![]()
本文约4700字,建议阅读15分钟
本文为大家介绍了多种图挖掘工具,并运用Spark为大家展示了一个标签传播算法LPA构建图的实例。
(https://towardsdatascience.com/large-scale-graph-mining-with-spark-750995050656)
如何运用神奇的图。我们将讨论标签传播,Spark GraphFrame和结果。
下文可回顾示例图和笔记:
https://github.com/wsuen/pygotham2018_graphmining
在第1部分,我们看到了如何使用图来解决无监督的机器学习问题,因为社区是集群。我们可以利用节点之间的边作为相似性或相关性的指标,特征空间中的距离可用于其他类型的聚类。
本文将深入探讨社区检测的方式。我们构建和挖掘一个大型网络图,学习如何在Spark中实现标签传播算法(LPA)的社区检测方法。
尽管有许多社区检测技术,但本文仅关注一种:标签传播。有关其他方法的概述,我推荐Santo Fortunato的“图形中的社区检测”
(https://arxiv.org/pdf/0906.0612.pdf)
。
![]()
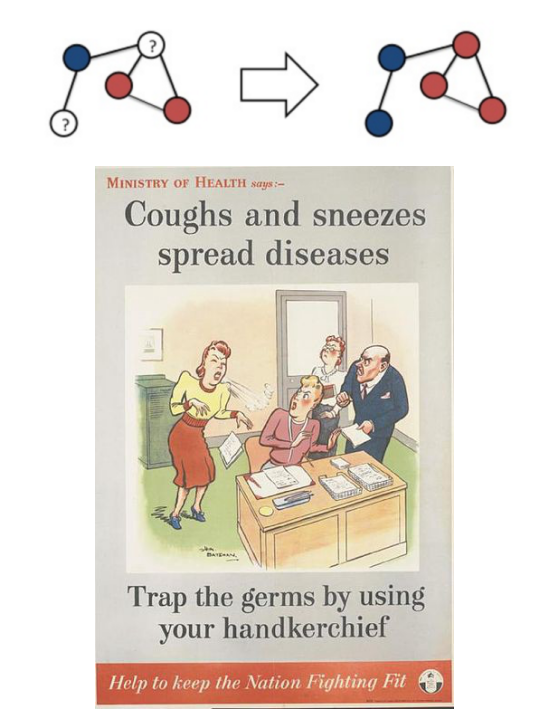
Raghavan,Usha Nandini,RékaAlbert和Soundar Kumara“在大型网络中检测社区结构的近线性时间算法。”物理评论E 76.3(2007):036106
2、每次迭代会随机遍历所有节点。用其大多数邻居的标签来更新每个节点的社区标签,随意打破任何联系。
3、如果现在所有节点都是用大多数邻居的标签标记的,则该算法已达到停止标准。如果不是,重复步骤2。
![]()
标签传播很直观。假设某个工作日,你的同事得了感冒并“传播”病毒,办公区中的每个人都会和周围的人一样病重。与此同时,FoobarCo的员工在街上感染并开始传播流感。你与FoobarCo之间的联系并不多,因此当每个社区的成员患上疾病时,“传播”就会停止,达到融合!虽然流鼻涕和头痛太糟糕了。
带标签的数据很好,但不是必需的。使LPA适用于我们的无监督机器学习用例。
参数调整非常简单。LPA使用max_iterations参数运行,并且使用默认值5就可以获得良好的结果。Raghavan和她的合作者针对几个标记的网络测试了LPA。他们发现至少有95%的节点在5次迭代中被正确分类。
集群的先验数量,集群的大小,不需要其他指标。如果你不希望图形具有特定的结构或层次结构,那么这一点至关重要。我没有关于网络图的网络结构、拥有数据的社区数量或这些社区的预期规模的先验假设。
接近线性运行时间。LPA的每次迭代均为O(m),与边数成线性。与此前某些社区检测解决方案的O(n log n)或O(m + n)相比,整个步骤的顺序接近线性时间。
可解释性。可以给别人解释为什么将节点分到某个社区。
![]()
比利时移动网络中的语言社区(红色=法语,绿色=荷兰语)。图片来自Blondel,Vincent D.等人。“大型网络中社区的快速发展。”统计力学杂志:理论与实验2008.10(2008):P10008
首先对工具领域进行一个简要的分析。我根据图的大小,该库是否适配Python以及能否生成简单的可视化效果来划分工具。
![]()
对于适合在一台计算机上计算的数据,networkx
(https://networkx.github.io/)
Python软件包是探索图的理想选择,它实现了最常见的算法(包括标签传播,PageRank,最大集团检测等),简单的可视化也是可能的。
Gephi
(https://gephi.org/)
是一个开源的图分析工具。Gephi不是Python软件包,而是具有强大UI和强大图形可视化功能的独立工具。如果你的图较小,需要强大的可视化效果,并且希望使用UI而不是使用Python,Gephi是个不错的选择。
Spark有2个图形库:GraphX
(https://spark.apache.org/docs/latest/graphx-programming-guide.html)
和GraphFrames
(https://graphframes.github.io/)
。
当图形数据太大而无法容纳在一台机器上(受限于分配的Spark应用程序的资源量),想要利用并行处理以及一些Spark的内置容错功能时,Spark是一个很好的解决方案。Spark的Python API Pyspark非常适合集成到scikit-learn,matplotlib或networkx等其他库中。
Apache Giraph
(https://giraph.apache.org/)
是Pregel
(https://kowshik.github.io/JPregel/pregel_paper.pdf)
的开源实现,Pregel是Google创建的图形处理架构。与以前的解决方案相比,Giraph的进入壁垒更高。
尽管Giraph对于大规模图形分析部署非常强大,但我选择了同时具有Scala和Python API的轻量级产品。
Neo4j是一个图形数据库系统。它确实有一个Python客户端,但是必须单独安装Neo4j。由于我的分析只是一个POC,因此我想避免维护和部署完全独立的工具,它没有与现有代码集成。
最后,理论上你可以直接实现自己的解决方案。对于初步的数据科学探索,我不建议这样做。许多定制的图挖掘算法都针对非常特定的用例(例如,仅在图聚类方面超级有效,而在其他方面则没有效率)。如果确实需要使用非常大的数据集,则首先考虑对图形进行采样,过滤感兴趣的子图,从示例中推断关系,可以从现有任意工具中获得更多收益。
根据我正在研究的数据大小,我选择了Spark GraphFrames。
请记住:适合您的项目的最佳图形库取决于语言,图形大小,存储图形数据的方式以及个人喜好!
我觉得图表非常棒,它们是有史以来最酷的东西!如何开始对真实数据使用社区检测呢?
1、获取数据:
Common Crawl数据集
(https://commoncrawl.org/the-data/get-started/)
是一个非常适合网页图研究的开源网页爬虫语料库。搜寻结果以WARC(网络存档)格式存储。除页面内容外,数据集还包含爬网日期,使用的标题和其他元数据。
我从2017年9月的爬虫数据
(https://commoncrawl.org/2017/09/september-2017-crawl-archive-now-available/)
中采样了100个文件。文件warc.paths.gz包含路径名;使用这些路径名,从s3下载相应的文件。
![]()
2、解析和清理数据:
首先我们需要每个页面的html内容。对于每个页面,我们收集URL和所有链接的URL以创建图。
为了从原始WARC文件中提取边,我编写了一些数据清理代码,这些代码可能永远被压在箱底。至少完成了工作,所以我可以专注于更多有趣的事情!我的解析代码是用Scala编写的,但我的演示是在pyspark中进行的。我使用了WarcReaderFactory和Jericho解析器。python中,像warc这样的库可以满足数据处理需求。
我在域之间画出了边,而不是完整的URL。我没有创建medium.com/foo/bar和medium.com/foobar,而是创建了一个节点medium.com,该节点捕获了与其他域之间的链接关系。
我过滤掉了环。环是将节点连接到自身的边,对于我的目标没有用。如果medium.com/foobar链接到同一域,例如medium.com/placeholderpage,则不会绘制任何的边。
我删除了许多最受欢迎的资源链接,包括热门的CDN,trackers和assets。我的初步探索只想关注人可能访问的网页。
3、初始化Spark上下文:
对于那些在本地进行尝试的人,请参见
https://github.com/wsuen/pygotham2018_graphmining
上的演示。该演示仅在本地计算机上运行。无法获得分布式集群的所有计算资源,但是可以了解如何开始使用Spark GraphFrames。
我将使用Spark 2.3导入pyspark和其他所需的库,包括图形框架。然后创建一个SparkContext,它可以运行pyspark应用程序。
# add GraphFrames package to spark-submitimport osos.environ['PYSPARK_SUBMIT_ARGS'] = '--packages graphframes:graphframes:0.6.0-spark2.3-s_2.11 pyspark-shell'import pyspark# create SparkContext and Spark Sessionsc = pyspark.SparkContext("local[*]")spark = SparkSession.builder.appName('notebook').getOrCreate()# import GraphFrames
4、创建一个图框架:
在清除数据后,你就可以将顶点和边加载到Spark DataFrames中。
vertices包含每个节点的id,以及该节点的name(表示域)。
edges包含我的有向边,从源域src到源链接到的域dst。
# show 10 nodesvertices.show(10)+--------+----------------+| id| name|+--------+----------------+|000db143| msn.com||51a48ea2|tradedoubler.com||31312317| microsoft.com||a45016f2| outlook.com||2f5bf4c8| bing.com|+--------+----------------+only showing top 5 rows# show 10 edgesedges.show(10)+--------+--------+| src| dst|+--------+--------+|000db143|51a48ea2||000db143|31312317||000db143|a45016f2||000db143|31312317||000db143|51a48ea2|+--------+--------+only showing top 5 rows
然后,可以使用顶点和边创建GraphFrame对象。你有图了!
# create GraphFramegraph = GraphFrame(vertices, edges)
5、运行LPA:
一行代码允许您运行LPA。在这里,我以5次迭代(maxIter)运行LPA。
graph.labelPropagation(maxIter=5)communities.persist().show(10)+--------+--------------------+-------------+| id| name| label|+--------+--------------------+-------------+|407ae1cc| coop.no| 781684047881||1b0357be| buenacuerdo.com.ar|1245540515843||acc8136a| toptenreviews.com|1537598291986||abdd63cd| liberoquotidiano.it| 317827579915||db5c0434| meetme.com| 712964571162||0f8dff85| ameblo.jp| 171798691842||b6b04a58| tlnk.io|1632087572480||5bcfd421| wowhead.com| 429496729618||b4d4008d|investingcontrari...| 919123001350||ce7a3185| pokemoncentral.it|1511828488194|+--------+--------------------+-------------+only showing top 10 rows
运行graph.labelPropagation()将返回一个带有节点和label的数据框,该标签指示该节点所属的社区。您可以使用label来了解社区大小的分布并放大感兴趣的区域。例如,要发现与pokemoncentral.it在同一社区中的所有其他网站(老实说,谁不愿意),请过滤掉label = 1511828488194的所有其他节点。
当我在示例Common Crawl Web图上运行LPA时发生了什么?
![]()
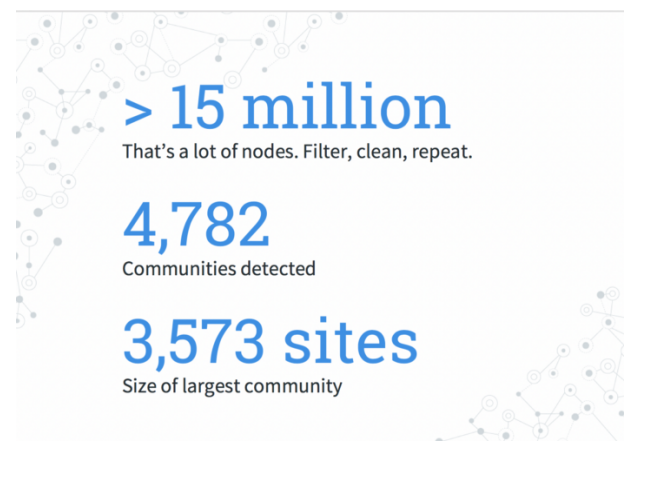
我最初在原始数据中拥有超过1500万个网站。有很多节点,其中许多包含冗余信息。我描述的数据清洗过程将图压缩成更少,更有意义的边。
社区规模的极端说明了LPA的一个缺点。收敛太多可能会导致簇太大(由某些标签主导密集连接的网络)。融合太少,可能会得到更多、更有用的较小社区。我发现最有趣的簇常常位于两个极端之间。
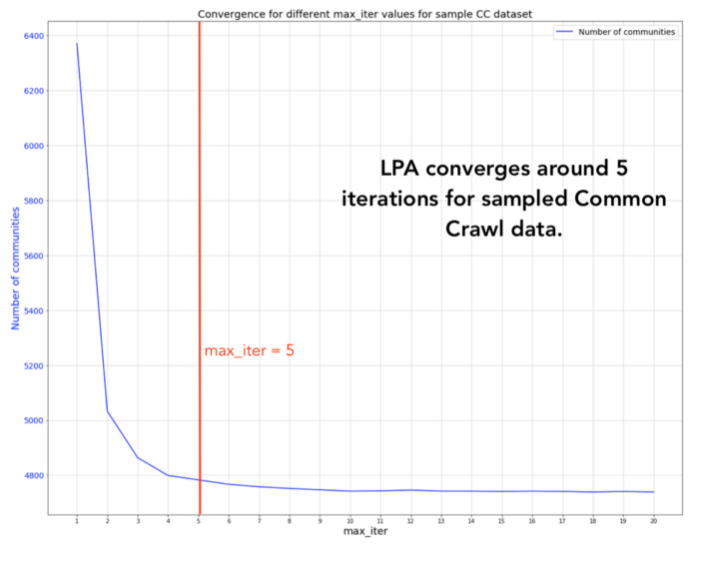
在我的数据集中,LPA确实收敛了约5次迭代。可以看到社区数量趋于稳定,大约为4,700。Raghavan和她的同事们也通过其带有标签的图表显示了此属性。
解释这种情况的一种可能机制是小世界网络效应–图趋于聚集的趋势,但与节点数相比,路径长度也较短。换句话说,尽管图具有聚类,但是还希望能够在5到6步之内从一个朋友到网络中的另一个朋友。许多现实世界的图形(包括Internet和社交网络)也有这个特点,也可以称为六度分离现象。
![]()
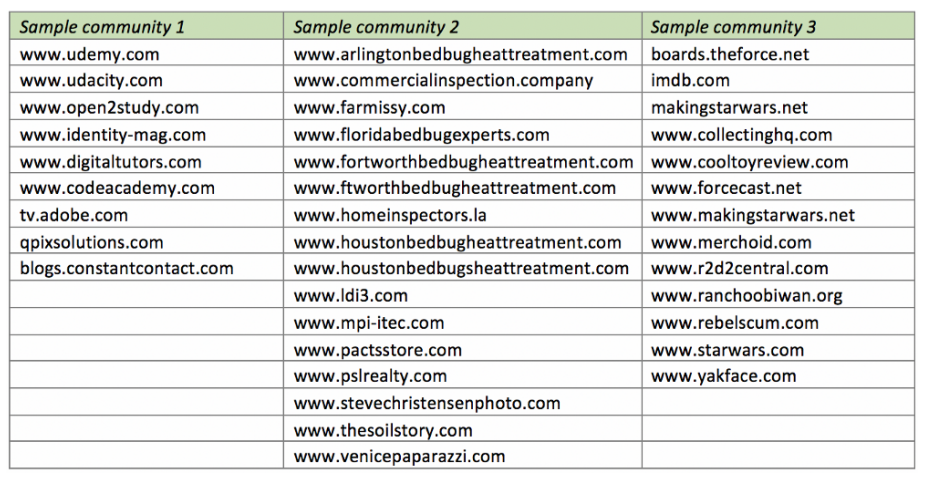
让我们简单看一些样本集群。与传统的无监督群集一样,社区可以是不同站点的混合,但是如果没有LPA,我们将错过一些有趣的话题!从左到右:
电子学习站点:与电子学习页面相关或链接到该站点的站点。是时候找一些新的数据科学MOOC了!
Bedbug网站:与房地产和臭虫相关的网站。所有这些站点都使用相同的模板/图像,只是域名略有不同,数量不止于此。
《星球大战》社区:谈论《星球大战》电影,事件和纪念品的站点经常相互链接。
![]()
值得强调的是,我们在没有文本处理和功能选择、手动标记、域名功能甚至不知道可以找到多少个社区的情况下获得了这些集群。我们利用网络图的底层网络结构找到了感兴趣的社区!
这仅仅是网络图社区的冰山一角,未来的研究可以有很多方向。例如:
分层并传播元数据:如果我们向数据添加诸如边权重,链接类型或外部标签之类的信息,那么如何在图中传播此信息呢?
删除/添加节点并衡量对社区的影响:我很好奇如何添加或删除具有较高边缘集中度的节点会改变LPA的有效性和最终社区的质量。
观察网络图随时间的演变:每个月都有一个新的Common Crawl数据集!观察随着时间的推移会出现什么集群会很有趣。相反,哪些社区保持不变?我们知道,互联网不是一成不变的。
该示例的Github存储库
(https://github.com/wsuen/pygotham2018_graphmining)
包含一个由1万个节点组成的小样本网络图形。还有关于使用Docker进行设置和运行pyspark笔记本的说明。我希望这将有助于开始使用Web图数据进行实验,并帮助你在数据科学问题中学习Spark GraphFrame。
![]()
我们是先驱者!
感谢Yana Volkovich博士加深了我对图论的学习,并成为一名出色的导师。也要感谢我的其他同事对我的演讲提供了反馈。
Adamic, Lada A., and Natalie Glance. “The political blogosphere and the 2004 US election: divided they blog.” Proceedings of the 3rd international workshop on Link discovery. ACM, 2005.
Common Crawl dataset (September 2017).
Farine, Damien R., et al. “Both nearest neighbours and long-term affiliates predict individual locations during collective movement in wild baboons.” Scientific reports 6 (2016): 27704
Fortunato, Santo. “Community detection in graphs.” Physics reports 486.3–5 (2010): 75–174.
Girvan, Michelle, and Mark EJ Newman. “Community structure in social and biological networks.” Proceedings of the national academy of sciences99.12 (2002): 7821–7826.
Leskovec, Jure, Anand Rajaraman, and Jeffrey David Ullman. Mining of massive datasets. Cambridge University Press, 2014.
Raghavan, Usha Nandini, Réka Albert, and Soundar Kumara. “Near linear time algorithm to detect community structures in large-scale networks.” Physical review E 76.3 (2007): 036106.
Zachary karate club network dataset — KONECT, April 2017.
Large-scale Graph Mining with Spark: Part 2
https://towardsdatascience.com/large-scale-graph-mining-with-spark-part-2-2c3d9ed15bb5
陈丹,复旦大学大三在读,主修预防医学,辅修数据科学。对数据分析充满兴趣,但初入这一领域,还有很多很多需要努力进步的空间。希望今后能在翻译组进行相关工作的过程中拓展文献阅读量,学习到更多的前沿知识,同时认识更多有共同志趣的小伙伴!
![]()
![]()
![]()