GAN | 每个人都能用英伟达GAN造脸了(附下载链接)
点击蓝字关注我们


扫码关注我们
公众号 : 计算机视觉战队
扫码回复:ProGAN,获取下载链接

最近突然对GAN特别感兴趣,今天就开始进入该领域,我也从基础的开始,今天就先说说Nvidia的第一版本GAN。
简述
描述了生成对抗网络的新训练方法。关键思想是从低分辨率图像开始,逐渐增大生成器和判别器,并在训练进展过程中添加新的处理更高分辨率细节的网络层。这大大地稳定了训练,并让我们生成了前所未有高质量的图像,例如,分辨率为1024×1024的CelebA图像。

还提出了一种简单方法,让生成的图像更加变化多端,并在无监督的CIFAR10中实现了8.80的初始分数,创下了记录。
此外,我们还描述了几个小的实现细节,对防止生成器和鉴别器之间不健康的竞争非常重要。

最后,我们提出了一个从图像质量和种类变化方面衡量GAN结果的新指标。作为额外的贡献,我们构建了更高质量的CelebA数据集,方便以后研究人员就分辨率最高达1024×1024像素的图像进行探索。
背景
目前生成高分辨率图像的问题
-
高分辨率放大训练分布与生成分布之间的差异,进而放大梯度问题(WGAN中有详细介绍); -
由于内存的约束,需要使用更小批量去处理数据,会导致训练不稳定。

-
GAN目前遇到的问题
-
多样性问题,传统GAN倾向于捕获训练集多样性中的一种; -
模型崩塌(判别器处理过度,导致G和D之间不健康竞争,成为猫捉老鼠的游戏)。
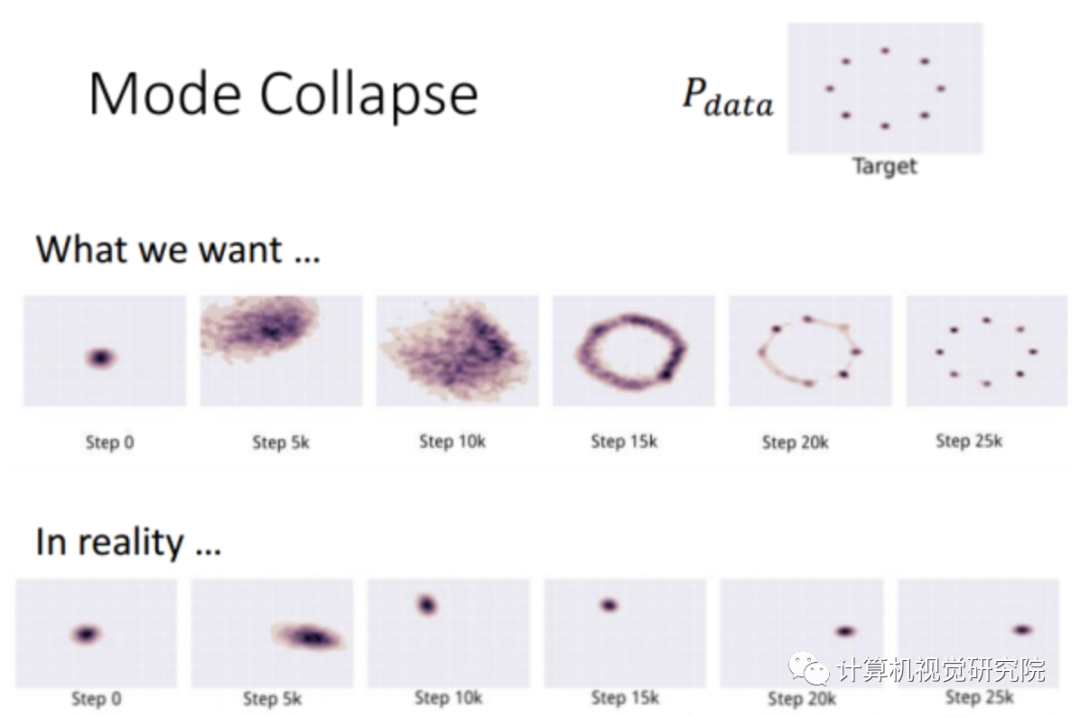
新算法
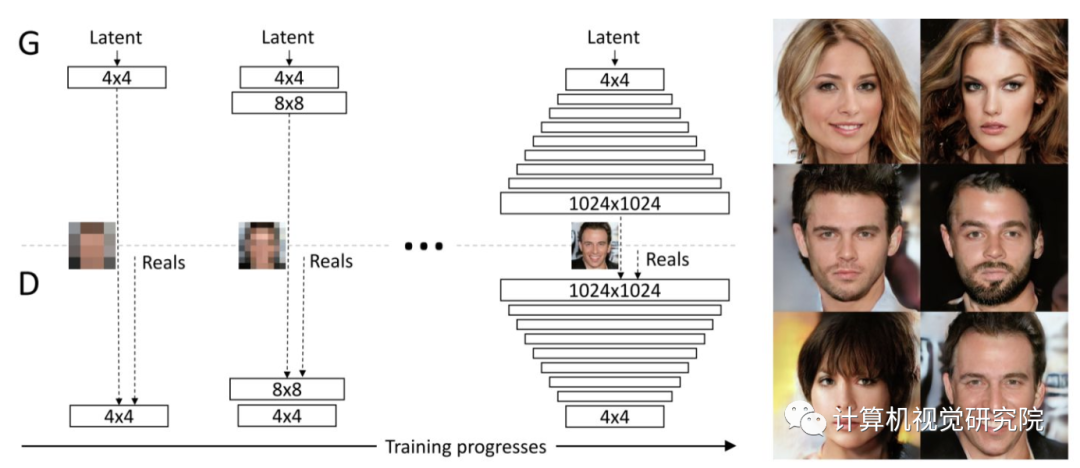
通过使用逐渐增大的GAN网络(先训练4x4,然后训练8x8,然后... 直到 1024x1024),配合精心处理过的CelebA-HQ数据集,实现了迄今最真实的GAN效果。
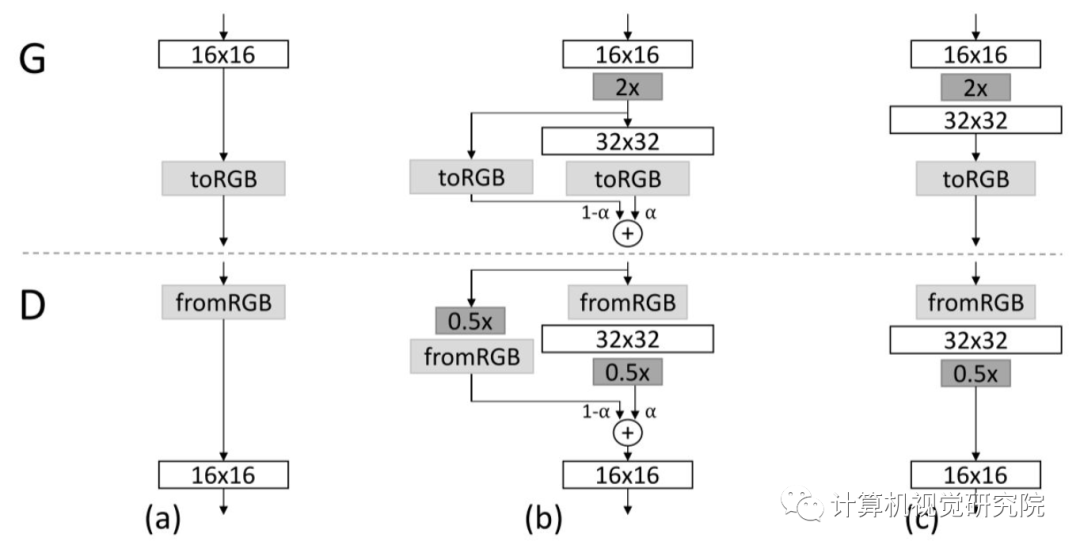
用到的渐进式生成的方式是先训练出低分辨率的图片,再逐步增加网络结构提升图片质量。生成器和分类器是镜像生成的,N×N是指这部分的卷积网络作用在N×N分辨率的图像上,在分辨率增长的过程中采用fade in形式的增长,早期分辨率低时学习到的是大规模结构特征,再分辨率逐渐增加的过程中,转移到细节逐步学习。优势就是:增强训练稳定性,减少训练时间,提高图像质量。
Fade In形式
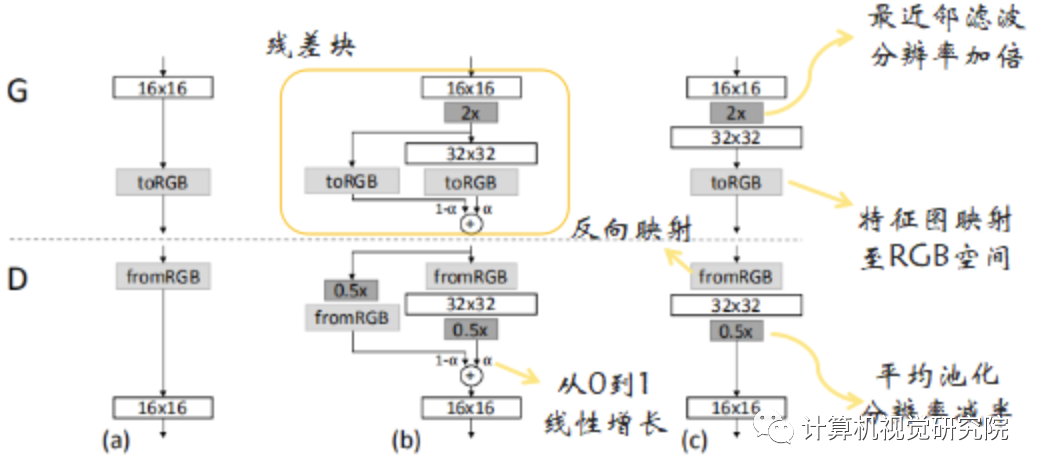
引入残差块的概念,使网络逐步适应高分辨率,直至构建成新的网络结构,这样有助于利用前期训练好的网络。在实际训练中,先将4×4的网络训练到一定程度(文中的条件是判别器判别了800k真实图片),然后再两个阶段进行交替:fade in网络,也即b;稳定网络,也即c。每个阶段均训练到一定程度后进入下一阶段。在训练阶段,真实图片也需要跟生成图片一样,根据α值融合两个分辨率的图像,然后输入到判别器中。
增加多样性-MSD
-
优化loss让网络自己调整–WGAN
-
设计衡量多样性的度量加到判别器中–imporoved GAN-MD
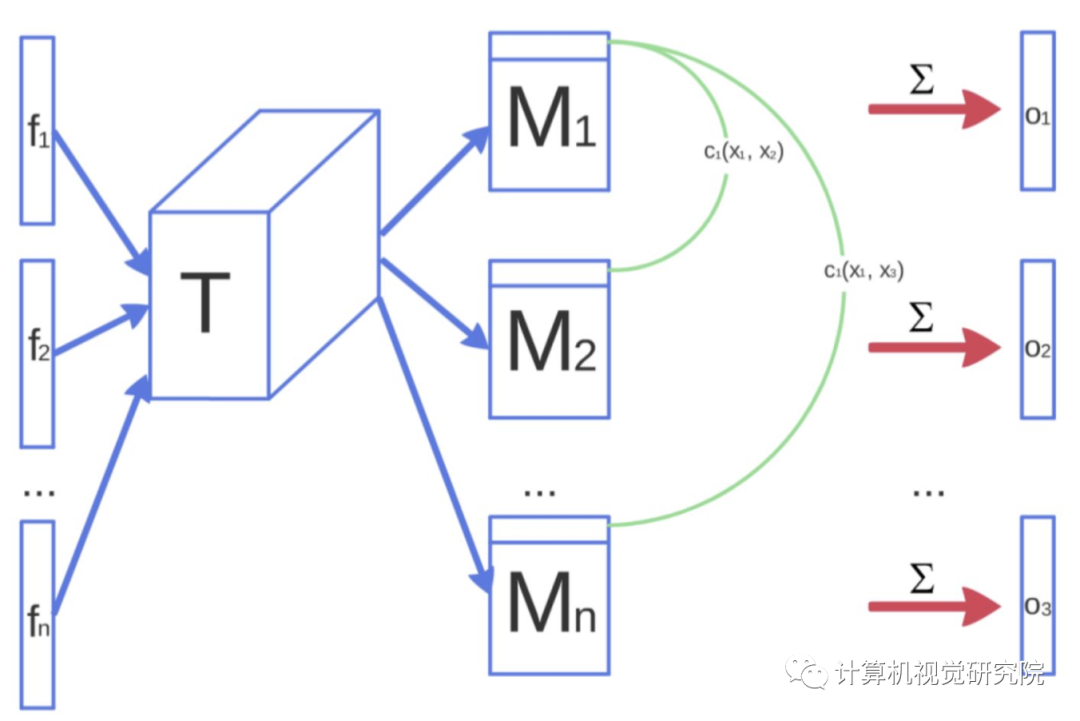
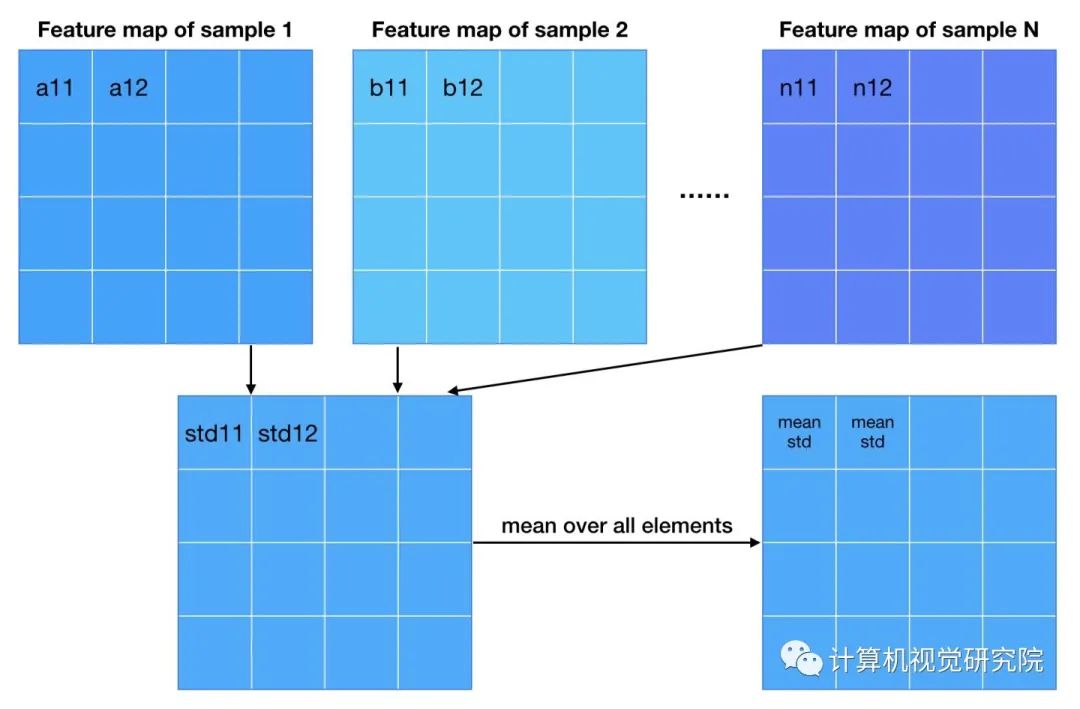
而PG-GAN不引入新的参数,利用特征的标准差作为衡量标准。
Normalization
从DCGAN开始,GAN的网络使用batch(or instance) normalization几乎成为惯例。使用batch norm可以增加训练的稳定性,大大减少了中途崩掉的情况。作者采用了两种新的normalization方法,不引入新的参数(不引入新的参数似乎是PG-GAN各种tricks的一个卖点)。
第一种normalization方法叫pixel norm,它是local response normalization的变种。Pixel norm沿着channel维度做归一化,这样归一化的一个好处在于,feature map的每个位置都具有单位长度。这个归一化策略与作者设计的Generator输出有较大关系,注意到Generator的输出层并没有Tanh或者Sigmoid激活函数,后面我们针对这个问题进行探讨。
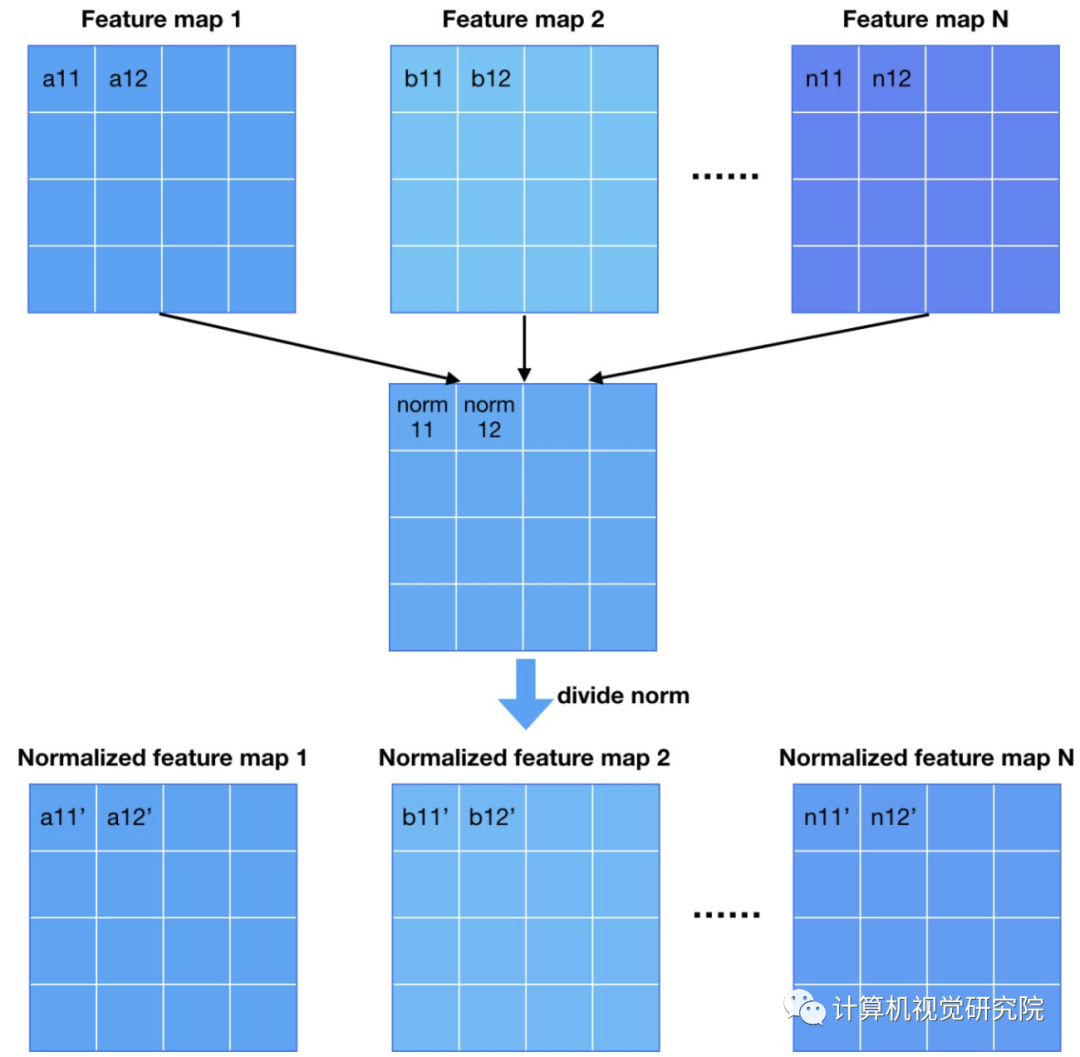
第二种normalization方法跟何老师的初始化方法挂钩。何老师的初始化方法能够确保网络初始化的时候,随机初始化的参数不会大幅度地改变输入信号的强度。

根据这个式子,我们可以推导出网络每一层的参数应该怎样初始化。可以参考pytorch提供的接口。作者走得比这个要远一点,他不只是初始化的时候对参数做了调整,而是动态调整。初始化采用标准高斯分布,但是每次迭代都会对weights按照上面的式子做归一化。作者argue这样的归一化的好处在于它不用再担心参数的scale问题,起到均衡学习率的作用(euqalized learning rate)。
实验结果



下一期,我们给大家讲讲Pytorch的复现,有兴趣的同学,请持续关注我们!

如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
扫码关注我们
公众号 : 计算机视觉战队
扫码回复:ProGAN,获取下载链接




