构建强化学习系统,你需要先了解这些背景知识
选自joshgreaves
机器之心编译
强化学习(RL)是关于序列决策的一种工具,它可以用来解决科学研究、工程文理等学科的一系列问题,它也是围棋程序 AlphaGo 的重要组成部分。本文旨在分享 85 页强化学习课本中最重要的内容,我们从最基础的马尔科夫决策过程开始一步步构建形式化的强化学习框架,然后再详细探讨贝尔曼方程以打好强化学习的基础。当然,如果你想更全面地了解这一主题,建议阅读 Richard Sutton 和 Andrew Barto 的著作《Reinforcement Learning: An Introduction》。
监督学习 vs 评估学习
对于很多感兴趣的问题,监督学习无法提供我们需要的灵活性。监督学习和强化学习之间的主要区别在于收到的反馈是评估性的还是指导性的。指导性反馈提示如何达到目标,而评估性反馈告诉你达到目标的程度。监督学习一般是基于指导性反馈来解决问题,而强化学习则基于评估性反馈解决问题。图像分类是一个带有指导性反馈的监督问题,当算法尝试分类特定数据时,它将从指导性反馈中了解到哪个是真正的类别。而评估性反馈仅仅告诉你目标的达成的程度,如果你使用评估性反馈训练分类器,那么你的分类器可能会说「我认为这是一只仓鼠」,然后它将得到 50 分。但是,由于没有任何语境信息,我们不知道这 50 分是什么。我们需要进行其他分类,探索这 50 分代表我们是正确还是错误的。或许 10000 是一个更好的分值,但是我们还是不知道它是什么,除非我们尝试对其他数据点进行分类。

强化学习说:猜到是仓鼠会收到两个金色星星和一个笑脸,而猜测是沙鼠,则会收到一个银色星星和一个大拇指。
在我们感兴趣的很多问题中,评估性反馈更加直观,易于使用。例如,想象一个控制数据中心温度的系统。指导性反馈似乎没有什么用处,那么你如何告诉算法给定时间步中每个组件的正确设置是什么呢?此时评估性反馈将发挥作用。你可以获取关于特定时间阶段使用的电量或平均温度,甚至过热机器的数量等反馈数据。这事实上就是谷歌使用强化学习解决该问题的方式。现在,让我们赶快来了解强化学习吧。
马尔科夫决策过程
假定我们知道状态 s,如果未来的状态条件独立于过去的状态,那么状态 s 符合马尔科夫属性。这意味着 s 描述了所有过去状态直至当前状态。如果这很难理解,通过实例会更好懂。想象一个在空中飞起的球,它的状态由位置和速度决定,并足以描述其当前和下一个时间步的位置(不考虑外界影响的物理模型)。因此,这一状态具备马尔科夫属性。但是,如果我们只知道球的位置而不知道其速度,它的状态则不是马尔科夫。当前状态并未收纳所有过去的状态,我们还需要过去时间步的状态信息才能构建球的恰当模型。
强化学习通常可以建模为一个马尔科夫决策过程,即 MDP,它是一个有向图,具有节点和边的状态,可以描述马尔科夫状态之前的转化。下面是一个简单实例:
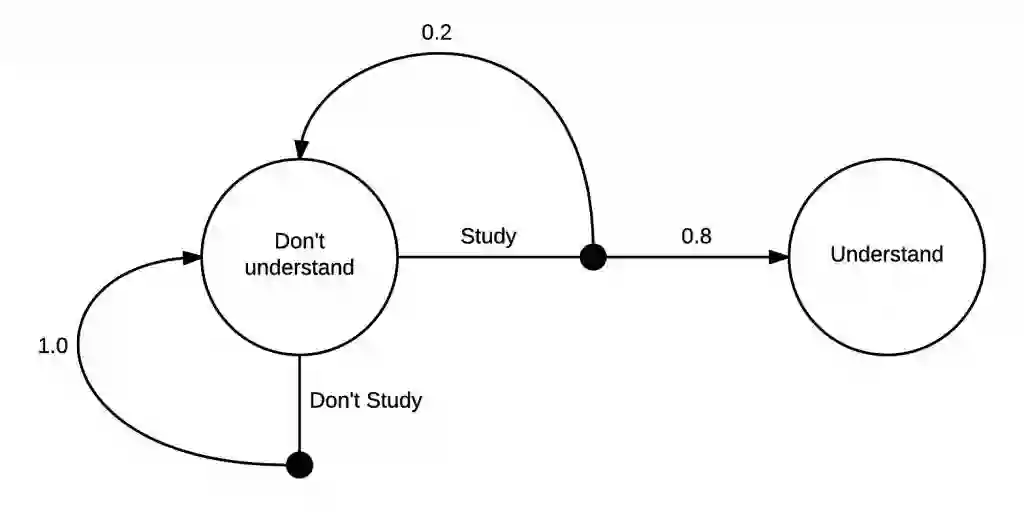
一个简单的马尔科夫决策过程。
这一 MDP 展示了「学习」的马尔科夫决策过程。首先你在一个「不理解」的状态中,接着你面临着两个可能的动作(action)——学习或者不学习。如果你选择不学习,则有 100% 的可能性返回到不理解的状态里。然而,如果你选择学习,则可能性降低为 20%,即你有 80% 的可能性进入理解状态。
实际上,我确定进入理解状态的可能性要高于 80%。MDP 的核心其实很简单,对于一个状态你可以采取一系列动作,而采取一个动作之后,会有一些关于你要转入状态的分布。正如在采取不学习动作的情况中,这一转化也可以很好地被确定。
强化学习的目标是学习如何采取动作,从而把更多时间花在更有价值的状态中。为了一个有价值的状态,我们需要更多的 MDP 信息。你无需一个 MDP 教你便懂得不吃东西就会饿死,但是强化学习智能体可不这样。
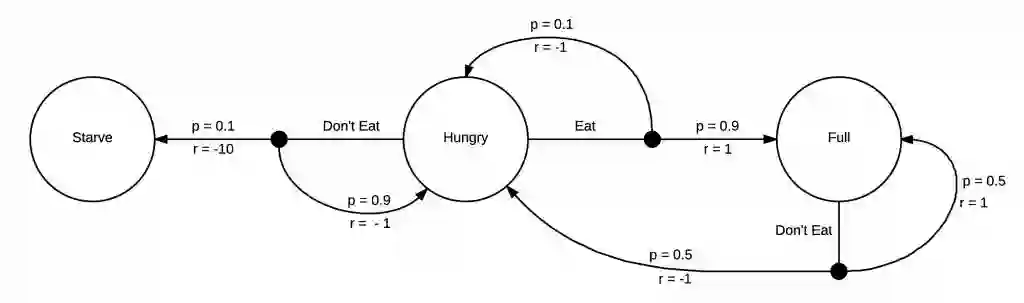
你不需要MDP来告诉自己饿了要吃饭,但是强化学习的智能体需要它。
这一 MDP 增加了奖励。每次转入一个状态,你会收到一个奖励。在这个实例中,由于挨饿你获得了一个负面奖励,由于饿死而获得了一个更大的负面奖励。如果你吃饱了,则获得一个正面奖励。现在我们的 MDP 已经彻底成型,可以开始思考如何采取动作以获取最大奖励。
由于这个 MDP 很简单,我们很容易看到获取高奖励的方式就是呆在高奖励区域,即饿了就吃。在这一模型中当我们吃饱了就没有太多其他选择,但我们会不可避免地再次饥饿,并立即选择吃东西。强化学习感兴趣的问题具有更大更复杂的马尔科夫决策过程,并且通常在我们实际探索之前,无法获得这种策略的任何信息。
形式化强化学习问题
现在我们已经有了很多所需的基本组成,下一步需要了解强化学习中使用的术语。最重要的组成是智能体(agent)和环境(environment)。智能体是被间接控制的,存在于环境中。通过回顾 MDP 可以看到,智能体可以在给定的状态下选择对它而言有显著影响的动作。然而,智能体并不能完全控制环境的动态。环境会接收这些动作,然后返回新的状态和奖励。
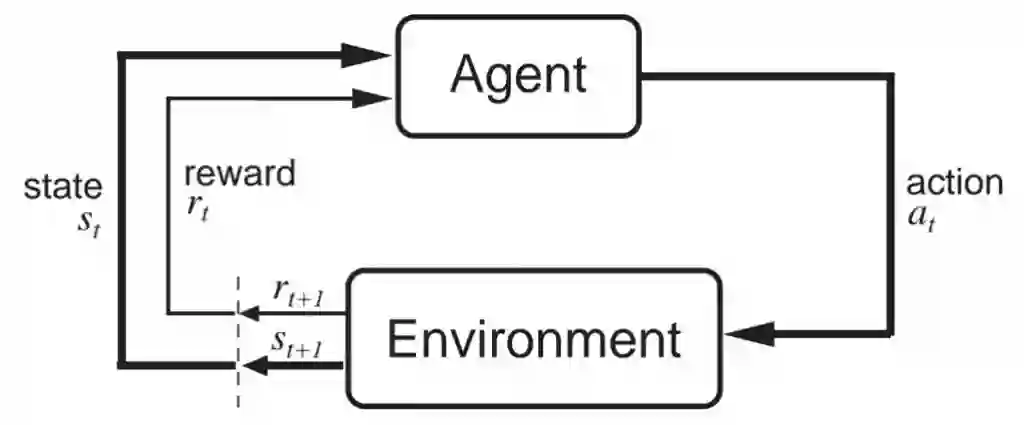
图片来自 Sutton 和 Barto 的《Reinforcement Learning: an Introduction》
这张图片很好地解释了智能体和环境之间的互动。在某个时间步 t,智能体处于状态 s_t,采取动作 a_t。然后环境返回一个新的状态 s_t+1 和一个奖励 r_t+1。奖励处于时间步 t+1 的原因是它是由环境在 t+1 的状态 s_t+1 中返回的,因此令它们保持一致更加合理(如图中所示)。
前半部分主要概述了强化学习的基本概念与组成部分,在上文中我们概述了强化学习问题的一般框架,并已经预备好学习如何最大化奖励函数以训练强化学习模型。在下一部分中,我们将进一步学习状态价值(state value)函数和动作价值(action value)函数,以及为解决强化学习问题奠定了算法基础的贝尔曼方程。此外,我们还将探索一些简单且高效的动态规划解决方案。当然,下一部分只是简要地概述贝尔曼方程。
理解强化学习:贝尔曼方程
对强化学习最重要的方程的逐步推导、解释,解开神秘面纱。
在前面内容中,我们学习了 MDP 和强化学习框架的主要部分。接下来,我们将在这个理论的基础上学习价值函数和贝尔曼方程。
奖励和回报(return)
正如之前所讨论的,强化学习智能体需要学习最大化累积未来奖励(cumulative future reward)。描述累积未来奖励的术语是回报,通常用 R 表示,并对特定时间步的回报加上一个下标 t。使用数学符号表示为:
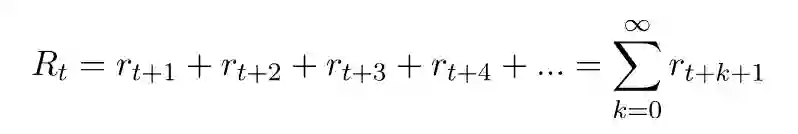
如果这个序列是无穷的,可能最终会得到无限大的回报,这对于问题的定义来说没有什么意义。因此,只有奖励的序列是有限的,该方程才是有意义的。总是有终点的任务被称为阵发性的(episodic),阵发性问题的一个不错的例子是卡片游戏。事件片段起始于给每个人发牌,并由于游戏的特定规则不可避免地会走向结束。然后,另一个片段将从发牌开始下一个回合。
相比使用未来累积奖励作为回报,更常使用的是未来累积折现奖励(future cumulative discounted reward):
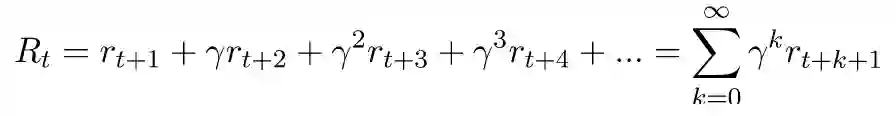
其中 0<γ<1。以这种方式定义回报有两个好处,一个是这种定义可用于无穷序列的回报,更早期的奖励有大得多的权重,这意味着比起更遥远的未来,我们更关心即将发生的奖励。选择的γ越小,这种倾向就越明显。从γ等于 0 和 1 的两个极端例子就能理解,如果γ等于 1,这个方程就变成了对所有的奖励都同样的关心,无论在什么时候。另一方面,当γ等于 0 的时候,这个方程就变成只关心即将发生的奖励,并对后面的所有奖励都不关心,这会使模型变得极端短视。它将会采取对当前回报最大的动作,而不会考虑该动作的任何未来影响。
策略
一个强化学习策略可以写为 π(s, a),它描述了一种动作的方式。策略函数的输入为状态(state)和动作(action),并返回在输入状态的情况下采取输入动作的概率。因此,对于一个给定的状态,该状态下所有动作 a 的策略函数值之和一定为 1。在下面的案例中,如果我们的状态是「hungry」,那么可采取的两种动作「Eat」或「Dont Eat」,并且当前状态下这两个动作的策略函数和为 1。
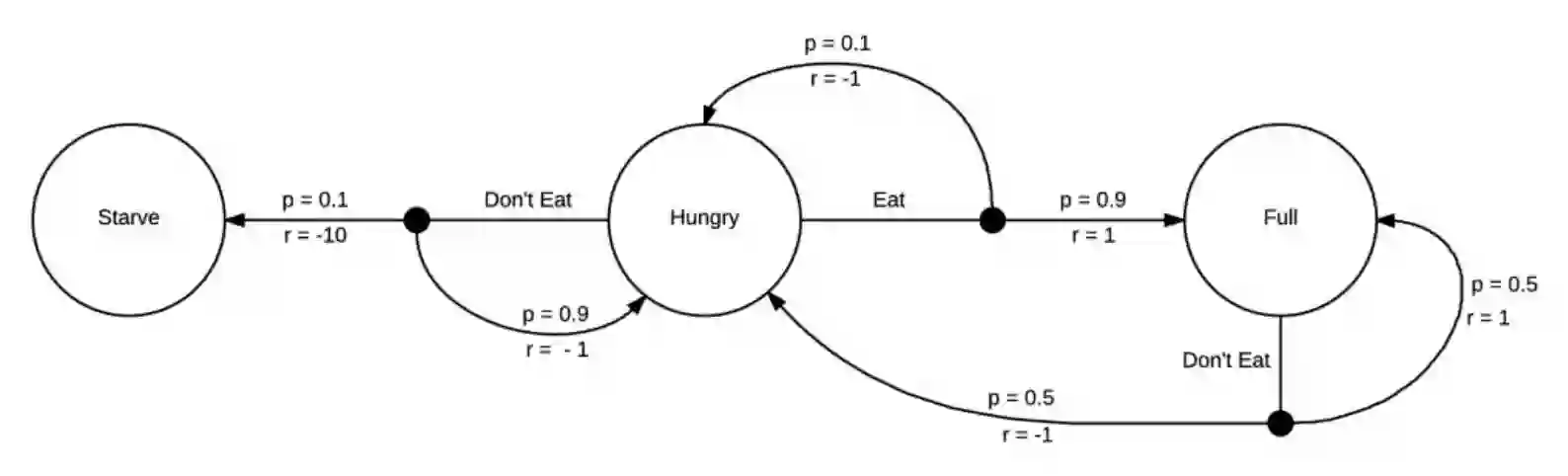
我们的策略函数应该要描述每一个状态下动作的选择方案。所以一个等概率的随机策略将简单地将动作「Eat」或「Dont Eat」的概率设为相等,即π(hungry, E)=0.5、π(hungry, E bar)=0.5、π(full, E bar)=1,其中 E 为动作「Eat」,E bar 为动作「Dont Eat」。这也就说明在「hungry」状态下选择动作「Eat」或「Dont Eat」的概率相等。
我们在强化学习中的目标是学习一个最优的策略 π*,它将告诉我们如何选择一个动作以获得最大的回报。上图是非常简单的案例,我们很容易看出来最优策略就是在 hungry 状态下选择动作 Eat,即π*(hungry, E) = 1.0。在该案例中最优的策略是确定性的,即每一个状态都有最优的一个动作。这种确定性情况可以写为π*(s) = a,它代表着策略函数即将状态映射到具体动作的一个函数。
价值函数
为了学习最优策略,我们使用了价值函数。强化学习中有两种价值函数:状态价值函数 V(s) 和动作价值函数 Q(s, a)。
状态价值函数在遵循一个策略时描述状态的值。根据策略π,状态价值函数的期望回报是:

注意:即使是在同样的环境中,价值函数也会根据策略的不同而发生变化。原因在于状态的值取决于动作,在特定状态下采取的动作会影响期望奖励的值。还要注意期望的重要性。(期望即加权平均值;字面意义上即你期望看到的回报。)我们使用期望的原因之一是到达一个状态后发生的事情存在一定的随机性。你可能有一个随机策略,这意味着我们需要结合所有不同动作的结果。此外,转移函数(transition function)也可能是随机的,这意味着我们最终的状态可能不是 100% 的概率。记住上面的例子:当你选择一个动作时,环境将回报下一个状态。它可能回报多个状态,即使在给定一个动作的前提下。我们将更多地把它当作贝尔曼方程。期望会考虑所有随机性。
我们使用的另一个价值函数是动作价值函数。该函数告诉我们使用特定策略时某个状态中采取一个动作的值。在策略 π中,给定状态和动作情况下,期望回报为:

状态价值函数的注意事项同样适用于动作价值函数。期望根据策略考虑未来动作的随机性,以及环境回报状态的随机性。
贝尔曼方程
Richard Bellman 是一位美国应用数学家,他推导出了以下方程,使得我们能够开始解决马尔科夫决策过程(MDP)。贝尔曼方程在强化学习中非常普遍,也是理解强化学习算法工作原理所必须了解的。但是在我们学习贝尔曼方程之前,需要一些有用的符号。这些符号定义如下:
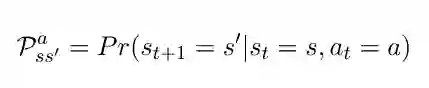
p 是转移概率(transition probability)。如果我们在状态 s 处开始,并实施动作 a,则会得到状态 s'和概率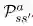
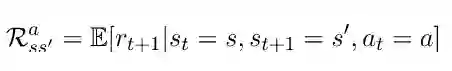
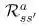
最后,了解了这些,我们就可以推导出贝尔曼方程了。我们认为贝尔曼方程是一个状态价值函数。使用回报的概念,我们将重写方程(1):
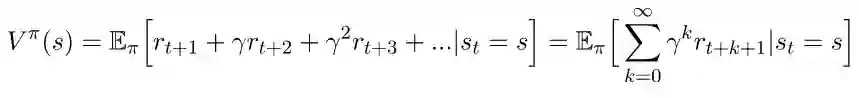
如果我们将第一个奖励从和中拆分出来,我们可以将方程重写为:
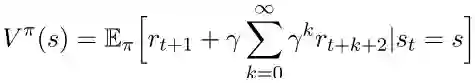
这里的期望解释了如果我们继续维持状态 s、策略π,回报将如何发展。期望可以通过总结所有可能的动作与返回状态来明确写出。接下来的两个方程可以帮助我们完成下一步。
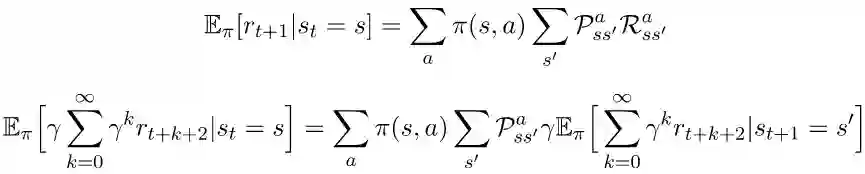
通过结合上面两个期望的计算公式,我们可以将状态价值函数写为如下形式:
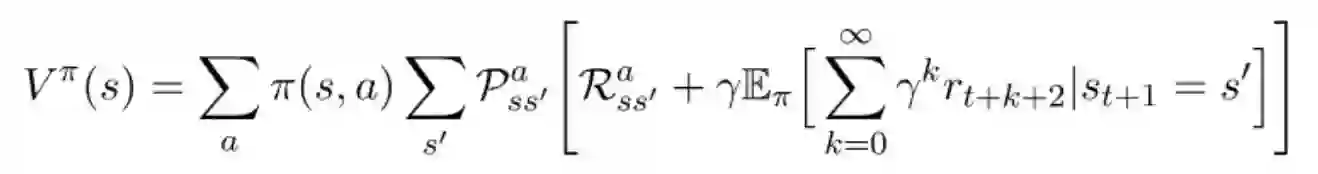
现在请注意,方程(1)与这个方程的末尾形式相同。我们可以替换它,得到:
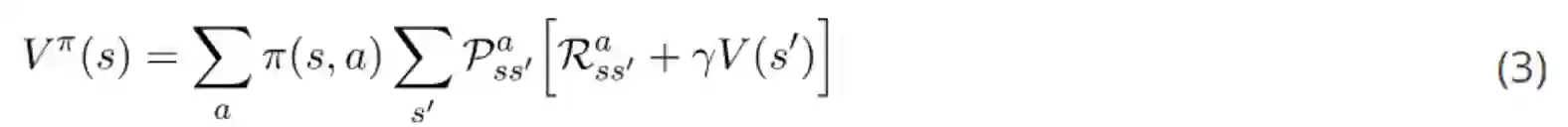
动作价值函数的贝尔曼方程可以用同样的方式进行推导。本文结尾有具体过程,其结果如下:
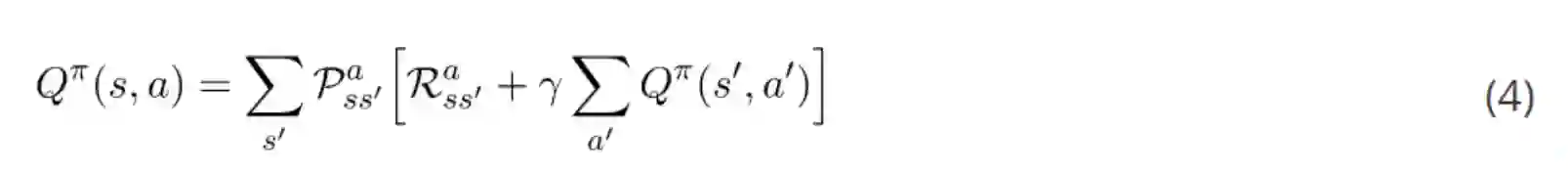
贝尔曼方程的重要性在于它可以让我们借助其他状态的值表达某个状态的值。这意味着如果我们知道 s_t+1 的值,我们就可以很轻松地算出 s_t 的值。这为迭代计算每个状态的值创造了很多机会,如果我们知道下一个状态的值,我们就可以知道当前状态的值。最重要的是我们需要记住一些编号方程。最后,有了贝尔曼方程,我们就可以开始了解如何计算最优策略,构建我们的第一个强化学习智能体了。
下一步:动态规划
在随后的文章中,我们还将讨论使用动态规划计算最优策略,它也是高级算法的基础。同时,这也是我们第一次编写强化学习算法的机会。我们还将探究策略迭代与价值迭代的优势与劣势。
动作价值函数的贝尔曼方程:与推导状态价值函数的贝尔曼方程过程相同,我们得到了一系列方程,从方程(2)开始:
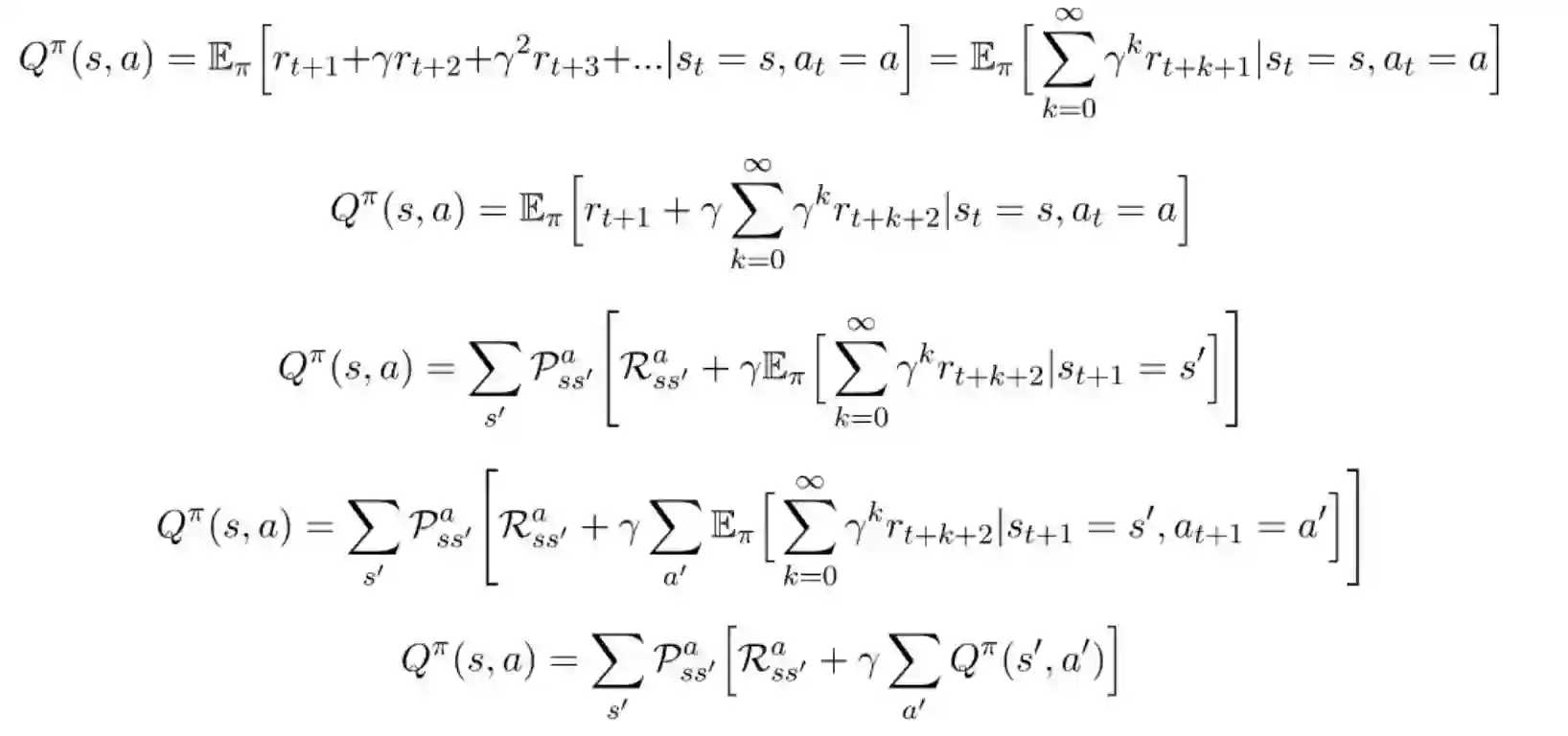
延伸阅读

点击【阅读原文】报名参赛,美国赛区报名请点击大赛首页 US 进入美国赛区报名通道



