HBase框架基础(一)

HBase的基础框架,将分成几个章节对HBase进行描述,不当之处还望大家批评指正。下面是了解HBase基础架构的第一部分。
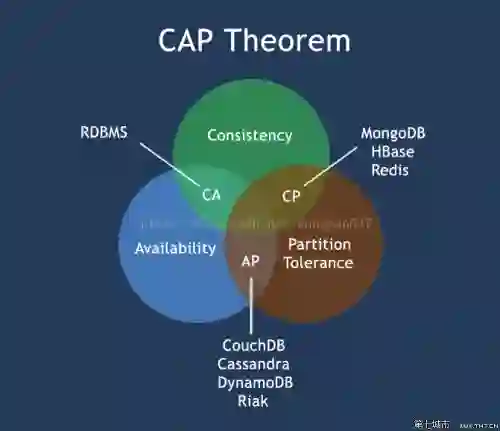
什么是HBase
要解释HBase,我们就先说一说经常接触到的RDBMS,即关系型数据库:
** mysql:
1、有开源社区版本的,有企业收费版本的
2、遵循主从架构
3、 端口号:3306
** sqlserver:
1、微软公司开发的产品,主要用于windows平台下的项目
2、端口号:1433
** oracle:
1、超强的集群性能
2、端口号:1521
再来说一说HBase这个非关系型数据库:
** HBase:
1、灵感来自于Google的BigTable论文
2、一般于Hadoop结合使用,是Hadoop项目的子项目
3、基于key-value的形式存储数据
4、高性能,高可靠,面向列,可伸缩的分布式存储系统
5、没有sql语句,一般用API操作
6、适用于单表数据量超大,且不能分表
7、分布式架构,支持服务器在线添加和移除
接着说一说HBase和Hive的关系和区别:
** Hive:
1、是数据仓库,不是数据库
2、一般用于分析,并不会直接接入到在线业务
3、实际上是将hql语句转化为mapreduce任务运行在yarn平台上
** HBase:
1、面向列的非关系型数据库,分布式架构
2、用于存储数据和检索数据,一般会直接接入在线业务
3、不依赖于yarn和mapreduce
最后说一说RDBMS和HBase的区别:
1、RDBMS使用sql语句,HBase使用API
2、RDBMS基于行存储,HBase基于列存储且支持更好的压缩
3、RDBMS适用于存储结构化数据,HBase适用于存储结构化和非结构化数据
4、RDBMS支持事务处理,HBase不支持事务处理
5、RDBMS支持多表Join,HBase不支持多表Join
6、RDMBS更新表数据会自动更新索引文件,HBase需要手动建立索引,手动更新
7、RDMBS适用于业务逻辑复杂的存储环境,HBase不适合。
8、RDMBS不适合存储超大数据量的单表,HBase适合。

HBase基本进程
HMaster
HMaster节点有如下功能:
1、为HRegionServer分配HRegion
2、负责HRegionServer的负载均衡
3、发现失效的HRegionServer并重新分配其上的HRegion
4、HDFS上的垃圾文件回收
5、处理Schema更新请求
HRegionServer
1、维护HMaster分配给他的HRegion,处理HRegion的IO请求
2、负责切分正在运行过程中变的过大的HRegion

HBase基本原理
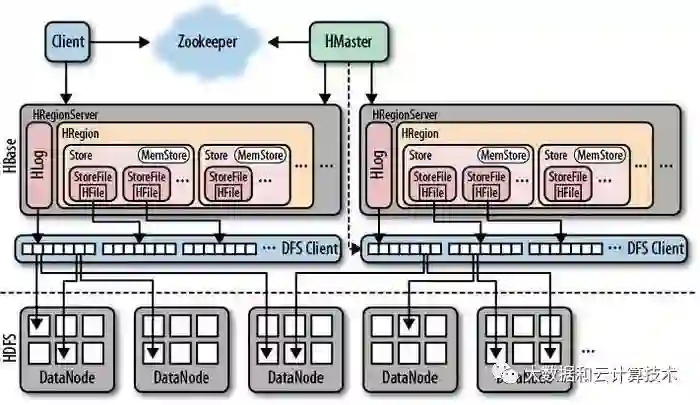
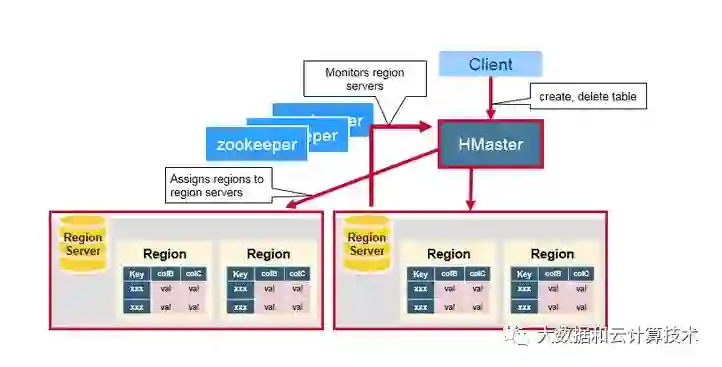
注:一般而言,Master和NameNode在一台服务器上,RegionServer与DataNode在同一个服务器上。
Client:
包含访问HBase的接口,并维护cache来加快对HBase的访问。说白了,就是用来访问HBase的客户端。
HMaster:
这个东西是HBase的主节点,用来协调Client端应用程序和HRegionServer的关系,管理分配HRegion给HRegionserver服务器。
HRegionServer:
Hbase的从节点,管理当前自己这台服务器上面的HRegion,HRegion是Hbase表的基础单元组建,存储了分布式的表。HRegionserver负责切分在运行过程中变得过大的HRegion。
HRegion:
一个Table可以有多个HRegion,HBase使用rowKey将表水平切割成多个HRegion,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的
StartKey为空,最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。
HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。
每个HRegionServer可以同时管理1000个左右的HRegion,出处请参看论文:BigTable(5 Implementation节):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))。
MemStore:
它是一个写缓存,数据先WAL[write ahead log](也就是HLog它是一个二进制文件,所有写操作都会先保证将数据写入这个Log文件后,才会真正更新MemStore,最后写入HFile中),在写入MemStore后,由MemStore根据一定的算法将数据Flush到底层HDFS文件中(HFile),一般而言,对于每个HRegion中的每个Column Family来说,有一个自己的MemStore。
StoreFile:
1个HStore,由一个MemStore和0~N个StoreFile组成。
HFile:
用于存储HBase的数据(Cell/KeyValue),在HFile中的数据是按RowKey、Column Family、Column排序,对于相同的数据单元,排序则按照时间戳(Timestamp)倒叙排列。
Zookeeper:
HBase内置有zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。
并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase 管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。如图:
猜你喜欢
大数据和云计算技术周报(第56期)
加入技术讨论群
《大数据和云计算技术》社区群人数已经3000+,欢迎大家加下面助手微信,拉大家进群,自由交流。

喜欢QQ群的,可以扫描下面二维码:
欢迎大家通过二维码打赏支持技术社区(英雄请留名,社区感谢您,打赏次数超过108+):