iLogtail开源之路


可观测性探讨
生活中的可观测

机遇与挑战
可观测性的数据基础
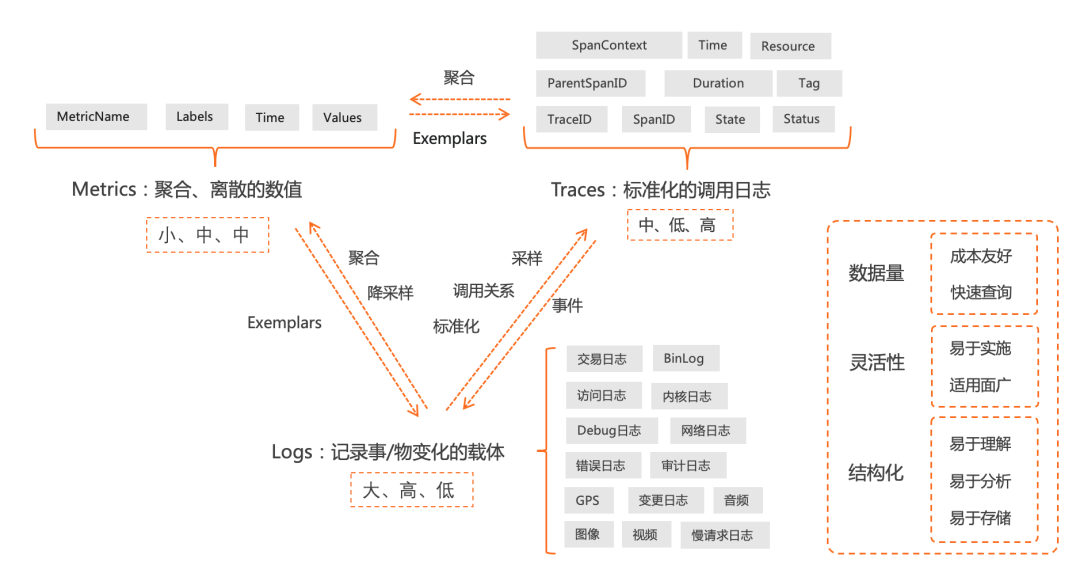
Logs:作为软件运行状态的载体,通过日志可以详细解释系统运行状态及还原业务处理的过程。常见日志类型包括运行日志、访问日志、交易日志、内核日志、满日志、错误日志等。
Metrics:是指对系统中某一类信息的统计聚合,相对比较离散。一般有name、labels、time、values组成,Metrics数据量一般很小,相对成本更低,查询的速度比较快。
-
Traces:是最标准的调用日志,除了定义了调用的父子关系外(一般通过TraceID、SpanID、ParentSpanID),一般还会定义操作的服务、方法、属性、状态、耗时等详细信息。
开源方案探讨

采集端:承载可观测数据采集及一部分前置的数据处理功能。随着云原生的发展,采集端也需要适应时代潮流,提供对K8s采集的友好支持。常见的采集端有Filebeat、FluentD/Fluent-bIt,以及我们开源的iLogtail。
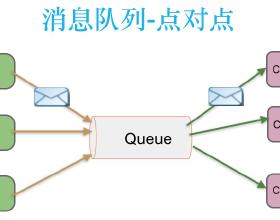
消息队列:采集Agent往往不会直接将采集到的数据发送到存储系统,而是写入消息队列,起到削峰填谷的作用,避免流量洪峰导致存储系统宕机。常见消息队列为Kafka、RabbitMQ等。
计算:用于消费消息队列中的数据,经过处理、聚合后输出到存储系统。比较常见的为Flink、Logstash等。
存储分析引擎:提供采集数据持久化存储能力,并提供查询分析能力。常见的存储分析引擎为Elasticsearch、ClickHouse及Loki。
-
可视化:借助Kibana和Grafana提供采集数据的可视化能力。
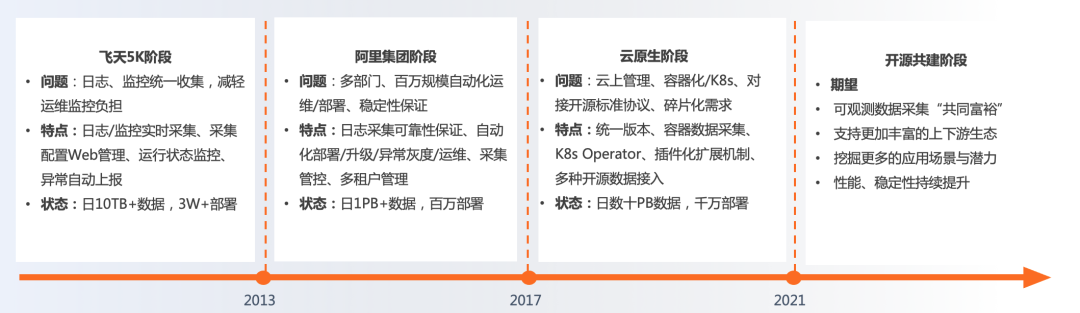
iLogtail发展历程
iLogtail核心优势

核心优势 -- 轻量、高效、稳定、可靠
轻量
高效采集
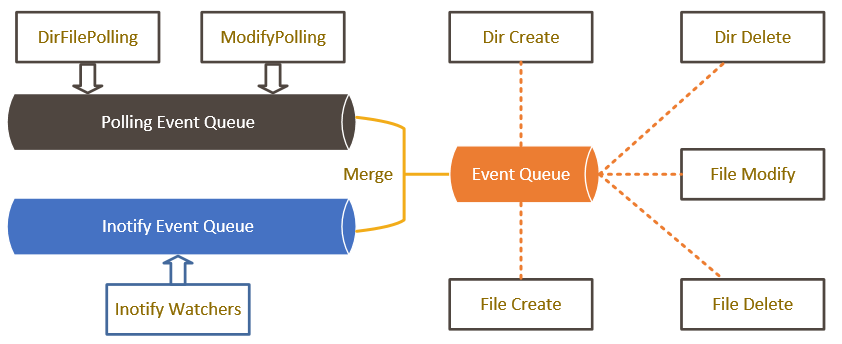
iLogtail内部以事件的方式触发日志读取行为。其中,polling和inotify作为两个独立模块,分别将各自产生的Create/Modify/Delete事件,存入Polling Event Queue和Inotify Event Queue中。
-
轮询模块由DirFilePolling和ModifyPolling两个线程组成,DirFilePolling负责根据用户配置定期遍历文件夹,将符合日志采集配置的文件加入到modify cache中;ModifyPolling负责定期扫描modify cache中文件状态,对比上一次状态(Dev、Inode、Modify Time、Size),若发现更新则生成modify event。 -
inotify属于事件监听方式,根据用户配置监听对应的目录以及子目录,当监听目录存在变化,内核会产生相应的通知事件。
-
由Event Handler线程负责将两个事件队列合并到内部的Event Queue中,并处理相应的Create/Modify/Delete事件,进而进行实际的日志采集。
事件合并:为避免轮询事件和inotify事件多次触发事件处理行为,iLogtail在事件处理之前将重复的轮询/inotify事件进行合并,减少无效的事件处理行为;
-
轮询自动降级:如果在系统支持且资源足够的场景下,inotify无论从延迟和性能消耗都要优于轮询,因此当某个目录inotify可以正常工作时,则该目录的轮询进行自动降级,轮询间隔大幅降低到对CPU基本无影响的程度。
日志顺序采集
适应不同的日志轮转(rotate)机制:日志轮转是指当日志满足一定条件(时间或文件大小)时,需要进行重命名、压缩等操作,之后创建新的日志文件继续写入。另外,不同使用日志库轮转文件的格式不尽相同,有的时间结尾,有的数字结尾等。
-
适应不同的采集路径配置方式:优秀的日志采集agent并不应该强制限制用户的配置方式,尤其在指定日志采集文件名时,需要适应不同用户的配置习惯。不管是精准路径匹配,还是模糊匹配,例如 *.log 或 *.log* ,都不能出现日志轮转时多收集或者少收集的情况。
采集可靠性
日志处理阻塞
iLogtail内部通过保持轮转日志file descriptor的打开状态来防止日志采集阻塞时未采集完成的日志文件被file system回收(在文件轮转队列中的file descriptor一直保持打开状态,保证文件引用计数至少为1)。同时,通过文件轮转队列的顺序读取保证日志采集顺序与日志产生顺序一致。
-
若日志采集进度长时间持续落后于日志产生进度,完全的不回收机制,则很有可能出现文件轮转队列会无限增长的情况,进而导致磁盘被写爆,因此iLogtail内部对于文件轮转队列设置了上限,当size超过上限时禁止后续Reader的创建,只有这种持续的极端情况出现时,才会出现丢日志采集的情况。当然,在问题被放大之前,iLogtail也会通过报警的方式,通知用户及时介入修复问题。
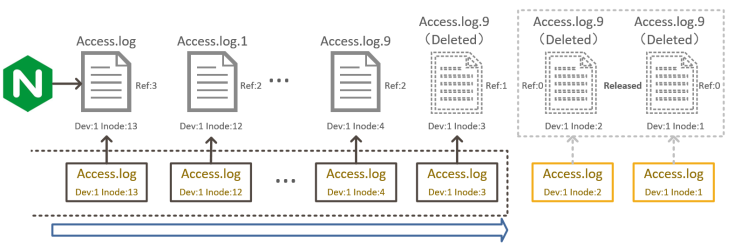
采集配置更新/进程升级
为保证配置更新/升级过程中日志数据不丢失,在iLogtail在配置重新加载前或进程主动退出前,会将当前所有采集的状态保存到本地的checkpoint文件中;当新配置应用/进程启动后,会加载上一次保存的checkpoint,并通过checkpoint恢复之前的采集状态。
然而在老版本checkpoint保存完毕到新版本采集Reader创建完成的时间段内,很有可能出现日志轮转的情况,因此新版本在加载checkpoint时,会检查对应checkpoint的文件名、dev+inode有无变化。
若文件名与dev+inode未变且signature未变,则直接根据该checkpoint创建Reader即可。
-
若文件名与dev+inode变化则从当前目录查找对应的dev+inode,若查找到则对比signature是否变化。若signature未变则认为是文件轮转,根据新文件名创建Reader;若signature变化则认为是该文件被删除后重新创建,忽略该checkpoint。
进程crash、宕机等异常情况
进程crash或宕机没有退出前记录checkpoint的时机,因此iLogtail还会定期将采集进度dump到本地:除了恢复正常日志文件状态外,还会查找轮转后的日志,尽可能降低日志丢失风险。
核心优势 -- 性能及隔离性
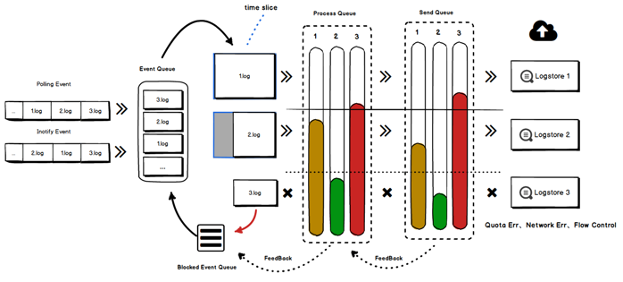
无锁化设计及时间片调度
数据读取的瓶颈并不在于计算而是磁盘,单线程足以完成所有配置的事件处理以及数据读取。
单线程的另一个优势是可以使事件处理和数据读取在无锁环境下运行,相对多线程处理性价比较高。
-
iLogtail数据读取线程可完成每秒200MB以上的数据读取(SSD速率可以更高)。
多租户隔离
多级:iLogtail从采集到输出总体要经过读取->解析->发送三个步骤,iLogtail在相邻步骤间分别设置一个队列。
高低水位:每个队列设置高低两个水位,高水位时停止非紧急数据写入,只有恢复到低水位时才允许再次写入。
-
反馈:在准备读取当前队列数据时会同步检查下一级队列状态,下一级队列高水位则跳过读取;当前队列从高水位消费到低水位时,异步通知关联的前一级队列。
极端场景处理
事件处理与数据读取无关,即使读取关联的队列满也照常处理,这里的处理主要是更新文件meta、将轮转文件放入轮转队列,可保证在配置阻塞的情况下,即使文件轮转也不会丢失数据。
当配置关联的解析队列满时,如果将事件重新放回队列尾,则会造成较多的无效调度,使CPU空转。因此iLogtail在遇到解析队列满时,将该事件放到一个专门的blocked队列中,当解析队列异步反馈时重新将blocked队列中的数据放回事件队列。
-
Sender中每个配置的队列关联一个SenderInfo,SenderInfo中记录该配置当前网络是否正常、Quota是否正常以及最大允许的发送速率。每次Sender会根据SenderInfo中的状从队列中取数据,这里包括:网络失败重试、Quota超限重试、状态更新、流控等逻辑。
核心优势 -- 插件化扩展能力
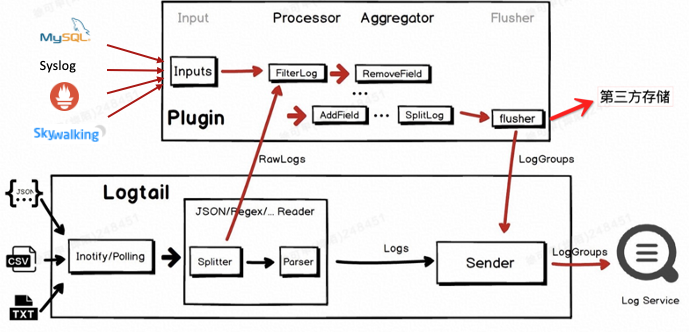
上下游生态:通过插件系统的扩展,目前iLogtail已经支持了众多数据源的接入,数据源类型覆盖Log、Metric、Trace,数据源除了文件的采集,还包括了标准协议的支持,例如HTTP、Mysql Binlog、Prometheus、Skywalking、syslog等。数据输出生态也从SLS逐步扩展到Kafka、gPRC等,未来也会支持ClickHouse、ElasticSearch等。
处理能力扩展:iLogtail采用PipeLine的设计,通过Input插件采集到数据,会经过采集配置中设定的Processor处理,之后经过Aggregator插件打包,最终通过Flusher发送到日志存储系统。数据处理环境包含数据切分、字段提取、过滤、数据增强等环节,所有插件可以自由组合。此外,针对于正则、Json、分隔符等特定格式,iLogtail还提供了C++加速能力。
-
快速迭代:开发者也可以根据自己的需求,定制开发相应的插件。因为每个插件相互独立,所以开发者只需要按照接口规范开发即可,入手门槛较低。以Processor插件接口为例,只需要实现以下接口,即可快速提供一个处理插件。
// Processor also can be a filtertype Processor interface { // Init called for init some system resources, like socket, mutex... Init(Context) error
// Description returns a one-sentence description on the Input Description() string
// Apply the filter to the given metric ProcessLogs(logArray []*protocol.Log) []*protocol.Log}
核心优势 -- K8s采集能力
部署模式
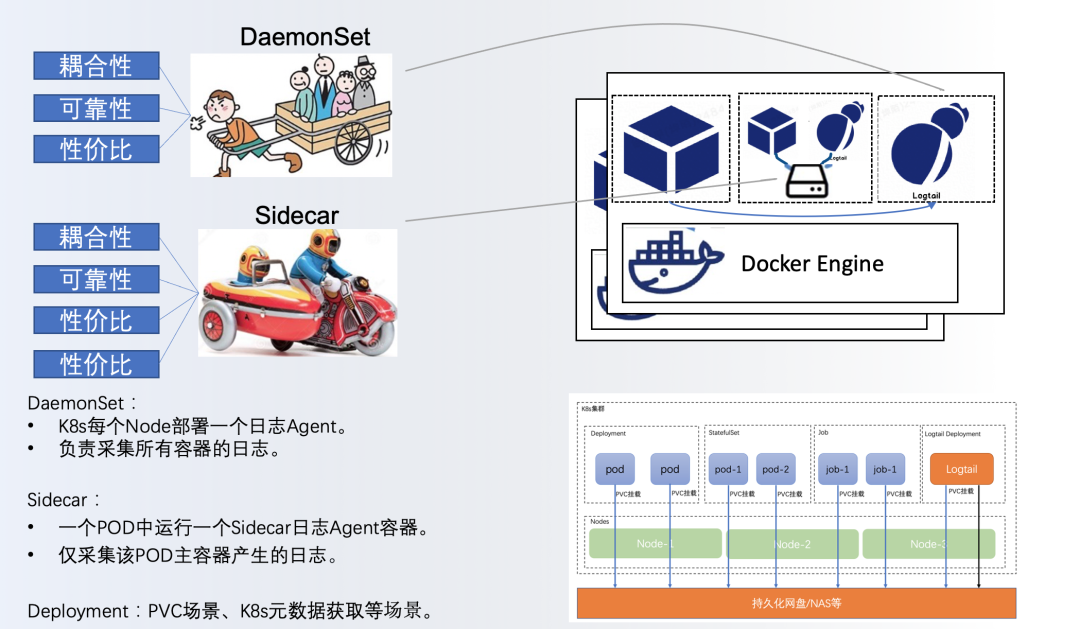
DaemonSet方式
模式:在K8s的每个node上部署一个iLogtail,由该iLogtail采集节点上所有容器的日志到日志系统。
优点:运维简单、资源占用少、支持采集容器的标准输出和文本文件、配置方式灵活。
-
缺点:iLogtail需要采集节点上所有容器的日志,各个容器之间的隔离性较弱,且对于业务超级多的集群可能存在一定的性能瓶颈。
Sidecar方式:
模式:一个POD中伴随业务容器运行一个iLogtail容器,用于采集该POD中业务容器产生的日志。
优点:Sidecar方式为每个需要采集日志的容器创建一个Sidecar容器,多租户隔离性好、性能好。
-
缺点:资源占用较多。
Deployment方式:
-
模式:当业务容器用PVC挂载日志目录或者需要全局连接API Server获取K8s元数据等场景,可以选择在集群中部署一个单副本的iLogtail Deployment进行数据采集。
采集原理
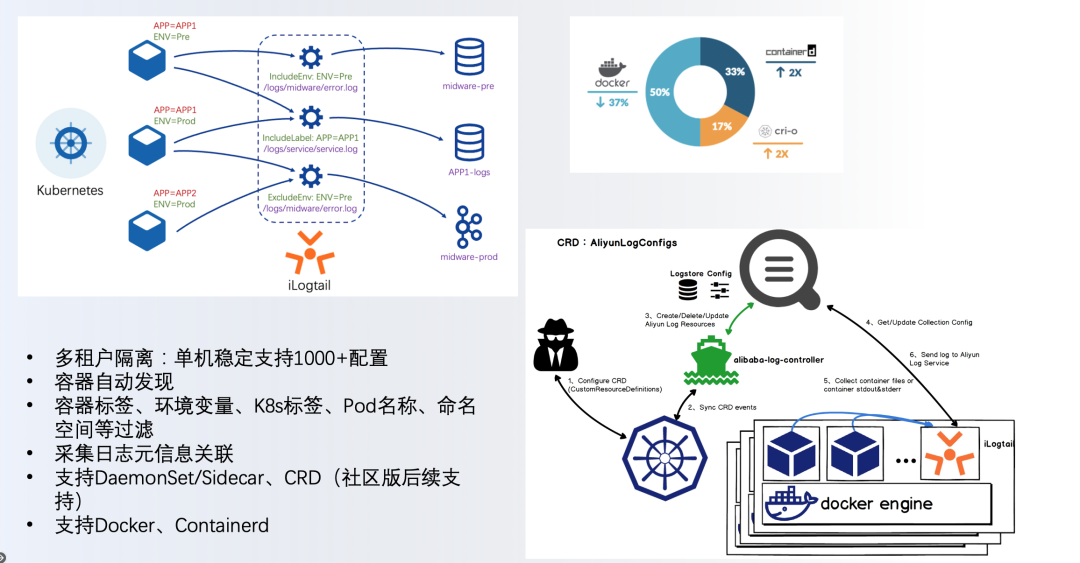
容器自动发现与释放
iLogtail通过访问位于宿主机上容器运行时(Docker Engine/ContainerD)的sock获取容器信息。
-
通过监听Docker Event及增量获取机制,及时感知容器新增与释放。
容器上下文信息获取
容器层级信息:容器名、ID、挂载点、环境变量、Label
-
K8s层级信息:Pod、命名空间、Labels。
容器过滤及隔离性:基于容器上下文信息,提供采集容器过滤能力,可以将不同采集配置应用到不同的采集容器上,既可以保证采集的隔离性,也可以减少不必要的资源浪费。
元信息关联:基于容器上下文信息和容器环境变量,提供在日志中富化K8s元信息的能力。
采集路径发现
标准输出:iLogtail可以根据容器元信息自动识别不同运行时的标准输出格式和日志路径,不需要额外手动配置。
-
容器内文件:对于overlay、overlay2的存储驱动,iLogtail可以根据日志类型及容器运行时自动拼接出采集路径,简单高效。
企业版与社区版
差异比较
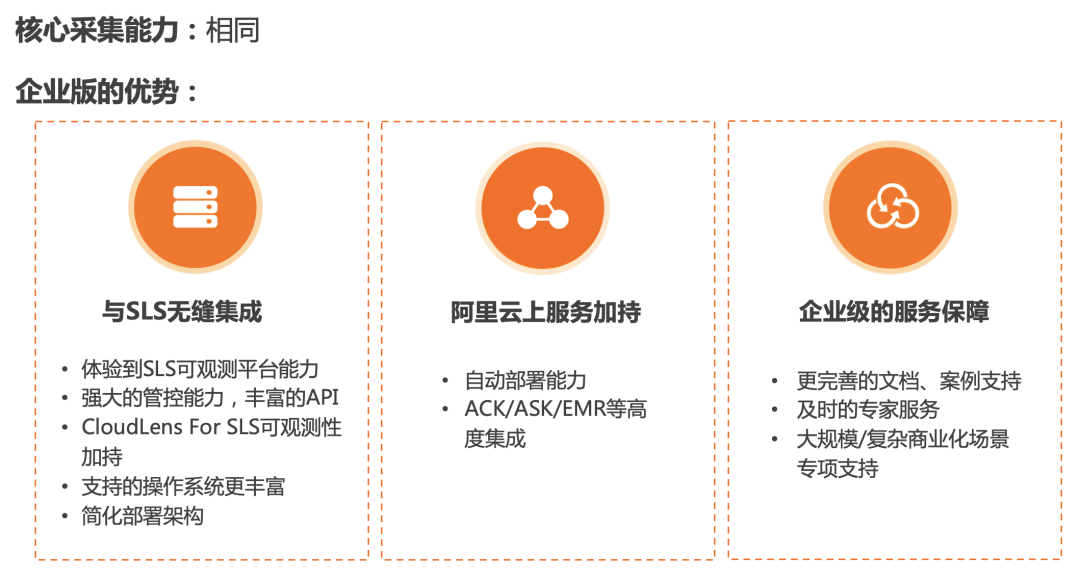
企业版:可以从阿里云SLS官方下载到。主要服务于SLS。
-
社区版:从GitHub仓库,release页下载。
作为阿里云SLS官方标配采集器,与SLS无缝集成
-
SLS平台为iLogtail提供了强大的管控能力,及丰富的API支持。 -
SLS提供了对于Log、Metric、Trace的统一存储分析能力,使用iLogtail企业版将数据采集到SLS,可以更好的构建各类上层应用。借助SLS可以实现日志上下文预览、Exactly Once等高级特性。 -
借助SLS平台,可以实现第三方Agent的管控能力。例如,未来SLS也会跟DeepFlow进行深度集成。 -
SLS作为可观测平台,既可以承载可观测数据存储分析的功能,也可以承载流量管道的作用,可以简化架构部署。 -
CloudLens For SLS为iLogtail采集状态、数据流量监控提供了便捷的手段。 支持的操作系统、系统架构更加丰富,企业版支持Windows系统跟ARM架构。
阿里云服务加持
自动化安装部署能力更高,借助阿里云的运维服务,可以实现iLogtail批量自动安装。
-
与阿里云ECS、ACK、ASK、EMR等高度集成,可以一键安装部署,采集数据可以快速接入,内置分析。
企业版服务上的保证
-
SLS官方提供企业应用场景下最全最及时的文档/最佳实践支持 -
及时的专家服务(工单、群支持)与需求承接。 大规模/复杂场景专业化支持:比如K8s短job,单节点大流量日志、大规模采集配置等。
基于SLS的云原生可观测平台

开源社区展望

关于iLogtail
GitHub: https://github.com/alibaba/ilogtail
社区版文档:https://ilogtail.gitbook.io/ilogtail-docs/about/readme
企业版官网:https://help.aliyun.com/document_detail/65018.html
阿里云产品评测—阿里云 云效
发布评测赢取CHERRY机械键盘,天猫超市卡等好礼!
点击阅读原文查看详情。