西蒙·卢卡斯:基于统计前向规划算法的视频游戏通用人工智能

导读
2019年第二期“怀德海讲座”于6月28日在北京市朝阳区中航资本大厦举办。本期讲座邀请到Queen Mary University of London的教授Simon Lucas以“Game AI with Statistical Forward Planning and Learned Forward Models” 为题进行深度研讨和演讲报告。

统计前向规划(Statistical forward planning, SFP)算法使用一种仿真模型(也称为前向模型)自适应地搜索有效的动作序列。它们提供了一种简单通用的方法,为各种游戏提供快速自适应的AI控制器。示例算法包括蒙特卡罗树搜索(Monte Carlo Tree Search)和滚动层进化(Rolling Horizon Evolution)。SFP要求游戏状态能够被快速复制和推进,这在很多情况下都能满足。这次讲座简要介绍了一个强大的SFP算法——滚动层进化(Rolling Horizon Evolution)。该算法不需要任何事先训练就可以在各种视频游戏中出色地运行。为了将这种类型的AI应用到更广泛的问题,我们需要学习前向模型。这次讲座还报告了一些近期关于前向模型的学习方法及实验结果。
嘉宾简介
西蒙·卢卡斯(Simon Lucas)是伦敦玛丽女王大学(Queen Mary University of London)人工智能教授,也是该校电子工程与计算机科学学院(School of Electronic Engineering and Computer Science)院长和游戏AI研究小组的负责人。他在南安普敦大学取得了电子与计算机科学博士学位。他也是IEEE Transactions on Games的创始主编和IEEE Conference on Games的联合创始人。他的研究领域包括开发和应用计算智能技术来构建更好的游戏AI,使用AI设计更好的游戏,对于智能的本质深刻的见解,并致力于通用人工智能。他是艾伦·图灵研究所(Alan Turing Institute)的会士。
讲座内容
谢谢大家,很高兴可以来到这里讨论我最喜欢的话题。
来到中国我非常高兴,我很喜爱北京,喜欢这里美妙的食物。很有意思的是,我问我北京的同事,他们喜欢北京的什么,他们回答是北京的食物。我问我在一个北京的联合项目的校友说他喜欢伦敦的什么,他也说是食物。

今天的这个讲座是关于 Game AI 以及 Forward Planning 还有 Learned Forward Model。

我将快速讲解一些幻灯片,介绍大体的思想,欢迎大家随时提问。
首先,什么是Game AI ?
关于游戏,最迷人的一点在于,游戏总能给我们提供一些有趣的挑战。在一个复杂的场景中,决策下一步采取的行动,这就是游戏的本质。
Game AI被更多地用来进行现实世界的决策,这个世界上大量的决策与最优决策存在很大的差距。我强烈地相信,利用Game AI的方法,我们可以做出更好的现实世界的决策。目前现实世界中的很多决策非常愚蠢,缺乏实用性,我相信,人们在面对一些消极的结果或者方向时,如果使用Game AI,尤其是Forward Statistical Planning的相关算法,会获得更好的解决思路。

接下来,我将介绍 Artificial General Intelligence. 我认为主要有三个要点:
(1)Deep Reinforcement Learning,通过经验进行学习,用深度神经网络捕捉知识。
(2)Statistical Forward Planning,这是一种涡轮增压加速的想象,你要做的是,用很快的速度运行世界的模型,然后用它去优化规划以及动作序列,总是选出能够引向最好结果的动作,实现的两个方法包括蒙特卡洛树搜索,以及滚动层进化(Rolling Horizon Evolution)。
(3)Evolution的方法非常灵活,可以在很多方面得到应用。使用演化计算,你可以优化一些复杂的架构设计,并尝试去提升它,将其简化。
总的来说,对于Artificial General Intelligence,我们可以使用物种层次的Evolution方法,可以使用深度学习结构,也可以使用Statistical Forward Planning去得到更优的规划,在不同尺度下应用或将三者混合使用,都是非常有效的。

我们大家都玩过很长时间游戏,包括电子游戏,虽然我们也许并没有很认真的对待它,但人们对于游戏所赋予的挑战都非常入迷。游戏为不同的理论和系统提供了平台,游戏的跨度很大,从简单的石头剪刀布、囚徒困境,到复杂的星际争霸,这对于人们来讲非常有趣,而且我们可以很容易采用平行架构进行快速的仿真。
关于Game AI,我们不仅可以实现智能决策,还可以利用AI去设计更好的游戏。因此这是一个极具创造性的过程,我们可以采用Evolution的方法进行设计。

关于Game AI的挑战都非常有趣。例如,我们如何实现快速学习?我们知道Deep Mind能够完成很了不起的任务,但是人们估计,如果想要复现他们的结果,就要付出很大的时间代价,假设你要为这些时间花钱的话,这将花掉你一百万美元去复现整个学习过程。但是如果采用SFP方法,这个过程的适应会快速很多。
这些挑战还包括游戏中的大量任务,开放的决策空间以及局部的可见性,例如战争迷雾,这些挑战会影响我们对于游戏世界中状态的观察,也会对其他个体的置信度和目标产生不确定性,我们无法知道其他的个体会如何行动。这些挑战非常有趣同时也非常复杂。

这里我想问一个问题:SFP会不会成为下一个深度学习?我们知道,深度学习改变了人工智能的世界,十年前,深度学习还处于萌芽期时,很多人工智能方面的问题是难以解决的,但是深度学习改变了这个情况,包括计算机视觉、人脸识别、语音识别等等领域。我们对于SFP的期待是,它在这些领域也能够做出自己的贡献,但是比深度学习更具有可解释性。当我们利用这个方法进行仿真的时候,我们可以更清楚地了解到为什么算法能够做出这样的决策。

SFP是一种具有强泛化性且快速适应性的AI方法,它的特点是什么呢?
大家可以看这张PPT上的展示,这是两个非常经典的游戏,在上世纪九十年代的游戏厅可以经常见到,这是两个非常常见的实时策略游戏,但是真正的策略制定是相对复杂的,有很大的难度。
关于SFP算法,非常令人惊讶的是,我们可以使用同一个算法以及同样的参数,去玩这两种不同的游戏,效果看起来好到让人难以置信。要做到这一点,我们需要很快地去复制系统状态,然后快速地向前发展。对于每一个决策,我们都要经过1000次以上的仿真。

首先,SFP包括模型,就是我们进行任务规划所用到的模型。SFP使用前向模型,也被叫做世界模型,辨识这个模型是最重要的一个问题。对于游戏,这种模型是永远存在的,但不是总能获取到的,比如有可能是一段你无法访问的计算机代码。对于真实世界的问题,这种模型可能是手动编程的,或者学习到的。值得注意的是,不一定完美的模型才有用,有些实验中我们甚至会故意破坏模型,以此测试不完美模型条件下的结果。

我们接下来介绍SFP的概念,也是它如何工作的基础。
为了能够做出决策,我们复制目前世界的状态,然后对一系列动作进行优化,最后选择一个最有可能带来好的结果的动作。很多游戏是非常复杂的,我们可能不知道什么是真正的最优,对于这种复杂的情况,得到一个确切的最优是不可能的,所以我们只要找到一个可能带来好的结果的动作。
当然,很多问题都会有一些不确定性,也会存在信息的缺失问题,这造成了很大的困难。另外,我们还会面对存在竞争或合作关系的未知个体。所以,我们最后的结果并不是求最优化,我们的目的是在某些方面比其他的方法要好。

那么这个SFP方法是不是可解释的?我们可以通过看仿真的结果,来了解为什么这个方法可解释。
对于一个AI方法,一个非常好的特征就是可调节性。比如我们打游戏的时候,我们希望有很多不同能力的人物个体,SFP可以通过调节序列的长度来调节个体对未来情况的影响范围,可以通过调节评估次数的数量来选择决策的精细度,可以通过调节移位缓冲获得不同决策间的连续性,这是算法很关键的一个部分。

利用前向模型,结合SFP算法,我们可以得到一个强大的AI方法。这依赖于快速的前向模型,这样我们可以实时地进行1000次以上的仿真,虽然实际上100次就足够,这个模型的公式如幻灯片所示,F代表模型,s代表当前状态,a代表动作,通过这个模型,我们可以得到执行这个动作之后的下一个状态。
在多个玩家的游戏中,我们不但需要决策自己的动作,还需要猜测别人的动作,这种和合作者以及敌对者之间的交互会让游戏变得更加有趣。

需要澄清的一点是,SFP并不是一个新的算法,这个可以追溯到1998年利用蒙特卡洛搜索解决拼字游戏,拼字游戏是一个很复杂的游戏,里面有很多的不确定因素,你不知道你将会得到哪一张卡片,因此需要很多的随机仿真来解决,效果不是非常的好。2006年,蒙特卡洛树搜索被利用在围棋游戏中,这改变了之前人工制定策略的方法,相比之前有了很大的提升。然后我们的研究组将这种算法应用在了电脑游戏上,在算法性能上,同样带来了显著的提升。

我们简单看一下蒙特卡洛树搜索的算法,这种算法基于随机仿真,然后我们通过传播随机仿真的结果建立这棵树,利用PPT中的这个公式对建立的树进行导向。我不仔细介绍细节了,大家可以看到,最终这个树向右进行延伸,以一种不对称的方式进行生长。
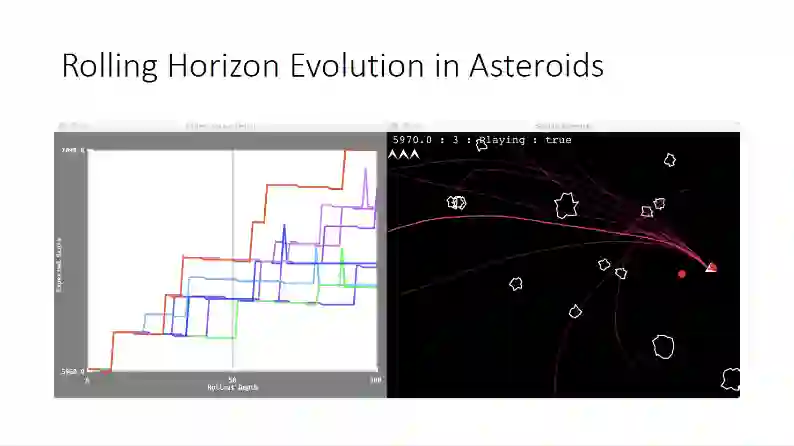
这张幻灯片中的例子是将Rolling Horizon Evolution方法应用在Asteroid小游戏上的结果。图中白色的是石块,红色的是宇宙飞船,我们要通过控制飞船完成射击所有石块的目标,同时避免它们撞上石块。左图是实验的结果评估,纵轴是算法评分,横轴是Rolling的步数,可以看到随着步数提升,评分逐步上升。
接下来,我们来看一个示例程序。大家可以看到,如果序列长度比较小,那么这个飞船只能看到较近的未来,而我们把序列长度适当设置大一些,可以看到飞船变得更有远见,评分有很大提升,同时避免了与石头的碰撞。
SFP相比深度强化学习的一个很大的优势在于,对于新的任务,我们不需要重新对算法进行训练,比如如果我改变了石头的数量,或者给一些特殊的减分石块,SFP方法可以很简单地适应这个情况。
我们也可以使用更复杂的程序来测试算法,比如图中这个更加复杂的实时策略游戏。

或者我们可以在星际争霸上使用这个算法,我们不去讲具体的细节了,这里面需要进行的反应、要处理的问题,要比之前的游戏多很多。
那么,现在有了SFP方法,我们可以与之前手动编程的专家系统个体进行竞赛,性能有很大提升。相比深度强化学习,SFP不需要训练,我们可以直接把它放入到这个游戏当中,就会取得很好的效果。

下面给大家举个例子,这里有个200乘200像素的二值图片,每个像素要么是白的要么是黑的,我问问大家,一共有多少种可能的图片呢?
听众:2的40,000次方。
没错,这就是正确答案,这是一个看起来很大的搜索空间,但是我们不必太担心,因为算法的复杂度取决于空间的性质,以及我们想要得到多大程度的最优。

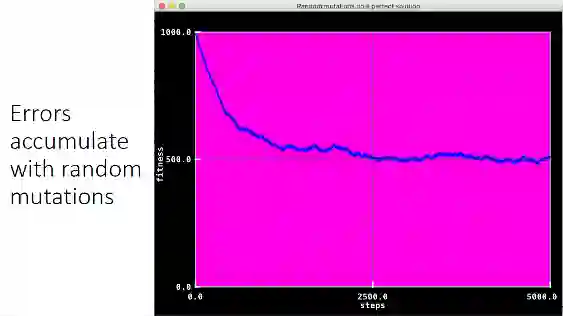
举例来说,当我们在PPT中的这一图像中加入噪声,这个图像一开始还是可以认出的,一会就变成了随机的噪声,如果我们把图像退化的情况画在折线图上,这是原来图像和被噪声侵蚀的图像汉明距离的变化,注意,曲线开始是非常陡峭的,这个图像很容易就变成了随机噪声。


所以说,我们可以让有序变得混沌,但是反过来,我们能不能让混沌变得有序呢?
我们可以通过模拟进化来实现,我可以从随机生成的解决方案开始,对结果进行评估,然后通过对最好的个体进行变异,产生新的个体,用新的个体来替代最差的个体,反复重复很多次,就足以得到解了。


上图给出了一个简单的例子,注意我们模拟进化的时候会给予随机的变异,如果变异的结果好,我们用它替换掉原来最坏的结果。这个程序中,我们的评分是基于和目标图像的相似度,我们最快可以多快认出这个图片呢?随着图像变化,我们可以看出这是一个皇冠,虽然图像不能变得很完美,但是很快就能认出来了。
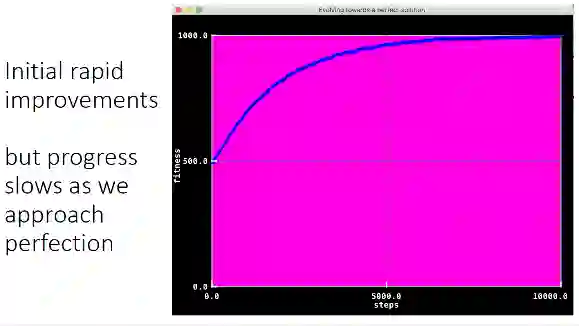
我们可参考利用模拟进化的方法得到的曲线图,可以看到一开始评分提升非常迅速,随着接近完美,评分的提升逐渐放缓了。这一点非常重要,我之所以要说这一点,因为这与算法的工作原理是非常相关的。理论上,我们总是要找到达到真正最优的那一点,而实际并非如此,实际情况是很复杂的,前半段的图像才是我们实际决策的依据。

如果我们不打算追求最优,我们也许可以在很大的搜索空间中,找到一个足够好的结果。
那么,如果遇到局部最优怎么办?这仍然是一个问题,但是游戏动态变化的这一性质,可以帮助算法跳出局部最优。
一般来讲,最大的挑战是平坦的奖励区域,比如在游戏Atari 2600和蒙特祖马的复仇中,以及推箱子小游戏,一个新颖的研究,叫做内驱动(Intrinsic Motivation)可以帮助解决这一问题。

我们可以利用这些原则来创造一个通用的Game AI,我们复制下游戏的状态,对动作序列进行进化更新来实现最好的结果。

这是我最喜欢的SFP算法:Rolling Horizon Evolution。PPT中给出了具体的算法。开始我们给定一个最优序列,目前来讲还不算最优,只是一个纯随机的序列。对于我们在游戏中要做的每一个决策,我们重复以下步骤。我们首先变化并随机增补原有的最优序列,然后在每次评估中,我们对目前最好的一个序列进行变异操作,如果在目前的前向模型下,变异后的评分大于当前的评分,那么用变异后的序列替代当前最优序列,最后循环结束后,我们返回最优的序列的第一个值。这就是我们要进行的动作,这个算法是很简单的。

举个例子来说明这个是如何工作的,假如开始的可能的动作序列是这样:推进、左转、开火、开火、左转,评分是250分,经过变异以后,左转变成了右转,后面也可能有一系列其他变化,我们发现评分增加到了350分,那么我们选择后面的这个序列代替第一个的序列,算法只考虑评分,具体动作是什么其实它并不关心。

对于前向模型,如果你已经有一个模型了,你想在这个模型里应用这个AI算法,你需要做的是设置这个模型下游戏的状态,第一步是copy,就是复制当前游戏中的状态,然后就是next,下一个动作,注意对于多玩家游戏,这个动作是多个个体的,我们还需要知道的是动作的数量,得到的分数还有这个游戏是否结束了。

这些是我们需要注意的实验参数,注意这些参数在星球大战游戏中和Asteroids游戏中的是很相似的,所以这是个非常稳定的算法。介绍一下重要的几个参数,第一个参数是否使用移位缓冲,对于每次决策,我们可以记录最优的规划,我们也可以随机重头再来,所以第一个设置是否来进行这样的记录。对于变异的强度这个参数,这个值不宜过高,在10%,20%左右即可。最后一个参数是对手的模型,这个只应用于多玩家游戏。

我们来看看这个算法如何处理很复杂的游戏,比如星球大战,(顺便提一句,这个游戏很好玩),不知道大家有没有玩儿过,这个游戏在苹果或安卓系统的手机上是可以下载到的。

这是星球大战游戏的规则,每个行星上都以一定速度产生飞船,行星是有主人的,可以是游戏中的1号玩家、2号玩家或中立,注意中立行星不产生飞船。动作的空间就是飞船的移动方向,玩家把一定数量的飞船从一个星球送到另外的星球。至于更新规则,是当一个飞船舰队达到一个星球,如果这是盟友的星球,这个星球就会加入如此数量的飞船,如果这是敌对星球,就减去相应数量。如果星球的飞船数目变为负值,那么这个星球就会易主。最终的目标是,把敌对星球从地图上消灭掉。这个游戏的规则很经典,很简单,但是其中的策略是非常复杂的。

我们设计了一个我们自己的星球大战版本并应用在一个新的Game AI 平台上,这个平台比一般平台要快10倍,非常适合SFP算法。这个平台非常灵活,我们可以设置不同的地图大小。

所以基本的策略是:尽快得到更多的星球。用飞船侵略对手星球的时候,注意使得分数变成负数即可,不要浪费太多飞船。用飞船占领中立星球的时候,注意会失去一部分飞船,所以自己的星球可能会被对手侵略,因此要非常小心。还需要注意的是不能在一个星球上面积攒太多的飞船,但是要留足飞船防止对手侵略。最后,还要避免长途迁徙,迁徙期间的飞船是不能使用的。

这个游戏有很多复杂的参数,大家可以看到,我就不一一列举了,这给了我们一个范围很广的挑战。

具体在使用Rolling Horizon Evolution的时候,序列中的元素表示星球,在游戏引擎中,作为源和目标对进行飞船传递,我们假设有20个行星,序列长度是100,那么搜索空间是20的100次方,当然我们不用担心,因为我们不必追求最优,这是一个很复杂的游戏。有趣的是,这个游戏引擎有可能发现一些非法的动作来获取胜利,我们要做的就是把这些情况排除掉。

游戏算法实践中,这些是实际的数据,可以看到,上面序列的评分是93,转换到下一个序列是472,说明经过变异,下一个序列更好,可以替代上一个,如此循环。
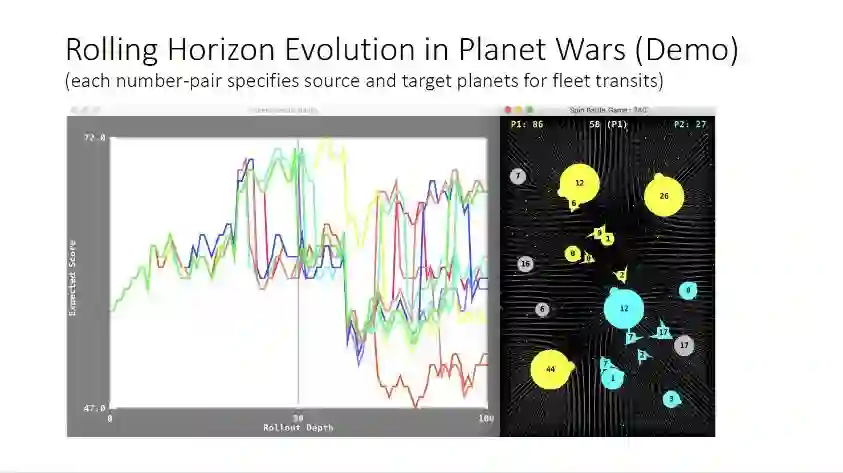
这是运行的例子,和之前展示的游戏一样,左边是实践结果评分,右边是目前的游戏状态,可以看到这个AI算法在稳定地运行。
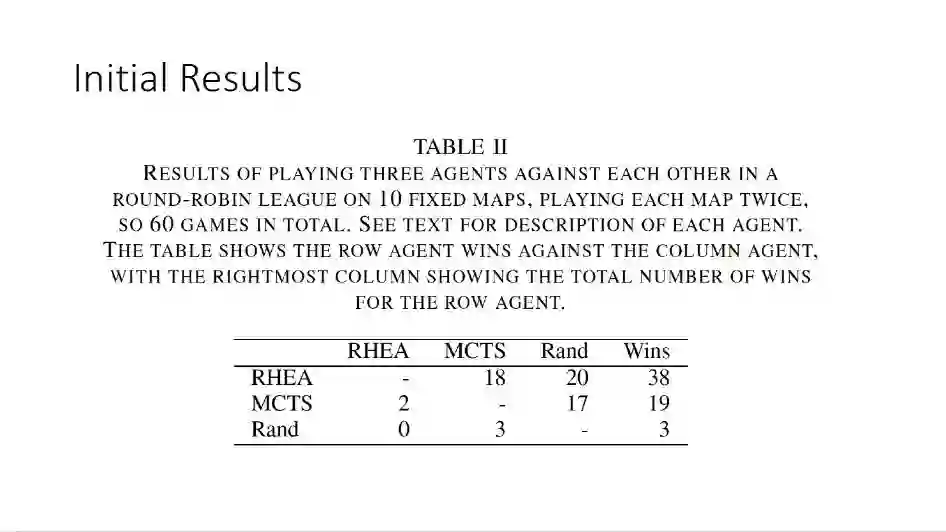
我们看一下结果,这是Rolling Horizon Evolution和蒙特卡洛树搜索以及随机策略游戏的结果,可以看出,这个算法在绝大多数比赛取得了最好的结果,这个简单的算法给出了更好的性能。

我现在正在进行的研究,是针对于更复杂的游戏,比如战争迷雾,这类策略对战仿真。

比如这张PPT中的炸弹超人,有个游戏有很多的技巧,我们使用SFP方法,并和NeurIPS会议的获胜者进行了对比,游戏中需要考虑部分可见的情况,这些都是在我们Java版本下的游戏中完成的。在这个游戏中,我们发现对于SFP方法,一个非常有趣的事实是,这种方法会选择我们看起来非常愚蠢的策略,但是它确实是有效的,非常令人惊讶。
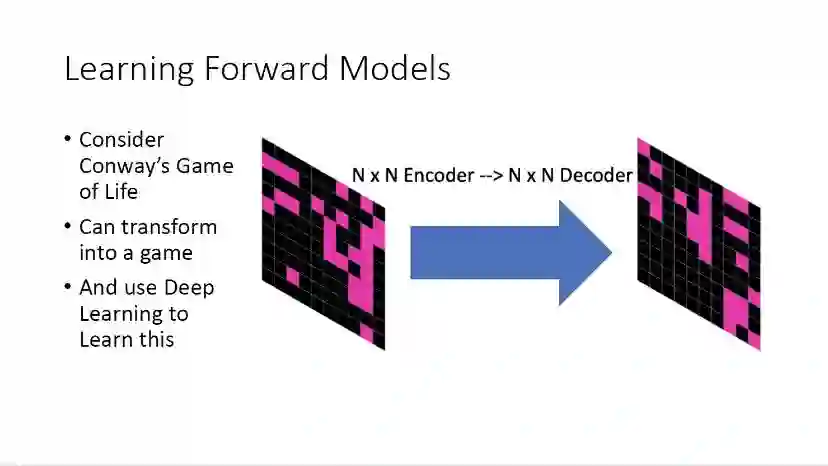
学习前向模型是一个非常有趣的问题。一般来讲,人们会倾向于利用深度学习的方法,采用一个编码器解码器的结构去进行学习。

但是这种方法有时候比较困难,尤其是在学习小的格子的时候,深度学习需要很长时间进行训练学习,效果并不是很好,因此我们采用学习局部模型的方法。
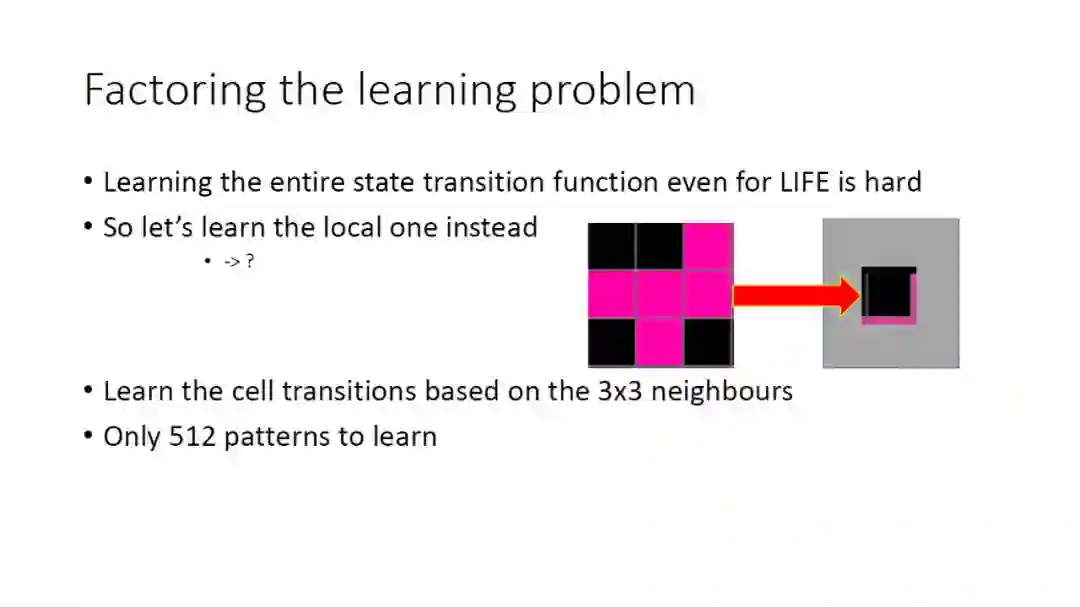
我们知道,在现实的游戏中,学习一个完整的状态转移函数非常困难,因此我们可以聚焦在局部区域,学习局部的模式,比如可以在一个3乘3的邻域内学习当前元胞的状态转移,这样需要学习的格子数目就大大减少了,这样的方法非常有效。

我们可以尝试评估已经学习到的模型,这个可以看作一个监督学习训练过程,或者我们可以做出一个N步的预测来评估这个模型,我也可以直接验证游戏中的表现,所以我们有很多的评估方法,这些评估方法下,局部模型都有着很令人惊讶的表现。相比深度学习的硬件要求,我们可以用我们的笔记本电脑,几分钟完成这个学习过程。
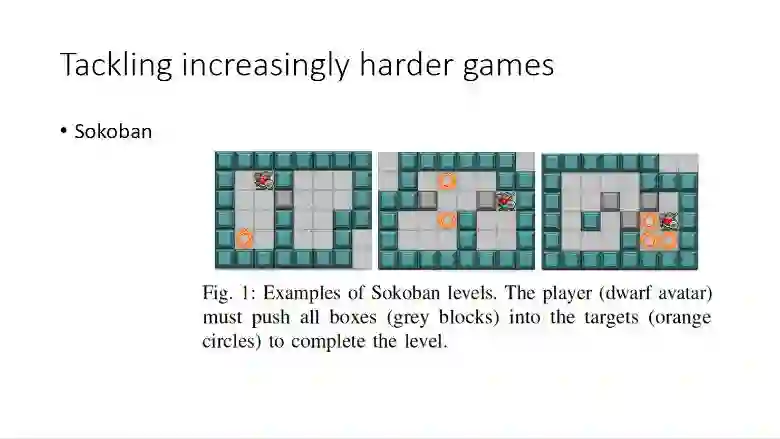
例如推箱子,这属于一个解谜游戏,如最左边的图所示,如果我们想把箱子推到指定位置,我们得先把箱子推到另一侧,让游戏的个体能够把箱子往另一个方向推动到目标位置。

这个也可以使用局部模型,我们可以依次建立前向模型,从而确定对应动作。我们接下来还是看一些程序运行示例。首先是星球大战的示例,以及评分的实时变化。下面是推箱子的游戏,左边是依据真正的模型进行动作,右边是依据通过局部模型学习到的模型进行的动作,可以看到基本是一致的,但是有的时候也会出现一些错误,不过正如之前说的,不是完美的方法才有用,这个局部模型还是很大程度上适用的。

我们可以采用错误的游戏模型来进行实验,改变模型中的一个或多个参数。
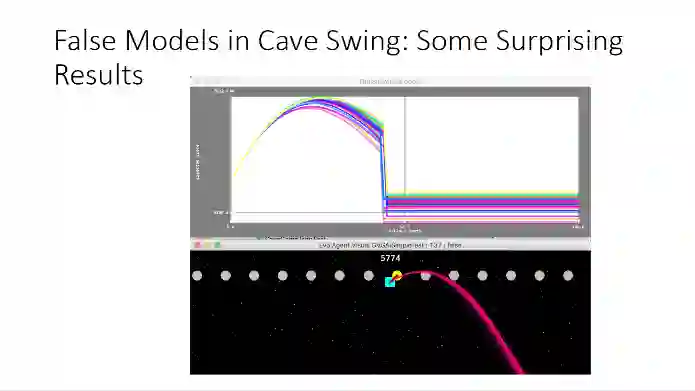
拿Cave Swing游戏举例,当我们故意把模型设为错误的,根据曲线可以看出,游戏个体会直接死亡,游戏失败,因为这个模型错误的太过严重了。
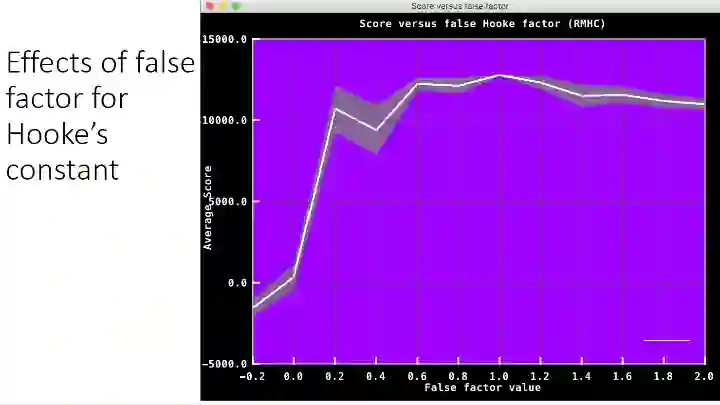
那么如果我们采用一个错误因数,可以量化错误的程度,可以看出如果模型错的不是非常多的话,还是可以保持一定的性能的。所以,模型是可以在一定程度上退化或者扰乱的,只要程度不是特别大,算法是可以适应的。

总体来说,我们使用Rolling Horizon Evolution算法玩儿游戏很多年了,近来我们参数调整的更加完善,使用了更长的Rollout长度,并在合适的地方加入了衰减因子,我们发现,一般来讲,使用移位缓冲效果会好很多,变异的强度最好要大一些,等等。我们积累了很多这样的经验。

为了应对平缓的奖励区域,我们采用改变评分函数或者加入极大似然估计等等,比如在推箱子游戏中,我们不仅仅奖励达到最终的结果的情况,而是每有一个箱子推到相应位置,都给予奖励,这个可以防止找不到解的情况出现。我们还采取了加强探索的方法以及其他的一些备选方案。

我们采用了变异变换器,重复之前的动作去获取更好的动作探索。
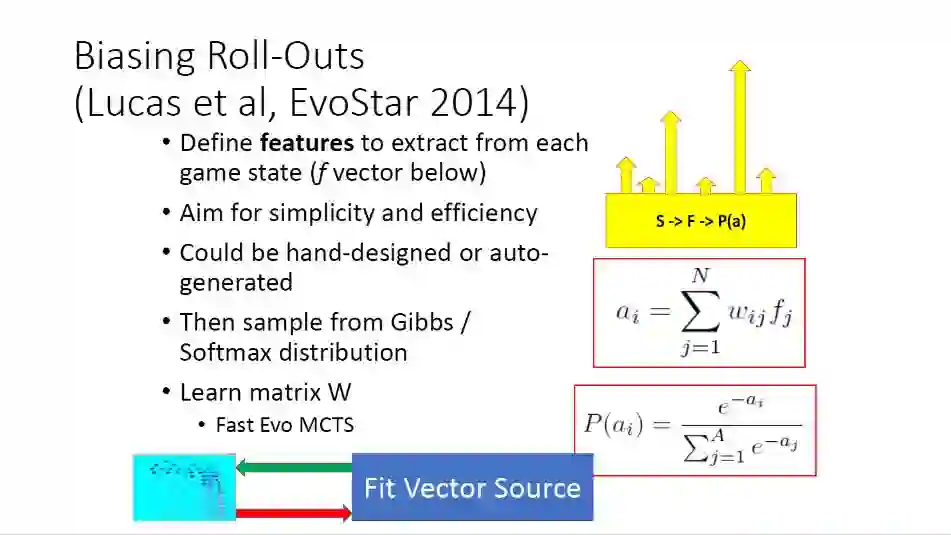
另外还有偏置Roll-Out 的方法,具体细节我就不再详细说明了。

这里还有一些开放的挑战,比如我们如何采用长期的强化学习来提升性能,如何更好地学习前向模型,当然目前的局部方法已经很好了,采用错误的模型参数进行的实验说明,不是最完美的方法才有效。另外还有无限的动作空间问题,以及在现实世界应用的问题,这些肯定是未来需要解决的问题。

总结一下SFP方法,这是一个通用的AI工具,我相信它可以在很多问题上取得非常好的效果,同时它适应性很强,你只需要快速地复制前向模型即可。除了Game AI以外,SFP还有很多的应用场景,最近有一个新的项目,由防御科技实验室资助,将SFP方法用于真实世界的决策。谢谢大家的关注!欢迎大家提问。
问答环节
提问:前向模型到底是一个什么样的模型?这是一个地图还是一个结构?我没有看到这个模型是什么样子的。
回答:在一些游戏的场景中,这确实是一个地图,在推箱子游戏里面。我们想了解中心元胞周围环境的情况,就是我们说的真实前向模型。相比了解全部的周围情况,我们也可以采用局部模型,只关注十字的一个范围内的局部邻域,这种情况下是学习到的前向模型。这个模型更像是对于物理环境中物体动作的一个观测。
提问:那么这个前向模型的学习是特定的方法,还是有一个一般的方法?
回答:这不一定要针对模型采用特定的方法,但是也不保证有一个普适的方法,有很多方法可以使用,可以采用局部模型,也可以采用深度学习的编码器和解码器这样的结构,不过这个难度就要大很多了,而且需要很多计算资源。
提问:也就是说你预测到的任何事情都可以被称作前向模型?
回答:是的,任何可以在下一个状态预测到的都可以叫做前向模型。
提问:为什么?那么模型预测的结果可能是任何事情。
回答:但是我们要对预测到的模型进行评估,有我们介绍的三种方法,比如可以采用监督学习的方式。
提问:我的问题是,如何从游戏引擎中获得这个结果?
回答:需要说明的是,我们必须能够有这个引擎的权限,否则我们无法得到结果,这在现实应用中也是一样。
提问:如果这个状态空间是2的40次方,那么你是如何选取子空间的?
回答:我们不需要选择子空间,我们产生随机的序列,然后进行进化,我们的算法给出了惊人的性能。
提问:那么是如何确定进化迭代次数的?
回答:实验中,我们一般采用20次迭代,只有20次,足以得到合适的决策了,因为我们1秒钟要进行50次决策。



推荐阅读










