基于机器学习的WEB攻击分类检测模型
机器学习目前已有很多创新应用,例如攻防对抗、UEBA以及金融反欺诈等。基于机器学习的新一代WEB攻击检测技术有望弥补传统规则集方法的不足,为WEB对抗的防守端带来新的发展和突破。
本文是作者近十年安全领域工作总结出的人工智能实战初探,首先采用聚类模型,将正常数据和已知攻击类型的数据形成样本簇,过滤掉异常数据之后送入分类模型对数据进行分类,从而发现新型WEB攻击行为。
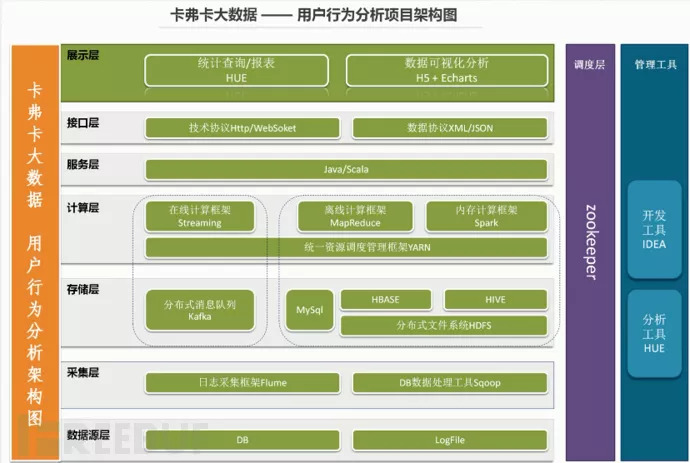
系统架构图设计
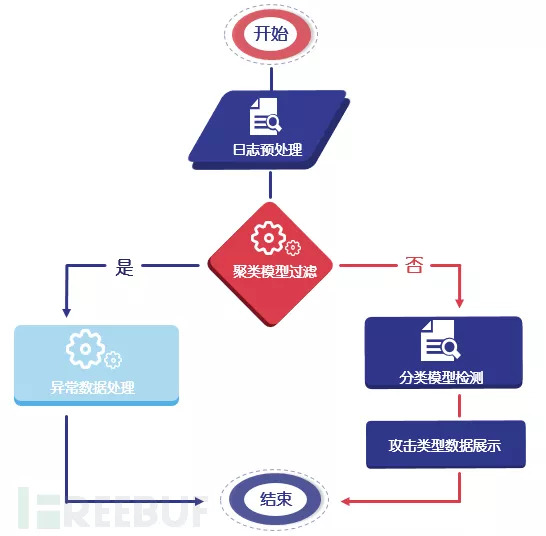
分类检测流程图
一、日志预处理
目前常见的网络安全攻击类型主要包括:
| 编号 | 攻击类型 |
|---|---|
| 0 | 正常 |
| 1 | SQL 注入 |
| 2 | 缺失报头 |
| 3 | 爬虫 |
| 4 | 跨站脚本攻击 |
| 5 | 漏洞防护 |
| 6 | 扫描工具 |
| 7 | 协议违规 |
| 8 | 针对ie8的跨站攻击 |
本文主要针对最常见的SQL注入攻击和跨站脚本攻击进行介绍。
1.SQL 注入:
SQL 注入其实就是攻击者通过操作输入修改后台数据库的语句,执行代码从而达到攻击的目的。URL地址中的参数经常与数据库SQL语句中各参数相关联,攻击者通过构造参数很容易会引起SQL注入的问题,所以攻击者通常会在参数中注入数据库专用语言和关键字。
2.XSS 攻击:
即跨站脚本攻击,曾被OWASP评为Web攻击中最危险的攻击,XSS攻击可分为存储型XSS和反射型XSS,其构造方法是在URL地址的请求参数中加入脚本代码,本质上是一种针对HTML的注入攻击。
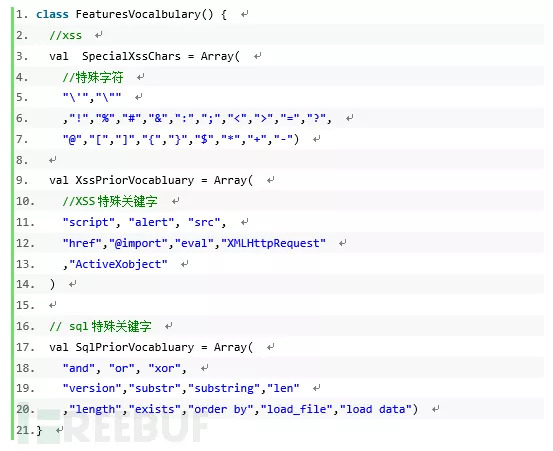
基于机器学习的WEB攻击分类检测模型主要对URL进行分析:包括数字处理、字母处理、字符处理及文本结构分析,SQL注入和XSS攻击具有关键词、数字占比较高等显著特征,通过文本分析进行统计处理,将明显的特征点提取出来作为后续分类的特征向量。
二、聚类模型构建:
监督学习都需要一个训练阶段,牵涉到缺陷学习阶段的引入,使得基于监督学习的WEB攻击检测模型设计变得较为复杂。首先需要为模型的学习准备训练样本集,并对训练样本分类打标记,这些都需要大量的人工参与。监督学习方法的检测性能对训练的好坏具有很大的依赖性,训练样本集的完备性和训练样本标记的正确性都会影响方法在检测阶段的性能表现。
通过对日志和流量数据进行分析发现以下特征:
1) 90% 以上都是正常的访问请求,恶意的攻击行为占总请求量很小一部分;
2) 正常访问的参数形式之间变化很小,具有很好的聚类特性;
3) 恶意攻击与正常样本模式之间有较大的差异,聚类特性较差。
通常正常流量是大量重复性存在的,而入侵行为则极为稀少。因此我们选取K-means构造能够充分表达白样本的最小模型作为Profile,实现异常检测。
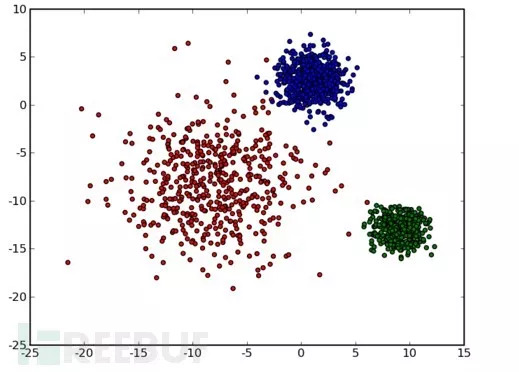
我们通过训练大量正常样本以及已知的攻击类型样本,过滤掉未知的攻击行为,为我们后续分类器的准确度提供了保证。
以下代码实现了如何使用聚类算法形成样本簇,判断是否异常,过滤掉异常数据并将数据送入分类器模型。
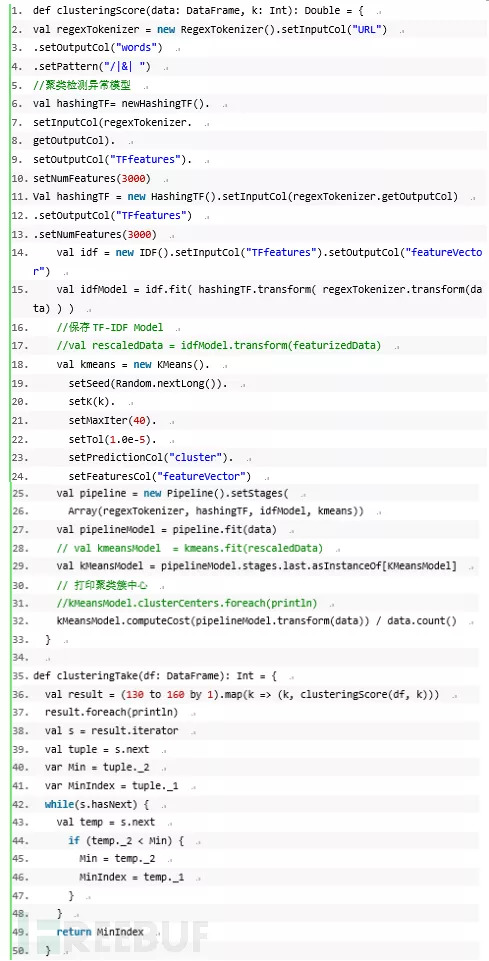
三、分类检测模型构建
以上介绍了如何利用聚类算法对异常攻击行为进行过滤,为下一步构造多分类检测模型打好基础,目前主流分类器包括SVM、随机森林、xgboost等算法,本文选择随机森林算法,后续也会增加xgboost的实现。
随机森林算法把分类树组合成随机森林,即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。随机森林在运算量没有显著提高的前提下提高了预测精度。随机森林对多元共线性不敏感,结果对缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用。
随机森林的主要优点有:
1) 训练可以高度并行化,对于大数据时代的大样本训练速度有优势;
2) 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型;
3) 在训练后,可以给出各个特征对于输出的重要性;
4) 由于采用了随机采样,训练出的模型的方差小,泛化能力强;
5) 相对于Boosting系列的Adaboost和GBDT,随机森林实现比较简单;
6) 对部分特征缺失不敏感;
7) 对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化;
8) 在创建随机森林的时候,对generlization error使用的是无偏估计;
9) 训练过程中,能够检测到feature间的互相影响。
随机森林也有一些缺点,包括:
1) 在某些噪音比较大的样本集上,随机森林模型容易陷入过拟合;
2) 取值划分比较多的特征容易对随机森林的决策产生更大的影响,从而影响拟合的模型的效果。
将已知WEB攻击和正常访问文本抽象成多个特征向量,再将特征向量输送到随机森林中,对其进行分类得出分类模型,最后对新的访问文本进行模式识别,发现新型WEB攻击行为。整个分类检测模型由 3 个组件组成:
1)文本分析 :
包括数字处理、字母处理、字符处理及文本结构分析,针对WEB攻击类型中的每种工具,如SQL注入,典型 SQL 注入具有包含SQL关键词、数字占比较高等显著特征,文本分析主要进行一些统计上的处理,将一些明显的特征点提取出来作为分类的特征向量。
2)特征提取 :
包括特征词及权重、关键词和特定信息,特征提取主要是将WEB攻击类型中的每种攻击,如SQL注入的关键词作为空间向量模型的关键词,采用分词的方法将字符串的词语剥离出来,再统计词频,映射到空间向量中。
3)分类 :
包括随机森林算法、模型训练、分类器和分类结果,分类主要是选取impurity, maxDepth, maxBins, numTrees的一些参数,经过训练产生分类器,得出分类结果。
3.1 文本分析
文本分析对样本进行数据统计并将样本映射为空间向量。统计项主要有:典型 SQL注入关键词是否存在、样本文本中数字字符百分比、大写字符百分比、截断字符百分比、特殊字符百分比等。应用空间向量模型对文本样本进行映射可以得出此文本空间的特征向量值。
3.2 基本特征的提取
| 级别 | SQl 恶意关键字 |
|---|---|
| High | and,or,xp,substr,utl,benchmark,shutdown,@@version,mformation_schema,hex( |
| Middle | Select,if(,union,group,by,—,count(,/**/,char(,drop,delete,concat,orderby,case when,assic(,exec(,length |
| Low | and,or,like,from,insert, update,create,else, exist,table ,database,Where,sleep,mid,updatexml(,null,sqlmap,md5(,floorm,rand,cast,dual,fetch,print,declare,cursor,extractvalue(,upperjoin,exec,innier,convert,distinct |
| 级别 | Xss 恶意关键字 |
|---|---|
| High | <scrip, </script, <iframe, </iframe,response,write(,eval(,prompt(,alert(,javascript;,document,cookie |
| Middle | Onclick=,onerror=,,<base,< base="">>,location,hash,window,name,<form,</form</base,<> |
| Low | echo,print,href=,sleep |
样本数据中如果存在SQL注入常用关键词则特征值为1,如果不存在则特征值为0。但是通常访问文本是一串字符串,而且字符串的内容因网站设计的不同差异性很大,因此首先要对访问文本进行分词处理。因为URL字符串只能是 ASCII 码,而且不同的应用对数据进行了不同的封装和显示处理,如果根据其他的规则分词,准确率就会大大降低。所以本文只采用 3 种字符进行分词:“空格”、“/”和“&” 。
SQL 注入和XSS攻击的基本类型和变形的内容可以通过统计的方法对访问字符串进行词频统计,统计内容包括:
1)大写字符在字符串中所占的比例,根据 SQL 注入中的变形攻击将查询语句中部分字符的大小写进行转化,来避开过滤器的检测;
2)空格字符在字符串中所占的比例,主要针对空字符攻击;
3)特殊字符在字符串中所占的比例,主要是闭合截断字符,常见的闭合截断字符有: “{}”“[]”“=”“? ”“#”“/” “ style=”font-size: 16pt; color: black;”>< ” “ > style=”font-size: 16pt; color: black;”>” “ ! ”# % & ’ : ; < > = ? @ [ ] \/ {} $ , * + - ”等。主要针对内联注释序列和截断字符变形攻击;
4)数字字符在字符串中所占的比例,主要针对动态查询变形攻击。
| 类别 | 序号 | 特征名称 | 特征描述 |
|---|---|---|---|
| 语法特征 | 1 | URL_len | URL 长度 |
| 2 | Path_len | 路径长度 | |
| 3 | Path | 路径最大长度 | |
| 4 | Path_Maxlen | 路径平均长度 | |
| 5 | Argument_len | 参数部分长度 | |
| 6 | Name_Max_len | 参数名最大长度 | |
| 7 | Name_Avglen | 参数名平均长度 | |
| 8 | Value_Max_len | 参数值最大长度 | |
| 9 | Value_Avg_len | 参数值平均长度 | |
| 10 | Argument_len | 参数个数 | |
| 11 | String_Max_len | 字符串最大长度 | |
| 12 | Number_Maxlen | 连续数字最大长度 | |
| 13 | Path_number | 路径中的数字个数 | |
| 14 | Unknow_len | 特殊字符的个数 | |
| 15 | Number_Percentage | 参数值中数字占有比例 | |
| 16 | String_Percentage | 参数值字母占有比例 | |
| 17 | Unkown_Percentage | 参数值中特殊字符的比例 | |
| 18 | BigString_Percentage | 大写字符所占比例 | |
| 19 | Spacing_Precentage | 空格字符所占比例 | |
| 领域特征 | 19 | ContainIP | 参数值是否包含IP |
| 20 | Sql_Risk_level | SQL 类型危险等级 | |
| 21 | Xss_Risk_level | Xss 类型危险等级 | |
| 22 | Others_Risk_level | 其他类型危险等级 |
初始提取的特征如表
3.3 词袋模型
机器学习算法的实现首先是要构造好的特征向量,在类似的分类算法中比较好的是首先通过N-Gram将文本数据(URL)向量化,比如对于下面的例子,如果N取2,步长为1,则:
style="color: black;">www.xxx.com.cn/api/user/getMessagehttp去掉主机名得到:
api/user/getMessagehttp用’ / ’分词 得到:
api,user, getMessagehttp[api user 和user getMessagehttp]然后计算TF-IDF,词频—逆文档频率(简称TF-IDF)是一种用来从文本文档(例如URL)中生成特征向量的简单方法。它为文档中的每个词计算两个统计值:一个是词频(TF),也就是每个词在文档中出现的次数,另一个是逆文档频率(IDF),用来衡量一个词在整个文档语料库中出现的(逆)频繁程度。这些值的积,也就是TF×IDF,展示了一个词与特定文档的相关程度(比如这个词在某文档中很常见,但在整个语料库中却很少见)。
N-Gram 的分词方法乍一看好像没什么道理,因为一般的特征向量的构造是提取的特征关键词。比如如果我们将向量定义为script、select、union、eval等词出现的词频,那就很好理解,因为那些词都是恶意关键词,在正则匹配中一般也会拦截。但其实N-Gram也是一样的效果,一个特定的关键词会被切分成特定的序列,比如select被分成[sel,ele,lec,ect],而其他的正常的词一般不会出现这样的序列。其中N的取值需要进行多次试验,不同的算法最佳值不同。
特征提取主要是将SQL注入的关键词作为空间向量模型的关键词,采用分词的方法将字符串的词语剥离出来,再统计词频,映射到空间向量中,
SQL 注入的主要载体为访问的URL字符串,将这段字符串看成是一个文本,首先进行分词,分词之后就可以构建 URL字符串所对应的空间向量,空间向量中的每个特征即是所存在的SQL注入特征关键词,词频可以用来统计,而权重则取决于逆文档率。
最终特征:
【分词生成特征向量 + 统计特征 + 基本特征(敏感关键词个数) 】
目前存在的问题是利用TF-IDF产生的特征向量极度依赖训练集,当测试机中某一关键字未出现,则TF-IDF产生的特征向量也将不包含,而提取的统计特征现在只针对SQL注入及XSS攻击有领域特征,对于其他攻击类型的特征提取直接决定了WEB攻击检测精度。
四、分类检测模型训练
4.1 分类检测模型实现
随机森林是一个包含多个决策树的分类器,其输出的类别是由个别树输出的类别的众数而定。决策树算法家族能自然地处理类别型和数值型特征。决策树算法容易并行化,它们对数据中的离群点(outlier)具有鲁棒性(robust),这意味着一些极端或可能错误的数据点根本不会对预测产生影响。算法可以接受不同类型和量纲的数据,对数据类型和尺度不相同的情况不需要做预处理或规范化。
在决策树的每层,算法并不会考虑所有可能的决策规则。如果在每层上都要考虑所有可能的决策规则,算法的运行时间将无法想象。对一个有 N 个取值的类别型特征,总共有 2N – 2 style=”font-size: 16pt; color: black;”>个可能的决策规则(除空集和全集以外的所有子集)。即使对于一个一般大的 N,这也将创建数十亿候选决策规则。
相反,决策树使用一些启发式策略,能够聪明地找到需要实际考虑的少数规则。在选择规则的过程中也涉及一些随机性;每次只考虑随机选择少数特征,而且只考虑训练数据中一个随机子集。在牺牲一些准确度的同时换回了速度的大幅提升,但也意味着每次决策树算法构造的树都不相同。

4.2 交叉验证与评价指标
本文对WEB攻击分类检测模型评估指标选用的是精确率(Precision)、召回率(Recall)和F1值(F-Measure),在二分类问题中,一个样本的检测结果通常会出现四种情况:
1.TP:(TruePositive)正样本被模型预测为正,称作判断为真的正确率;
2.TN:(TrueNegative):负样本被模型预测为负,称作判断为假的正确率;
3.FP:(FalsePositive):负样本被模型预测为正,称作误报率;
4.FN:(FasleNegative):正样本被模型预测为负,称作漏报率。
评估指标用上述名词表示如下:
Precision(精确率)=TP/(TP+FP) Recall(召回率)=TP/(TP+FN)F_Measure 则是Precision与Recall的加权平均。
当精确率和召回率同时都高的时候,F1值才会高,因此F1值能够全面的评估URL分类模型的性能,即在满足高准确率的情况下也要保证高召回率。多类分类评估指标和二分类评估指标计算方式有所不同,多分类时把每个类别分别看做正样本,所有其它样本视为负样本,分别计算各个类别的精确率、召回率和F1值,然后再对所有类的指标求算术平均值作为多分类模型的最后评估结果。
攻击类型编号:
| 编号 | 攻击类型 |
|---|---|
| 0 | 正常 |
| 1 | SQL 注入 |
| 2 | 缺失报头 |
| 3 | 爬虫 |
| 4 | 跨站脚本攻击 |
| 5 | 漏洞防护 |
| 6 | 扫描工具 |
| 7 | 协议违规 |
| 8 | 针对ie8的跨站攻击 |
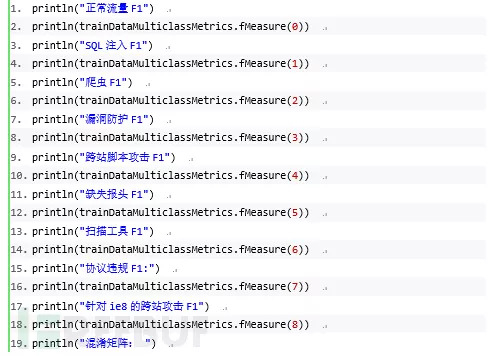
训练集
正常流量F1
0.9391002297047453
SQL 注入F1
0.9567709186179794
爬虫F1
0.7716240805761294
漏洞防护F1
0.9021054675580459
跨站脚本攻击F1
0.7221889055472264
缺失报头F1
0.9634720123185718
扫描工具F1
0.5475933908045977
协议违规F1
0.6563775510204082
针对ie8的跨站攻击F1
0.6810157194679565
混淆矩阵:
| 编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 16762 | 0 | 60 | 222 | 196 | 23 | 89 | 586 | 15 |
| 1 | 127 | 11686 | 92 | 5 | 95 | 3 | 1 | 97 | 0 |
| 2 | 48 | 0 | 15054 | 614 | 119 | 101 | 838 | 1129 | 39 |
| 3 | 395 | 53 | 712 | 16260 | 166 | 7 | 250 | 111 | 23 |
| 4 | 99 | 188 | 309 | 98 | 14451 | 9 | 931 | 1257 | 642 |
| 5 | 12 | 0 | 660 | 187 | 31 | 16894 | 74 | 80 | 5 |
| 6 | 84 | 52 | 3418 | 258 | 485 | 46 | 9147 | 4179 | 364 |
| 7 | 152 | 245 | 502 | 226 | 677 | 30 | 3282 | 12865 | 28 |
| 8 | 66 | 98 | 270 | 202 | 5816 | 13 | 763 | 889 | 9856 |
测试集
正常流量F1
0.9318407960199004
SQL 注入F1
0.9606017191977076
爬虫F1
0.7713125845737483
漏洞防护F1
0.8954344624447718
跨站脚本攻击F1
0.6946902654867257
缺失报头F1
0.9616342800199303
扫描工具F1
0.5380181169365907
协议违规F1
0.6589411497386958
针对ie8的跨站攻击F1
0.6376456161863887
混淆矩阵:
| 编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1873 | 0 | 7 | 32 | 30 | 2 | 23 | 75 | 5 |
| 1 | 14 | 1341 | 9 | 0 | 15 | 1 | 0 | 12 | 0 |
| 2 | 4 | 0 | 1710 | 76 | 21 | 7 | 92 | 139 | 9 |
| 3 | 45 | 3 | 87 | 1824 | 18 | 0 | 32 | 13 | 1 |
| 4 | 10 | 20 | 26 | 10 | 1570 | 3 | 103 | 148 | 126 |
| 5 | 0 | 0 | 76 | 29 | 5 | 1930 | 8 | 8 | 1 |
| 6 | 9 | 7 | 381 | 29 | 60 | 7 | 980 | 448 | 46 |
| 7 | 10 | 24 | 51 | 22 | 86 | 2 | 341 | 1450 | 7 |
| 8 | 8 | 5 | 29 | 29 | 699 | 5 | 97 | 115 | 1040 |
从训练集对训练结果进行分析,测试集类似。
观察每个类别的F1值(综合了查准率与查全率)发现:
爬虫 ,跨站脚本攻击,扫描工具,协议违规针对ie8的跨站脚本攻击值F1值较低,其余的F1值较高,大概在百分之九十多。
从训练集混淆矩阵分析发现:
1)爬虫 ,跨站脚本攻击,扫描工具,协议违规,针对ie8的跨站脚本攻击大约有两万条;
2)爬虫 ,跨站脚本攻击,扫描工具,协议违规,针对ie8的跨站脚本攻击被正确分类的个数依次为:15054,14451,9147,12865,9856;
3)爬虫被误分类为协议违规(1129条),扫描工具(838条),漏洞防护(614条);
4)跨站脚本攻击容易被误分类为协议违规(1257条),扫描工具(931条),针对ie8的跨站脚本攻击(642条);
5)扫描工具容易被误分类为协议违规(4179条),爬虫(3418条 );
6)协议违规容易被误分类为扫描工具(3282条 ),跨站脚本攻击(677条),爬虫(502条);
7)针对ie8的跨站脚本攻击最容易被误分类跨站脚本攻击(58160),其次是协议违规(889条),扫描工具(763条)。
综上所述:
XSS 攻击与针对ie8的跨站脚本攻击payload较为相似,协议违规,扫描工具,爬虫payload也较为接近,下阶段需要进一步细分对这些攻击类别的判别方式,从而设计特征进行区分。
*本文原创作者:王Sir_甜橙金融,本文属FreeBuf原创奖励计划,未经许可禁止转载





