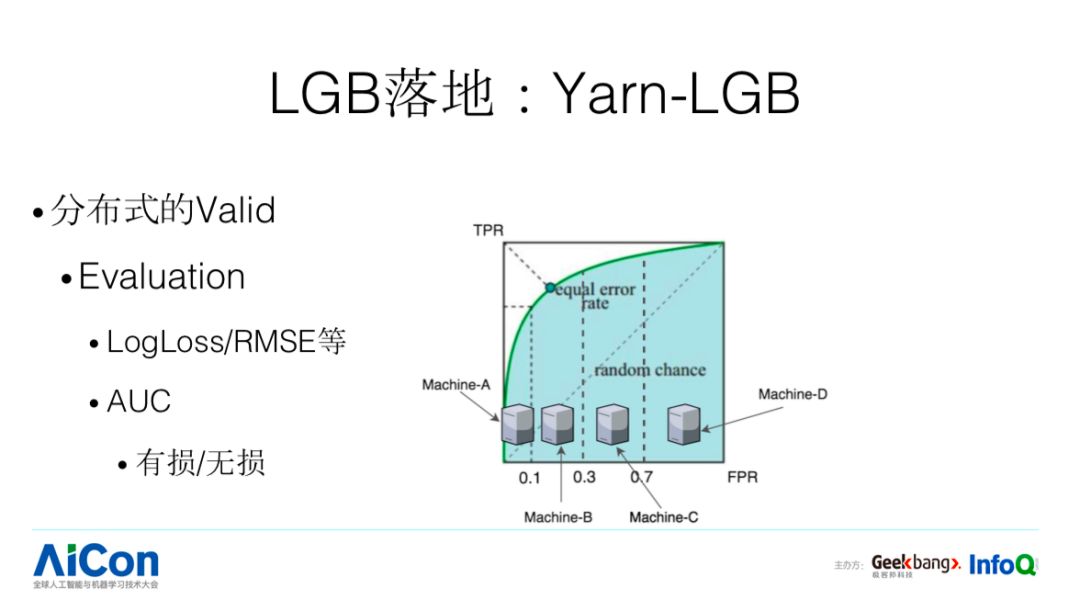
LGB 在分布式的 valid 是每台机器加载一份,当数据规模比较大的时候会出现什么问题?会 OOM,所以一个简单的方法是我们把对应的 data 进行分布式拆分。我们再看分布式 Evaluation 怎么做,指标分两种类型:第一种是 LogLoss/RMSE 等,计算完了,求个平均或者累加就可以了;第二种是 AUC,可以简单求平均,但不够准确,针对这样的指标,我们会做特殊的优化,使得分布式评估会更加准。
最后我们看一些其他的优化点。
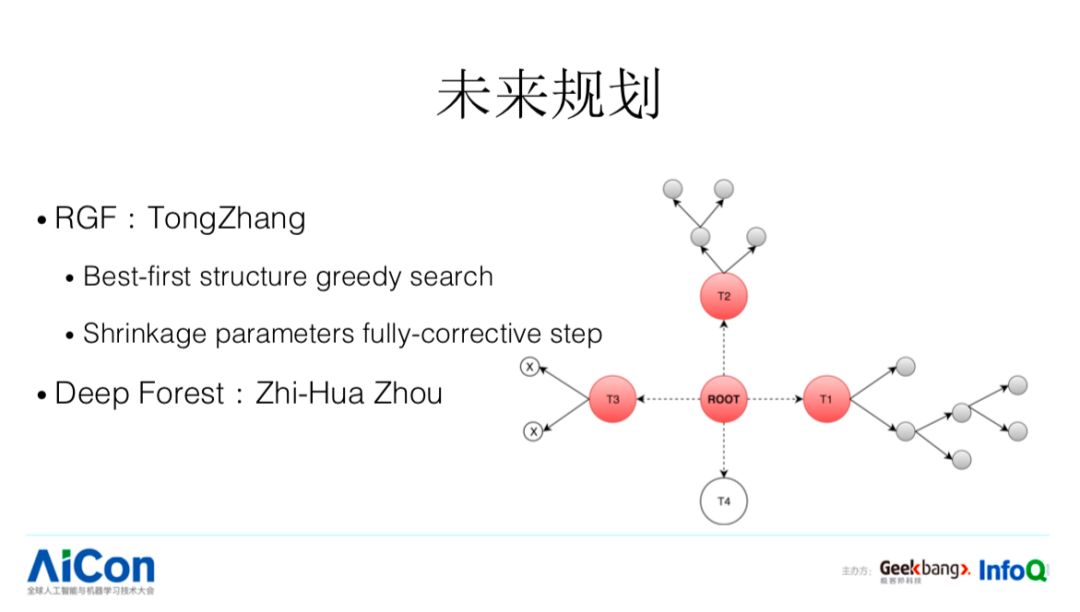
第一个,这里有两个工作。RGF,是张潼老师的工作,针对于刚才 best first 树的生长方式它又走了一步,我们刚才说的树的生长方式只是限制在一棵树内部,他把这个思路放得更加开阔,比如有已经成型的树,去进行筛选的时候,不单单考虑我这棵树自己本身,可以新开一棵树,这样可能带来更好的精度提升。
第二个,每次学一颗树,学完后,Boosting 的过程中参数是确定的,这个可能不是一个最优的选择,针对这个问题可以做一个优化,当每次学到一棵树的时候,把当前的参数以及对应历史上到现在为止的参数全部再优化一遍,这是里面两个重要的点。但这会带来一个问题,model 会更加容易 overfit,所以要做结构化,这两个之间怎么平衡。第二个工作,南大周志华老师提出了 deep forest,其实也是一种网络结构的优化。
以上就是王老师关于《从 XGB 到 LGB:美团外卖树模型的迭代之路》的全部内容,相信大家看完以后也是学有所获。AICon2018 全球人工智能与机器学习技术大会将于 12 月 20 日在北京国际会议中心召开,届时王老师将会作为这届大会“机器学习应用和实践”专场的出品人参会,想要与王老师面对面交流的同学,赶快来关注 AICon 吧!
更多大会议题和精彩内容欢迎扫描下方二维码了解详情,目前大会最低价 6 折售票火热进行中,讲师招募亦火热进行中,更多详情可点击“阅读原文”了解!购票咨询:18514549229(同微信)


如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!





