为语言障碍人士重现自然语音


发布人:Google Research 软件工程师 Ye Jia 和产品经理 Julie Cattiau
2021 年 6 月 2 日,美国职业棒球大联盟举行了贾里格日纪念活动,纪念卢·贾里格 (Lou Gehrig) 在 1925 年 6 月 2 日成为洋基队先发一垒手,同时悼念他在 1941 年 6 月 2 日因患肌萎缩性脊髓侧索硬化症 (Amyotrophic lateral sclerosis, ALS,又称卢·贾里格症) 去世,享年 37 岁。ALS 是一种影响运动神经元的进行性神经退行性疾病,而运动神经元又将全身的肌肉与大脑相连,负责控制肌肉和自主运动。当骨骼肌的控制受到影响时,人们可能会失去说话、进食、行动甚至呼吸的能力。
为纪念卢·贾里格,在 6 月 2 日的活动中,因 ALS 而失去说话能力的前 NFL (National Football League) 球员,同时也是 ALS 疾病教育倡导者的史蒂夫·格里森 (Steve Gleason),使用由机器学习 (ML) 模型重新生成的语音,诵读了贾里格著名的演讲稿“Luckiest Man(天选之子)”。格里森与 Google Project Euphonia 项目合作,实现了自己声音的重现,该项目旨在帮助那些因 ALS 丧失语言能力的人能够用自己的声音更好的交流。
Google Project Euphonia
https://sites.research.google/euphonia/about
今天我们将介绍 PnG NAT,即 Project Euphonia 项目在重现史蒂夫·格里森的语音时采用的模型。PnG NAT 是一种全新的文本语音转换合成 (Speech synthesis) (TTS) 模型,它将两种最先进的技术 PnG BERT 和 Non-Attentive Tacotron (NAT) 合并为一个模型。与之前的技术相比,该模型在质量和流畅性方面有显著提升,这一方法十分有潜力,可以扩展至更多用户。
PnG BERT
https://arxiv.google.cn/abs/2103.15060
Non-Attentive Tacotron
https://arxiv.google.cn/abs/2010.04301

Non-Attentive Tacotron (NAT) 是 Tacotron 2 的下一代模型,其中 Tacotron 2 是于 2017 年提出的序列到序列的神经 TTS 模型。Tacotron 2 使用关注模块来连接输入的文本序列和输出的语音频谱帧序列,如此一来,模型就可以了解,在生成合成语音频谱的每个时步需要关注文本的哪一部分。Tacotron 2 是第一个能够让合成的语音听起来像是真人讲话声音的 TTS 模型。然而,我们通过大量的实验发现,由于关注机制固有的灵活性,该模型会有很小的概率出现如胡言乱语、重复或跳过部分文字等稳健性问题。
Tacotron 2
https://ai.googleblog.com/2017/12/tacotron-2-generating-human-like-speech.html
NAT 在 Tacotron 2 的基础上进行了改进,用一个基于持续时间的上采样器代替关注模块,该上采样器预测每个输入音素 (Phoneme) 的时长,并对编码的音素表征进行上采样,令输出的长度与预测的语谱图长度相对应。这一改变既解决了稳健性问题,又提高了合成语音的自然度。这种方法还能精确控制输入文本中每个音素的语音时长,同时仍能保持高度自然的合成质量。由于 ALS 患者的录音中经常出现不流畅的语句,这种对每个音素进行控制的能力是保证重现语音流畅性的关键。
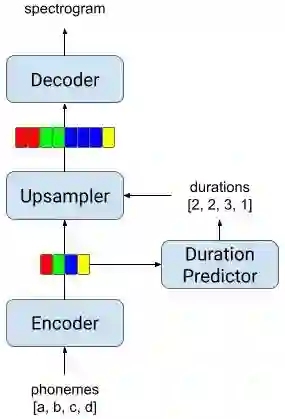
Non-Attentive Tacotron (NAT) 模型
虽然 NAT 解决了稳健性问题,并在神经 TTS 中实现了精确的时长控制,但我们在此基础上进行构建,进一步改善对 TTS 输入的自然语言理解。为此,我们应用了 PnG BERT,它采用了类似于 BERT 的方法,但其本身专为 TTS 而设计。PnG BERT 基于大型文本语料库中相同内容的音素表征和字位表征,接受了自我监督预训练,然后用作 TTS 模型的编码器。这将显著改善合成语音的韵律 (Prosody) 和发音,尤其是在合成较为困难的情况下。
以下面的音频为例,它们由只接受音素作为输入内容的常规 NAT 模型合成:
两个模型输入的文本为“To cancel the payment, press one; or to continue, two(要取消付款,请按一;若要继续,请按二)”。请注意两个句子中最后一个词“two(二)”之前不同的停顿时长。“two(二)”在常规 NAT 模型输出的版本中可能会与“too(也)”混淆。因为“too(也)”和“two(二)”的发音完全一样(因此音素表征相同),常规 NAT 模型无法理解这两个词哪个更恰当,并判断此处为更频繁在逗号后使用的“too(也)”。相比之下,PnG NAT 模型能够更轻松地区分其中的差异,因为除了音素之外,它还会将字位作为输入内容,从而做出更合适的停顿。
PnG NAT 模型将预训练的 PnG BERT 模型作为编码器集成到 NAT 模型中。NAT 使用编码器输出的隐藏表征来预测每个音素的时长,然后对其进行上采样以匹配语谱图的长度(如上所述)。在最后一步中,Non-Attentive 解码器将上采样的隐藏表征转换为音频语音频谱图,最后经过神经声码器转换为音频波形。
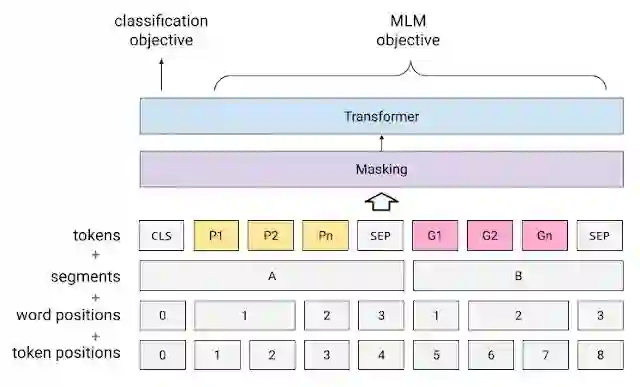
PnG BERT 和预训练目标。黄框代表音素,粉框代表字位
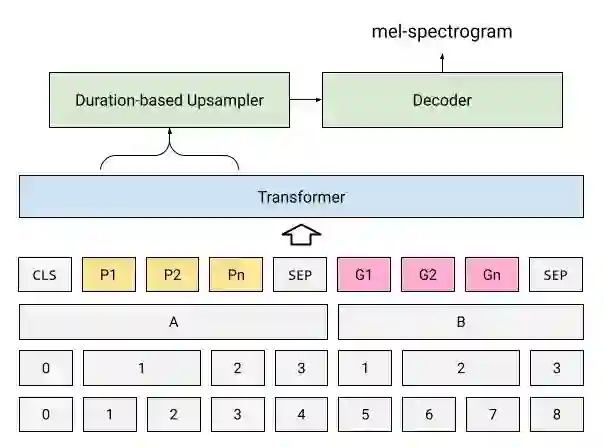
PnG NAT:PnG BERT 取代了 NAT 模型中的原始编码器。移除了遮蔽语言模型 (MLM) 预训练的随机遮蔽
为重现史蒂夫·格里森的声音,我们首先用 31 个专业演讲者的录音训练了一个 PnG NAT 模型,然后用该模型对格里森长达 30 分钟的录音进行了微调。由于格里森的录音是在他被诊断出患有 ALS 后录制的,所以其中会出现口齿不清的片段。微调后的模型能够合成与录音极为相似的语音。然而,由于格里森在说话时已经出现了 ALS 症状,合成语音呈现出部分类似的不流畅问题。
为改善这一现象,我们利用了 NAT 的音素时长控制以及通过专业演讲者训练的模型。我们首先预测了专业演讲者和格里森的各音素时长,然后用两者各音素时长的几何平均值来指导 NAT 的输出内容。最终,该模型能够用格里森的声音生成语音,而且比原始录音中的语音更加流畅。
除了为 ALS 患者重现语音外,PnG NAT 还通过 Google Cloud Custom Voice 为各种客户提供声音服务。
Google Cloud Custom Voice
https://cloud.google.com/text-to-speech/custom-voice/docs
世界上有数百万人患有可能会影响其语言能力的神经系统疾病,例如 ALS、大脑性麻痹 (Cerebral palsy) 或唐氏综合症 (Down syndrome),其中很多人难以表述自己的真实想法,面对面交流对他们而言可以说是个不小的挑战。使用语音激活技术可能也难以实现令人满意的效果,因为该技术无法持续可靠地发挥作用。Project Euphonia 是一个 Google Research 项目,旨在帮助语言障碍人士更加清楚地表达自己的想法。该团队正在研究为语言障碍人士提高语音识别能力的方法(参见最近的文章和今日秀中的部分内容),以及自定义文字转语音技术(观看由前 NFL 球员蒂姆·肖主演的纪录片 AI 时代)。
最近的文章
https://blog.google/outreach-initiatives/accessibility/project-euphonia-1000-hours-speech-recordings/
今日秀中的部分内容
https://www.today.com/video/new-google-technology-is-helping-people-with-als-record-their-voices-78999109798
AI 时代
https://www.youtube.com/watch?v=V5aZjsWM2wo
Google Research、Google Cloud、消费者应用及 Google 无障碍中心团队中的许多成员都对此项目和活动做出了贡献,包括 Michael Brenner、Bob MacDonald、Heiga Zen、Yu Zhang、Jonathan Shen、Isaac Elias、Yonghui Wu、Anne Keck、Danielle Notaro、Kevin Hogan、Zack Kaplan、KR Liu、Kyndra Price、Zoe Ortiz。

推荐阅读



点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看




