随着以深度学习为代表的AI技术的快速发展,智能模型的训练应用模式逐渐由“大炼模型”向“炼大模型”转变。大模型研究在近年来发展迅速,模型的参数量以惊人的速度扩展。北京智源人工智能研究院最近发布《A Roadmap for Big Model》由悟道大模型研究项目负责人,智源学术副院长,清华大学计算机系教授唐杰牵头,从大模型基础资源、大模型构建、大模型关键技术与大模型应用探索4个层面出发,对15个具体领域的16个相关主题进行全面介绍和探讨。非常值得关注。
![]()
随着深度学习的快速发展,对多个下游任务进行大模型(Big Models, BMs)训练成为一种流行的范式。研究人员在BM的构建和BM在许多领域的应用方面取得了各种成果。目前,缺乏对BMs总体进展进行梳理和指导后续研究的研究工作。本文不仅介绍了BM技术本身,还介绍了BM技术运用BMs进行BM训练和应用的前提条件,将BM评审分为资源、模型、关键技术和应用四个部分。我们在这四个部分介绍了16个具体的BM相关主题,它们是数据、知识、计算系统、并行训练系统、语言模型、视觉模型、多模态模型、理论与可解释性、常识推理、可靠性与安全性、治理、评估、机器翻译、文本生成、对话和蛋白质研究。在每个课题中,我们对当前的研究进行了总结,并提出了未来的研究方向。最后,我们从一个更全面的角度总结了BM的进一步发展。
地址:
https://www.zhuanzhi.ai/paper/7db57dc36504c3944bde63cfede93541
Arxiv:https://arxiv.org/abs/2203.14101
在这个跨学科的科学时代,许多科学成就,特别是人工智能(AI),给人类社会带来了戏剧性的革命。随着人工智能的快速发展,特别是深度学习技术的出现和快速发展,人工智能已经进入大规模工业应用阶段。人工智能早期的研究主要集中在学习算法上,其次是深度学习体系结构。传统的机器学习模型主要依赖于手工制作的特征和统计方法。深度学习模型可以从数据[1]中自动学习特定于任务的特征。近年来,深度学习模型如卷积神经网络(convolutional neural networks, CNNs)[2,3]、循环神经网络(recurrent neural networks, rnn)[4,5]、生成对抗网络(generative adversarial networks, GANs)[6,7]、图形神经网络(Graph Neural Networks, GNNs)[8,9]被广泛应用于各种AI任务中。尽管深度学习在科学研究和工业应用方面取得了成功,但由于数据匮乏,在特定领域的性能有限。训练模型需要大量的标注数据才能保持良好的性能。随着深度学习研究的不断深入,高质量人工智能数据集的构建也得到了广泛的关注[10,11]。然而,手动数据标记过程是昂贵和耗时的。由于特定任务的可用数据有限,情况变得更糟。为了减少数据集构建的工作量,我们希望调整在现有数据上训练的模型来处理新的特定任务。如何实现迁移学习过程是人工智能领域的一个重要研究课题。
理解、保留、应用和迁移的学习过程形成了人类的知识基础。我们人类可以在以前的学习基础上处理新的问题。奇妙的学习过程让人们从几乎一无所知变成特定领域的专家。人类行为启发了人工智能的研究。与从头开始训练人工智能模型不同,迁移学习[12]提出了一种两阶段解决方案,以提高模型泛化,而无需花费太多的数据标记工作。预训练过程从源任务中获取知识,而微调过程将所学知识转移到目标任务中。在预训练阶段获得的知识可以在有限的数据下进行微调。迁移学习技术最早应用于计算机视觉(CV)领域,目前已有大量人工构建的图像数据集,如ImageNet[10],为模型的预训练提供了理想的来源。模型通过预训练过程吸收了大量的视觉知识后,只需对少量的任务相关数据进行调整,就可以在许多下游任务中表现良好。在这种情况下,通过大模型(Big Model, BMs)探索CV领域的趋势被触发并传播到许多具体任务中,包括图像分类[13]、图像标题[14]、图像分割[15]和目标检测[16]。
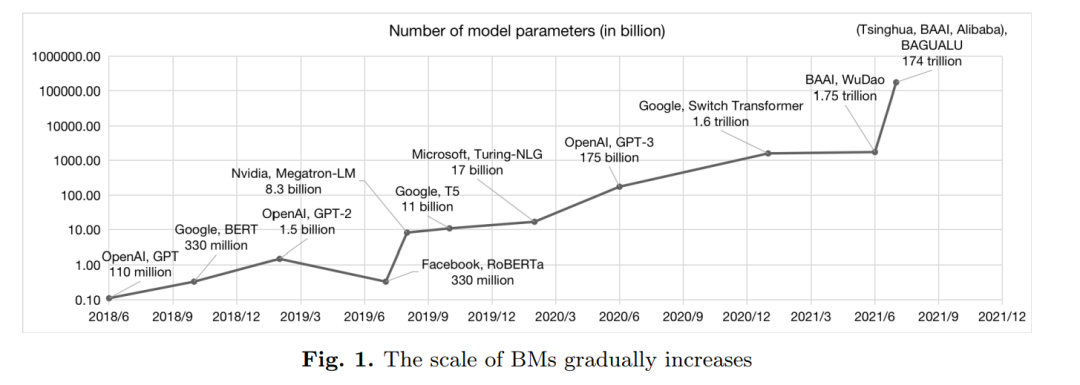
随着BM在CV领域的成功,在自然语言处理(NLP)领域也有类似的研究。然而,自深度学习兴起以来,一个长期存在的问题一直困扰着文本处理。梯度消失和梯度爆炸是自然语言处理中常见的两种导致意外输出的现象。对于NLP中的BM的初步研究主要集中在Word2Vec[17]等浅层网络上。然而,浅层网络无法捕捉词语和句子的各种语义信息。例如,一个多义词在不同的句子中表现出不同的意思,而浅层网络则很难区分。虽然像RNN这样的网络通过包含上下文信息来解决上述问题,但深度仍然是一个难点。随着Transformer 网络结构的出现,在自然语言处理领域构建深层网络模型成为可能。在此之后,预训练技术在NLP中取得了一系列的突破。包括BERT[18]和T5[19]在内的大模型BM经过训练,在许多下游任务中获得了最先进的性能。1750亿参数的GPT-3在几个下游NLP任务上表现良好,尤其是生成任务。增大参数尺度使BM模型能够更好地捕获训练数据中包含的语言知识。GPT-3的研究表明,扩展模型大大提高了与任务无关的、少样本的性能,有时甚至与之前最先进的微调方法[20]相比具有竞争力。GPT-3模型的重要发现促进了大模型及其相关技术的研究。大模型的参数规模从数十亿快速增长到数万亿,并保持着急剧上升的趋势。通过不断增大模型参数,研究人员试图探索大模型的性能改善极限。
目前,实现人工智能的常见模式是结合数据、计算能力和算法来构建模型。近年来,传统的模型构建模式“针对不同任务的不同模型”逐渐向“针对不同任务的大规模预训练模型”转变。在这种新模式中,我们也将大规模预训练模型简称为大模型(BMs)。研究人员尽可能地收集数据,设计先进的算法,基于大规模计算系统,针对不同需求的用户训练大模型。
随着大模型研究成为人工智能的焦点,大模型有可能在未来几年内引领技术转型,带来新的产业格局
。更具体地说,这种新的工业模式可以类比于电力供应系统。大模型扮演着“智能生产者”的基本角色,能够在海量计算能力的支持下产生高质量的智能能力,服务于各种人工智能应用。通过大信息模型和大仿生模型的发展,可以加快电子信息和生物医学领域的研究进程。同时,大模型的发展可以帮助创新型企业和个体开发者构建高智能应用,从而促进实体经济的智力更新。
深度学习阶段的人工智能研发有几个严重的痛点
。首先,模型的泛化是一个常见的问题,这意味着在一个特定的应用场景下训练出来的模型并不适用于另一个应用场景。不同领域之间的转换需要从零开始的培训,导致模型培训成本较高。其次,目前的模型训练基本上是“手工制作”的模式,因为调整和调优参数需要大量的手工工作,需要大量的人工智能专业人员参与。第三,模型训练对数据质量要求高,需要大规模标注数据。一些领域数据的缺乏制约了人工智能技术的应用。这些问题导致了人工智能开发和应用中成本高、效率低的问题。人工智能人才短缺和高昂的研究成本,也使这些小企业更难在其工业场景中训练特定任务的模型。因此,任务型模型的“自我训练自我使用”模式与人工智能的发展趋势形成鲜明对比,成为人工智能技术广泛应用的障碍。由于大模型具有很强的泛化能力,因此训练大模型可以成为一种潜在的解决方案。大模型可以用于不同的任务,只需稍微调整,甚至无需额外调整。在这种情况下,小企业可以直接调用大模型界面来进行AI研究,而这只需要很少的算法专业人员就可以完成。从而大大降低了开发智能应用程序的研究成本。Li et al.[21]从概念的角度指出,基础模型的应用使得自监督学习和微调方案逐渐成为主流方法,并带来智能体认知能力的进步。然而,基础模型的一个隐患是,它们的任何缺陷都会被其下游的所有模型所继承,从而迅速覆盖整个基础模型社区。上述基础模型称为BMs,在中文语境中称为大模型。接下来的章节将介绍大模型的特点,为什么它会成为一种趋势,以及大模型面临的技术挑战。
![]()
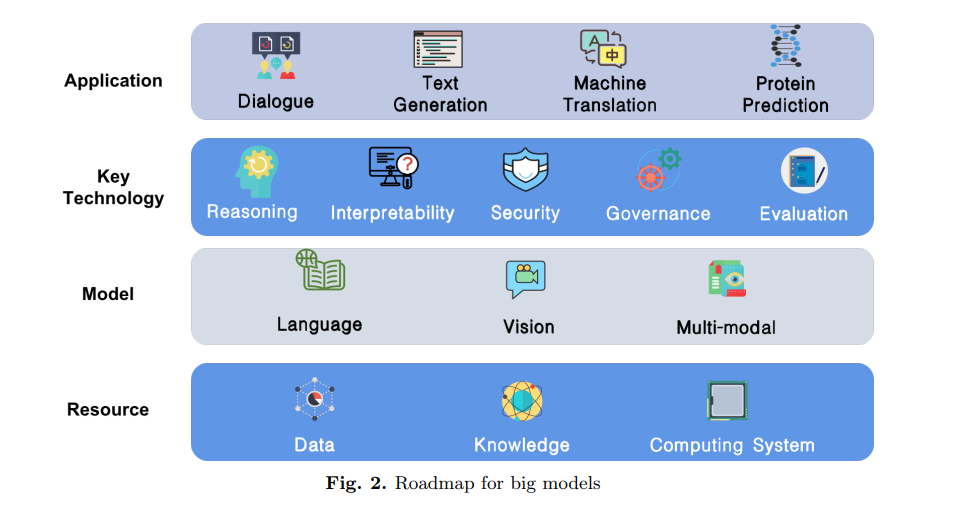
对于大型模型的技术挑战和未来发展方向缺乏系统的分析和实际的讨论。为了更好地推进大模型研究,有必要制定一个路线图,展示大模型的训练条件、关键技术和下游应用。
![]()
大模型框架的底层资源层负责提供基本的支持。资源层包括数据、知识和计算系统三个方面。
本节介绍用于模型训练的基本数据集资源。数据质量是影响模型性能的最关键因素之一。首先,分别介绍了一些已有的语料库。然后,详细阐述了数据集构建中的数据采集、数据清理等技术。接下来,我们提出了一些常见的数据集问题,如重复,隐私问题,道德问题和分布不均。最后,讨论了大模型数据集的进一步发展方向。
知识通常用知识图谱表示,知识图谱是描述现实世界中概念、实体及其关系的网络。本节介绍了知识的性质和相关技术,展示了知识与大模型的结合。首先给出了知识图谱的一些初步概念,并对知识融合方法进行了说明。然后描述了基于大模型的知识获取方法。此外,将知识注入到大模型中显示了知识增强大模型的优势。在本节的最后,提出了一些未来的发展方向。
经典超级计算集群主要用于大规模科学计算中进行高精度的复杂计算。随着过去几年深度学习的扩展,对GPU计算能力的需求也在不断增加。GPU的实现大大加快了神经网络算法的实现,这使得GPU计算集群成为当前研究的重点。在这一部分,我们打算介绍大模型训练所需的计算系统。
随着模型参数尺度的扩大,大模型的计算需求也在迅速增加。增加的计算需求需要高性能计算系统和并行计算技术来支持。本节详细介绍了并行计算方法的发展过程。分别阐述了现有的几种有效的并行计算技术。此外,在本节的最后,我们提出了下一代大模型计算系统的蓝图。
自然语言处理(NLP)是机器学习中最重要的领域之一,各种大模型的建立都是为了解决自然语言处理任务。本节从语言表示方法入手,逐步说明完整的NLP大模型训练过程。此外,我们还讨论了NLP大模型的一些高级问题,包括模型分析、长文档建模、多任务学习、持续学习、知识增强的NLP和模型加速。在本节的最后,我们对如何使机器理解复杂的语义提出了一些展望。
随着人工智能的快速发展,计算机视觉领域在理论研究和实际应用方面都取得了长足的进步。精心设计的深度模型具有感知视觉世界和处理各种下游视觉任务的能力,正在为现代信息社会的许多方面带来一场前所未有的革命,如智能机器人和自动驾驶。然而,对不断扩大的深度模型数据的需求日益增长,也给社区的进一步发展带来了挑战,大量的任务特定数据的标注成本和相应的培训资源费用难以承受。因此,引入预训练技术来弥补训练资源的限制和对视觉特征表征能力的更高要求之间的差距。
人类可以从现实世界的多模态信息中学习。为了模拟人类的智能,有必要对模型进行大规模的多模态数据训练。在多模态大模型领域,关键的挑战是如何处理多模态数据的异构性,并利用它们进行模型训练。除了文本和图像模式,其他模式的大型模型,如视频和音频,也在本节中介绍。此外,我们还对多语言形式的多模态大模型进行了进一步的解释,并提出了一些值得进一步研究的方向
-大模型的理论和可解释性(第9节)
近年来,大型模型获得了巨大的实证成功。然而,尽管实践者已经发现了许多有用的技术,但对于大模型仍然缺乏坚实的理论理解和可解释性。模型互通性的研究主要包括三个方面:可视化地解释大模型学到的知识或说明重要输入;解释网络诊断模型的表示能力;结合人工收集的符号知识库对模型进行解释。在本部分中,我们从这三个方面简要介绍了现有的研究进展,并提出了一些未来的研究方向。
-大模型的推理(第10节)
近年来,人工智能技术已经基本实现了视觉、听觉等感性智能,但实现思维、推理等认知智能仍是一个挑战。在解决问题的过程中,人类可以通过推理路径和节点来理解整个过程,但目前的深度学习算法将解决这些问题的大部分视为一个黑盒。为了更好地模拟人类解决问题,推理是一个重要的研究方向。在这一部分中,我们介绍了常识推理的基本概念,包括常识推理的定义、方法和基准。在本节的最后,提出了一些未来的发展方向。
-大模型的可靠性和安全性(第11节)
近年来,人工智能技术正从研究性研究走向我们的日常生活,这是一个不可阻挡的趋势。人工智能的应用给人们带来了很多便利,比如人脸识别和信息检索。然而,这些先进的技术也引起了人们的安全担忧。在这一部分中,我们介绍了大模型提出的可靠性和安全性问题及其相应的防御方法。此外,还提出了提高BMS可靠性和安全性的若干方向。
-大模型的治理(第12节)
随着大模型的快速发展,一些安全和伦理问题暴露在公众面前,这意味着需要建立一个强有力的治理体系。在本节中,首先阐述了大模型治理的定义、实施治理的原因和治理目标。然后对当前治理工作的概况进行了总结和介绍。最后,我们指出了一些有待解决的问题,并提出了一些改进大模型治理的建议。
-大模型评估(第13节)
大模型评价是指对性能、效率等特征进行评价的活动。评价结果对提高模型的可解释性和指导大模型的修改具有一定的指导意义。因此,大模型评价的研究是值得探讨的。在本节中,我们分别介绍了一些现有的性能、效率和多模态评估的基准和相应的数据集,并说明了各个评估方向的几个问题。在本部分的最后,提出了一些有前景的工作。
上层负责将大模型更好地适应于特定领域,称为应用层。我们介绍了几种常见的应用,包括对话、文本生成、机器翻译、信息检索和蛋白质预测。
- 机器翻译中(第14节)
随着全球化趋势在现实世界的加快,机器翻译的应用变得越来越重要。本节将介绍大模型在机器翻译任务中的应用。我们首先给出了机器翻译的一些基本信息,然后列出了一系列可以应用于机器翻译的大模型。然后,提出了翻译工作的三大类预训练: 单语预训练、多语预训练和语音翻译预训练。此外,还提出了基于大模型的机器翻译评价方法。最后,阐述了该领域面临的挑战和未来的发展趋势。
- 文本生成(第15节)
文本生成是将语言或非语言输入转换为文本的任务。目前,大型模型在文本生成任务中表现出了良好的性能。为了更好地理解目前基于大模型的文本生成的工作和未来的发展,我们在这个部分进行了一些讨论。我们介绍了三种类型的文本生成任务,它们是文本到文本的生成、数据到文本的生成和视觉到文本的生成。此外,还详细说明了自回归和非自回归的生成方法。为了展示大模型与文本生成任务之间的联系,本文介绍了一系列已经应用于文本生成的大模型。最后,提出感知世界知识、可控世界知识和无微调世界知识的三个主要探索方向。
- 对话(第16节)
对话是大模型的一个重要的下游应用,它可以实现机器与人之间的交互和沟通。在本节中,我们首先介绍几个大型的对话模型,如DialoGPT, Meena和EVA。在此基础上,总结了本文的三个重点研究方向。这些方向包括对话中的人物角色和个性化、对话中的知识增强、对话中的移情和情感支持。接下来,我们介绍了几个有趣而新颖的对话模式应用场景,并对进一步的开发提出了一些建议。
- 蛋白质预测中(第17节)
了解蛋白质的功能,设计蛋白质的功能,是在治疗方面取得突破的关键。近年来,大模型在蛋白质建模和预测领域取得了巨大的成功。在本节中,我们首先介绍应用大模型在该领域取得的一些突出进展。这些成果包括蛋白质功能预测、蛋白质结构预测和蛋白质设计。此外,本节最后还讨论了蛋白质建模和特定下游任务的一些有价值的研究方向。
参考链接:https://mp.weixin.qq.com/s/qUmmEFks4cERXMqqgdfAzg
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取70000+AI(AI与军事、医药、公安等)主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取70000+AI主题知识资料