复盘《星际2》人机大战:职业高手首次被AI击败 5分钟就溃退
点击上方“腾讯科技”,“星标或置顶公众号”
关键时刻,第一时间送达


来源 / 量子位(ID:QbitAI)
作者 / 边策 栗子 夏乙
欢迎下载腾讯新闻客户端,关注科技页卡,查看更多科技热点新闻
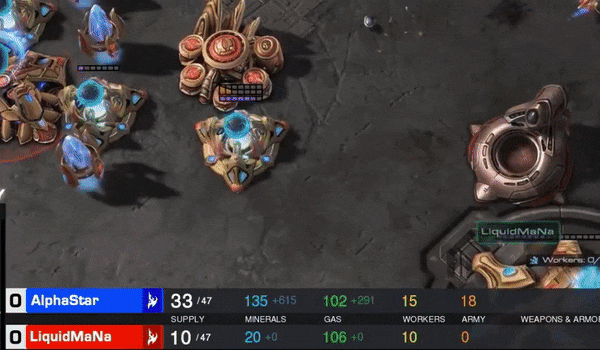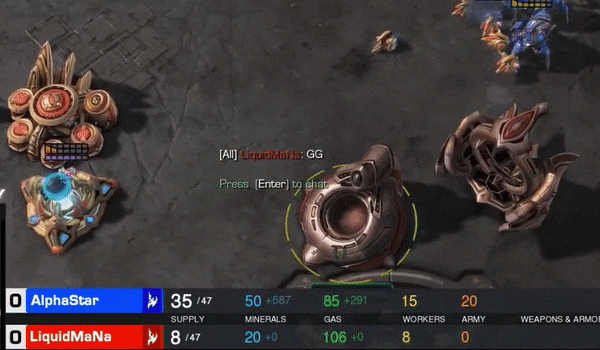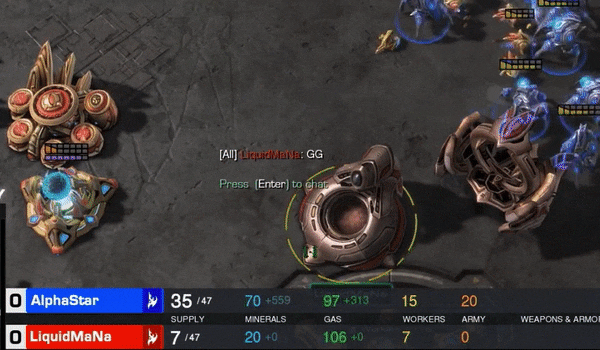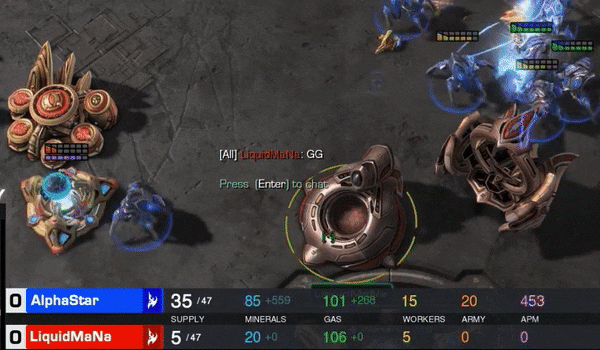
5分36秒的战斗后,LiquidMaNa打出:GG。
DeepMind开发的全新AI程序AlphaStar,在今天凌晨的《星际争霸2》人机大战直播节目中,轻松战胜2018 WCS Circuit排名13、神族最强10人之一的MaNa。
实际上,AlphaStar以10-1的战绩,全面击溃了人类职业高手。
战败的不止MaNa,还有另一位高手TLO。
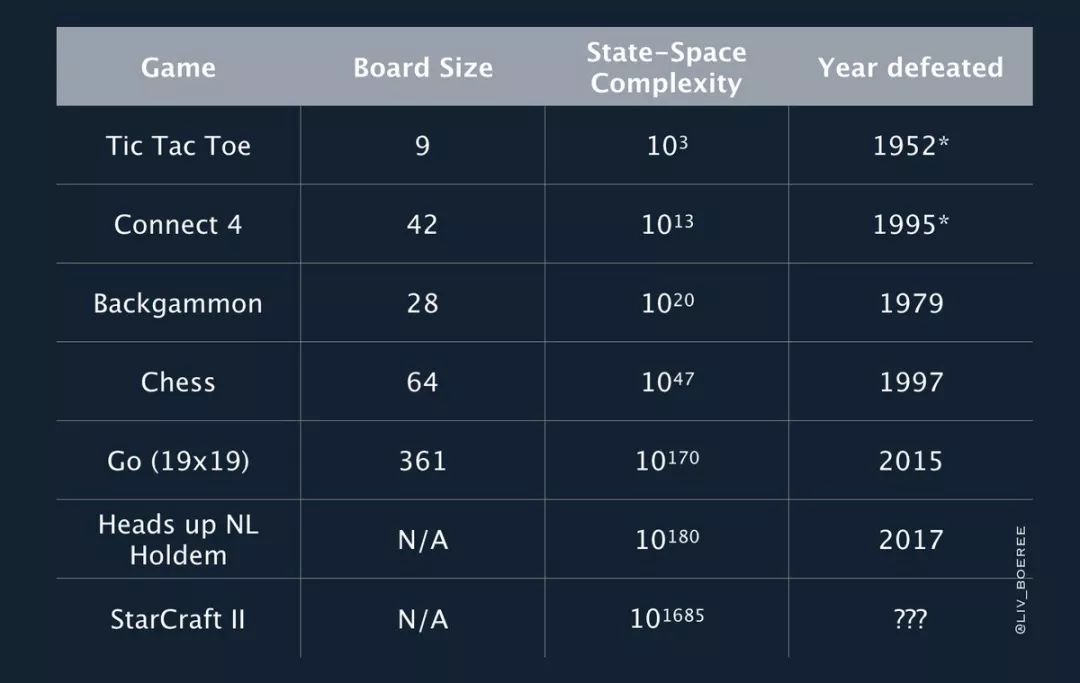
人工智能在《星际争霸2》上的进步速度,远远超过了此前外界的预期。毕竟与下围棋这件事相比,星际2要难得多。

在围棋世界,动作空间只有361种,而星际2大约是1026。
与围棋不同,星际玩家面对的是不完美信息博弈。“战争迷雾”意味着玩家的规划、决策、行动,要一段时间后才能看到结果。
这意味着,AI需要学到长远的布局谋篇的策略能力。
即便如此,AlphaStar最终还是学会了如何打星际2。即便此次黄旭东保持克制、谁也没奶,但既定的事实已经无法更改。
直播进行到一半,就有网友在他的微博下留言:比国足输伊朗还惨。
尽管10战连败,人类职业高手仍然对人工智能不吝称赞:不可思议。MaNa说,我从AI身上学到了很多。以及,今天最后一局MaNa也为人类争取到了仅有的胜利!
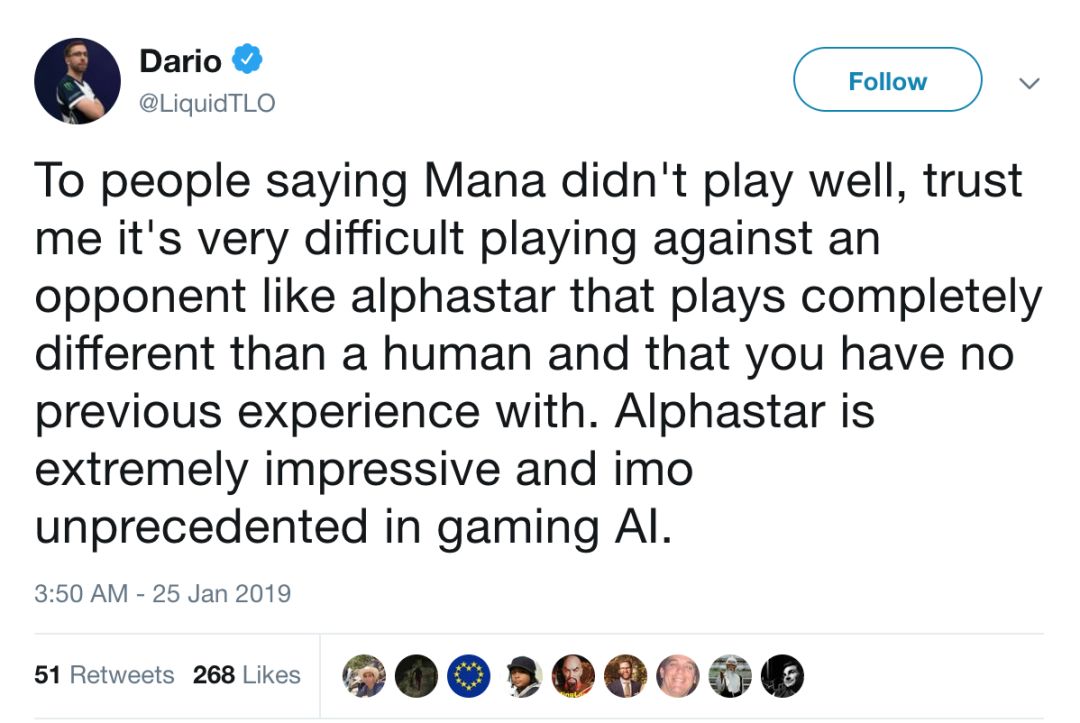
赛后,TLO的说法跟李世乭输给AlphaGo后很像。他说:相信我,和AlphaStar比赛很难。不像和人在打,有种手足无措的感觉。他还说,每局比赛都是完全不一样的套路。
为什么AI这么强?别的先不展开讲,这里只说一个点。其实在比赛之前,AlphaStar的训练量,相当于打了200年实时对抗的星际2。
总而言之,谷歌DeepMind历时两年,终于让人工智能更进一步,AlphaGo有了新的接班人AlphaStar。
DeepMind CEO哈萨比斯说,AlphaStar的技术未来可用于预测天气、气候建模等需要very long sequences的应用场景。
一次里程碑意义的战斗,落下帷幕。
一次人类的新征程,正式开场。

AlphaStar:10-1
实际上,今天的人机大战主要内容并不是直播,而是回顾人机大战的结果。简单交待一下相关信息,比赛在Catalyst地图上进行,这张地图中文名叫“汇龙岛”。

图上设置了很多隘口和高地,网友说,这张图群龙盘踞,大战一触即发,官方称“能创造出许多有意思的进攻路径和防守阵形”。
游戏版本是去年10月的4.6.2,双方都使用神族(星灵)。
第一场比赛,发生在去年12月12日。
AlphaStar对TLO。

第一局人类选手TLO开局两分钟后就率先发难,不过AlphaStar扛下来,并且逐渐扭转了战局,迅速累积起资源优势。
5分钟左右,AlphaStar以追猎者为主要作战单位,开始向TLO发起试探性的攻击。并且在随后的时间里,持续对TLO展开骚扰,直至取胜。
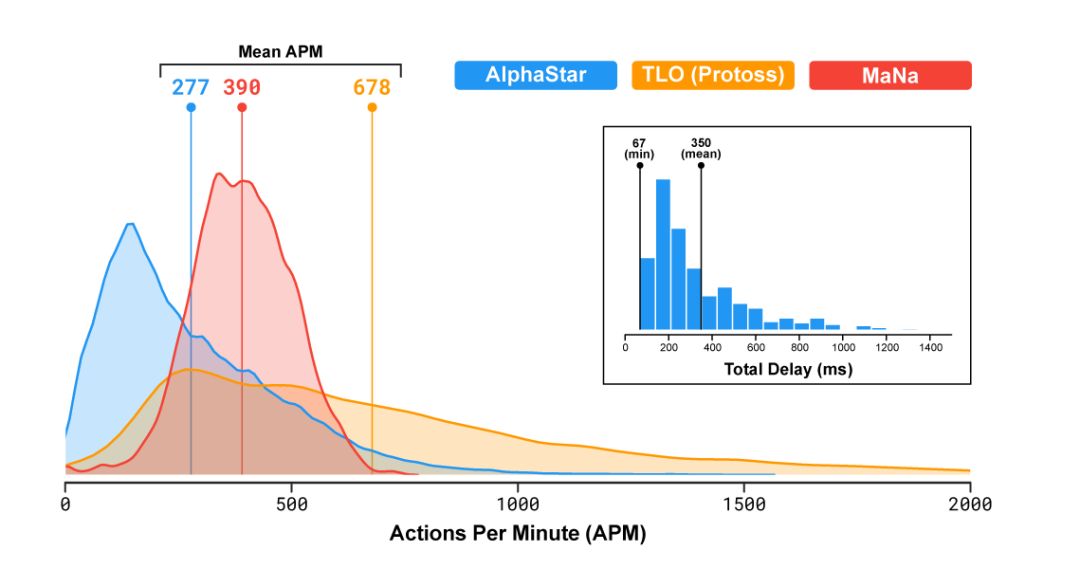
DeepMind介绍,比赛中,实际上AlphaGo的APM比TLO要低。AlphaStar的APM中值是277,而TLO的APM中值是390。而大部分其他bot的APM,都高达几千甚至数万。
前三局基本都是这样。TLO说第四局就像换了个AI一样,打法完全变了,很接近典型神族打法。
当然,他又输了。这个感觉没错,其实他每次对阵的AI都不一样……
最后的结果是0-5,TLO一局没赢。不过他说:如果我多练练神族,我能轻易打败这些AI。毕竟TLO这些年一直主要在练虫族。
五局比赛打完,DeepMind团队为了庆祝喝了点酒,产生了一个大胆的想法:
再训练训练,和玩神族的职业选手打一场。
于是,快到圣诞节的时候,他们请来了Liquid的神族选手MaNa。
第二场比赛,发生在去年12月19日。
据说,MaNa五岁就开始打星际了。
在对战MaNa之前,AlphaStar又训练了一个星期。双方展开较量之前,MaNa只知道TLO输了,不知道是5-0,而且,明显没有TLO上次来那么紧张。
面对神族最强10人之一,DeepMind认为比赛会很精彩,但对胜利没什么自信。

双方第一局对决,AlphaStar在地图的左上角,MaNa在右下。4分钟,AlphaStar派出一队追猎者,开始进攻。基本上算是一波就推了MaNa。
正如开始所说,5分36秒,MaNa打出GG。
然后第二局也输了。这时候MaNa紧张起来,第三局决心翻盘。7分30秒,AlphaStar出动了一支大军打到MaNa家,MaNa GG。
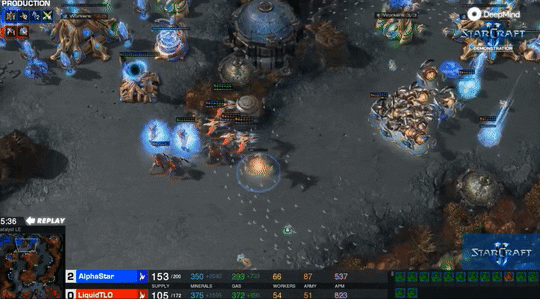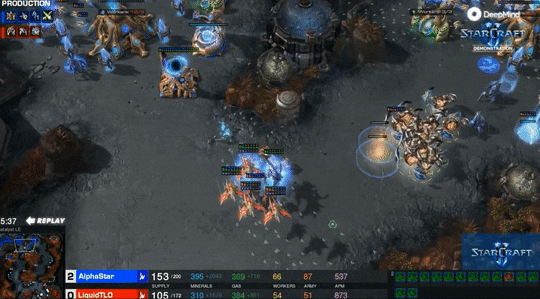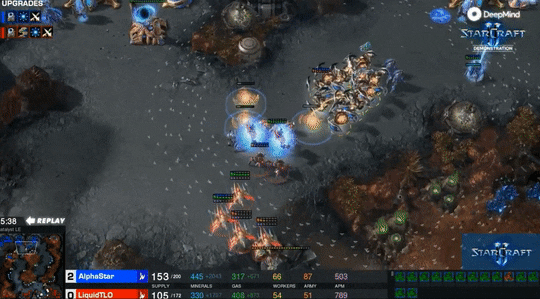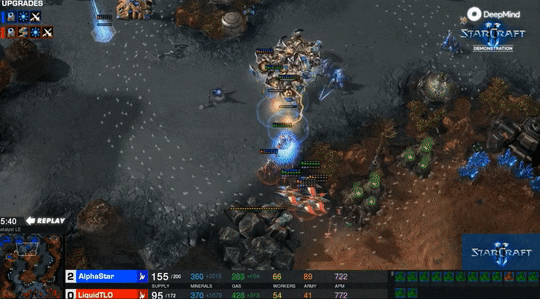
最精彩的是第四局,MaNa的操作让现场解说叹为观止,他自己赛后也坦言”真是尽力了“。但最后,他的高科技军团在一群追猎者的360度包围下,全灭。MaNa打出了GG。
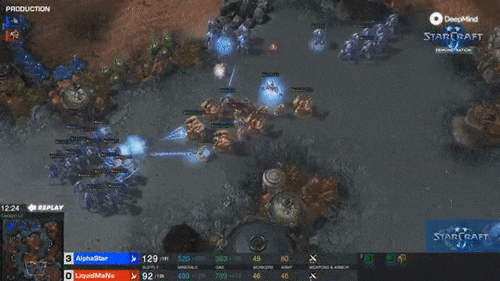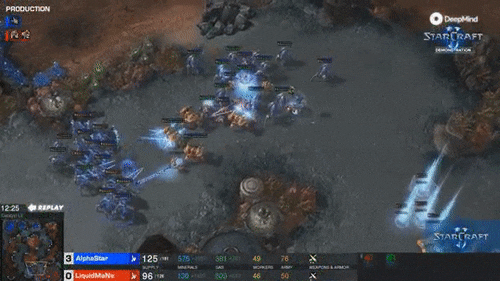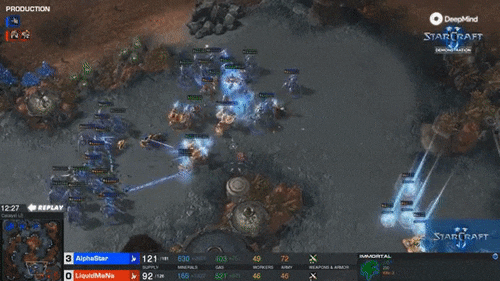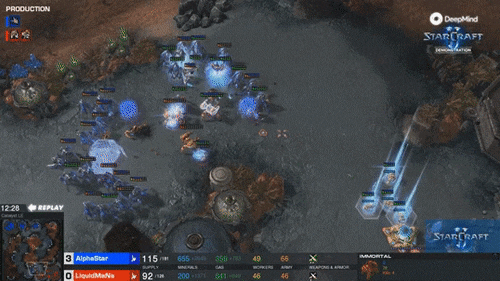
而且,AlphaStar完成360度包围这一高难度操作时,APM只有250左右。
第四局全程:
需要说明的是,其实在这局比赛中,AlphaStar的APM几乎已经失控,几度飙到1000多。量子位抓到了一些这样的瞬间。
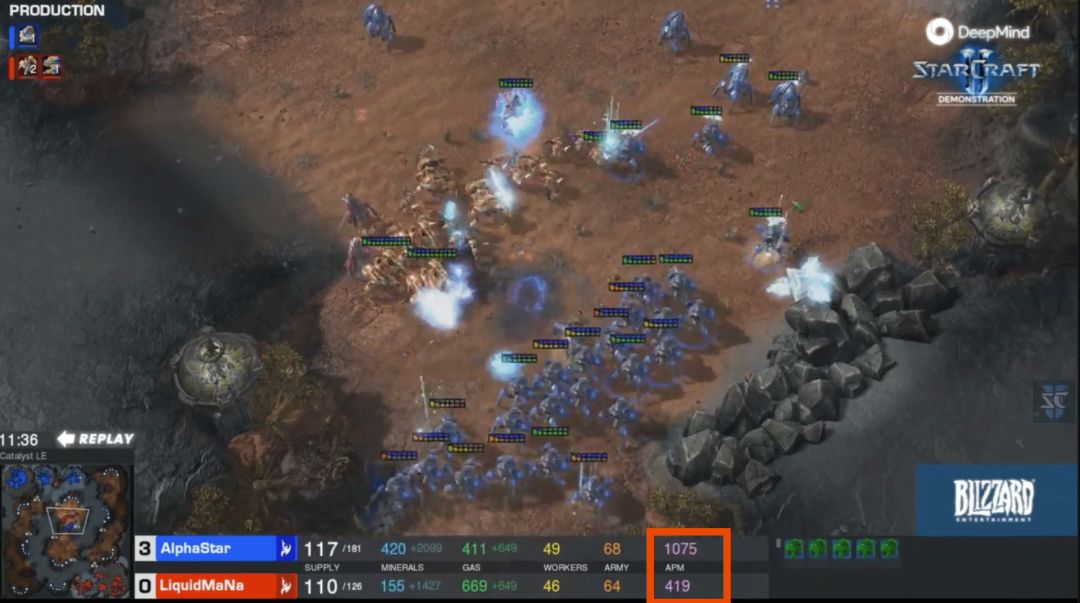
MaNa说,输了好失望,我能出的单位都出了,最后输给了一群追猎者?他还说,AlphaStar的微操太厉害了。incredible。跟AI学东西,这种经历挺好。
人类扳回一城
今天的直播的最后,是现场的表演局(Exhibition game),直播MaNa对战AlphaStar。
在这场比赛中,MaNa采用了一种更激进的打法,一开局就造了更多的农民(探机),这说不定是上个月刚刚跟AlphaStar学来的战术。
12分钟后,MaNa一路拆掉AlphaStar的各种建筑,击败了无法打出GG的AlphaStar。
总算是帮人类挽回一些颜面。
这场比赛,全程在此:
另外DeepMind也放出了全部11局对决的视频,有兴趣可以前往这个地址查看:
https://deepmind.com/research/alphastar-resources/
之前的10局比赛,DeepMind还拍成了一个纪录片。
解读AlphaStar
DeepMind和暴雪周三发出预告后,热情的网友们就已经把各种可能的技术方案猜了一遍。
现在答案揭晓:
AlphaStar学会打星际,全靠深度神经网络,这个网络从原始游戏界面接收数据(输入),然后输出一系列指令,组成游戏中的某一个动作。
再说得具体一些,神经网络结构对星际里的那些单位,应用一个Transformer,再结合一个深度LSTM核心,一个自动回归策略(在头部),以及一个集中值基线(Centralised Value Baseline)。
DeepMind团队相信,这个进化了的模型,可以为许多其他机器学习领域的难题带来帮助:主要针对那些涉及长期序列建模、输出空间很大的问题,比如语言建模和视觉表示。
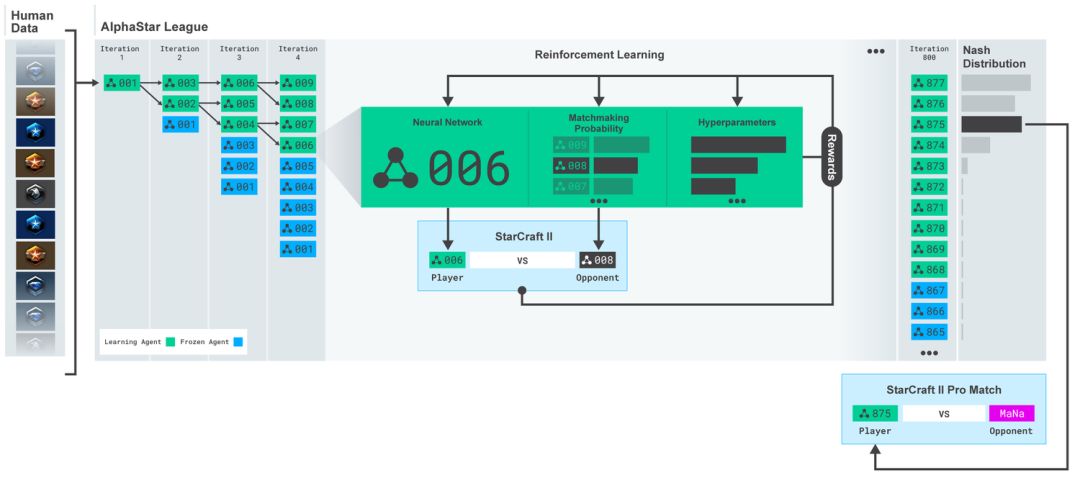
AlphaStar还用了一个新的多智能体学习算法。
这个神经网络,经过了监督学习和强化学习的训练。
最开始,训练用的是监督学习,素材来自暴雪发布的匿名人类玩家的游戏实况。
这些资料可以让AlphaStar通过模仿星际天梯选手的操作,来学习游戏的宏观和微观策略。
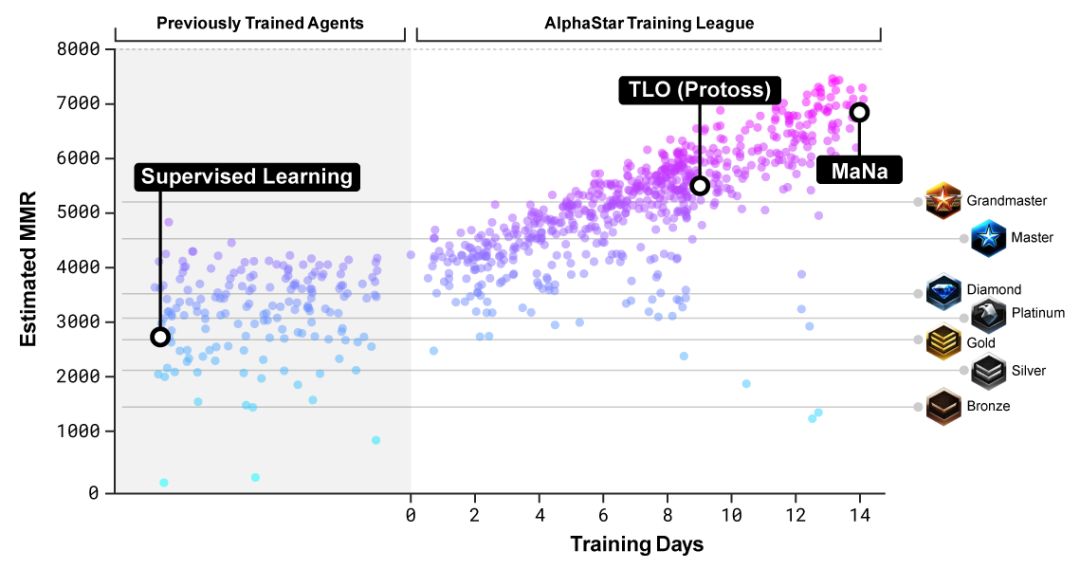
最初的智能体,游戏内置的精英级(Elite)AI就能击败,相当于人类的黄金段位(95%)。
而这个早期的智能体,就是强化学习的种子。
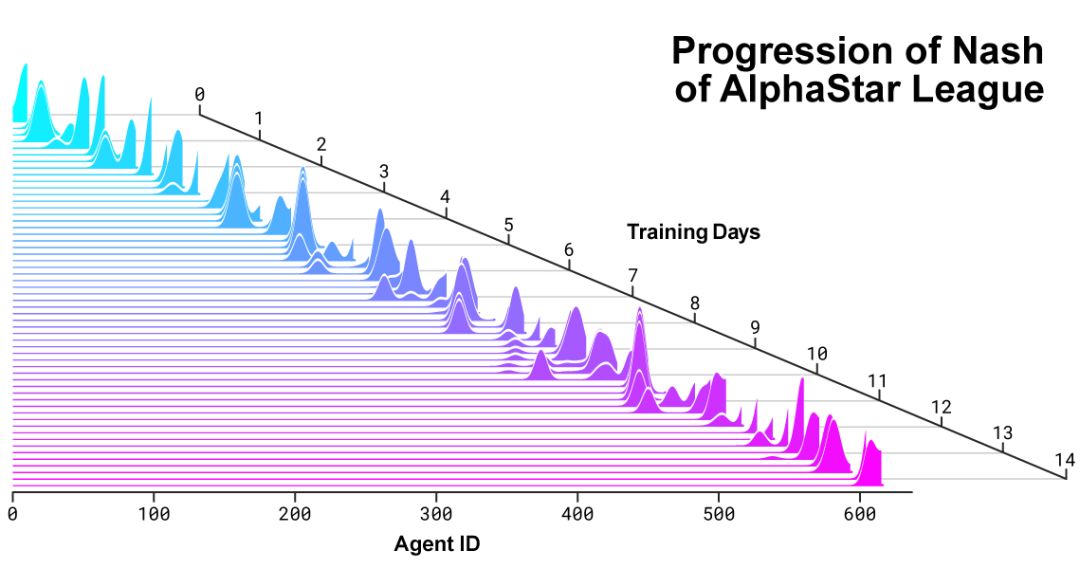
在它的基础之上,一个连续联赛(Continuous League)被创建出来,相当于为智能体准备了一个竞技场,里面的智能体互为竞争对手,就好像人类在天梯上互相较量一样:
从现有的智能体上造出新的分支,就会有越来越多的选手不断加入比赛。新的智能体再从与对手的竞争中学习。
这种新的训练形式,是把从前基于种群(Population-Based)的强化学习思路又深化了一些,制造出一种可以对巨大的策略空间进行持续探索的过程。
这个方法,在保证智能体在策略强大的对手面前表现优秀的同时,也不忘怎样应对不那么强大的早期对手。
随着智能体联赛不断进行,新智能体的出生,就会出现新的反击策略(Counter Strategies),来应对早期的游戏策略。
一部分新智能体执行的策略,只是早期策略稍稍改进后的版本;而另一部分智能体,可以探索出全新的策略,完全不同的建造顺序,完全不同的单位组合,完全不同的微观微操方法。
早期的联赛里,一些俗气的策略很受欢迎,比如用光子炮和暗黑圣堂武士快速rush。
这些风险很高的策略,在训练过程中就被逐渐抛弃了。同时,智能体会学到一些新策略;比如通过增加工人来增加经济,或者牺牲两个先知来来破坏对方的经济。
这个过程就像人类选手,从星际争霸诞生的那年起,不断学到新的策略,摒弃旧的策略,直到如今。
除此之外,要鼓励联赛中智能体的多样性,所以每个智能体都有不同的学习目标:比如一个智能体的目标应该设定成打击哪些对手,比如该用哪些内部动机来影响一个智能体的偏好。
而且,智能体的学习目标会适应环境不断改变。

神经网络给每一个智能体的权重,也是随着强化学习过程不断变化的。而不断变化的权重,就是学习目标演化的依据。
权重更新的规则,是一个新的off-policy演员评论家强化学习算法,里面包含了经验重播(Experience Replay),自我模仿学习(Self-Imitation Learning)以及策略蒸馏(Policy Distillation)等等机制。
为了训练AlphaStar,DeepMind用谷歌三代TPU搭建了一个高度可扩展的分布式训练环境,支持许多个智能体一起从几千个星际2的并行实例中学习。每个智能体用了16个TPU。
智能体联赛进行了14天,这相当于让每一个智能体都经历了连打200年游戏的训练时间。
最终的AlphaStar智能体,是联赛中所有智能体的策略最有效的融合,并且只要一台普通的台式机,一块普通的GPU就能跑。
AlphaStar打游戏的时候,在看什么、想什么?
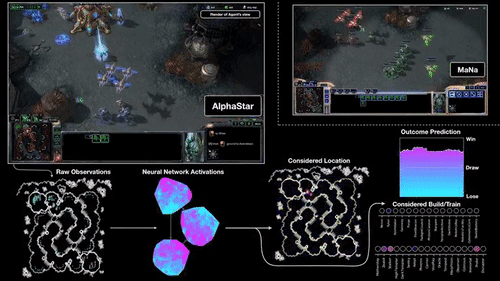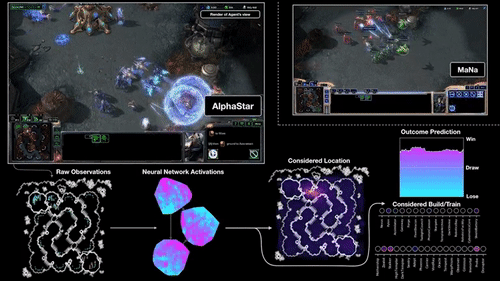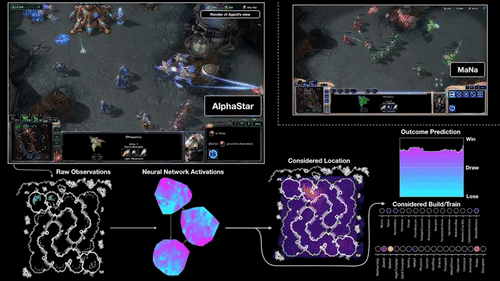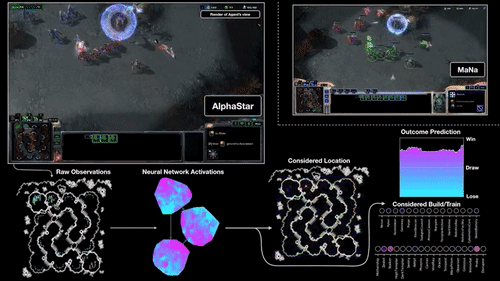
上图,就是DeepMind展示的AI打游戏过程。
原始的观察里数据输入到神经网络之中,产生一些内部激活,这些激活会转化成初步的决策:该做哪些操作、点击什么位置、在哪建造建筑等等。另外,神经网络还会预测各种操作会导致的结果。
AlphaStar看到的游戏界面,和我们打游戏时看到的小地图差不多:一个小型完整地图,能看到自己在地图上的所有单位、以及敌方所有可见单位。
这和人类相比有一点点优势。人类在打游戏的时候,要明确地合理分配注意力,来决定到底要看哪一片区域。
不过,DeepMind对AlphaStar游戏数据的分析显示,它观察地图时也有类似于人类的注意力切换,会平均每分钟切换30次左右关注的区域。
这,是12月打的10场游戏的情况。
今天直播中和MaNa对战的AI,就略有不同。
连胜之后,DeepMind团队总会有大胆的想法冒出来——他们迭代了第二版AlphaStar,这一版和人类观察地图的方式是一样的,也要不停选择将视野切换到哪,只能看到屏幕上视野范围内的信息,而且只能在这个范围内操作。
视野切换版AlphaStar经过7天训练,达到了和第一版差不多的水平。
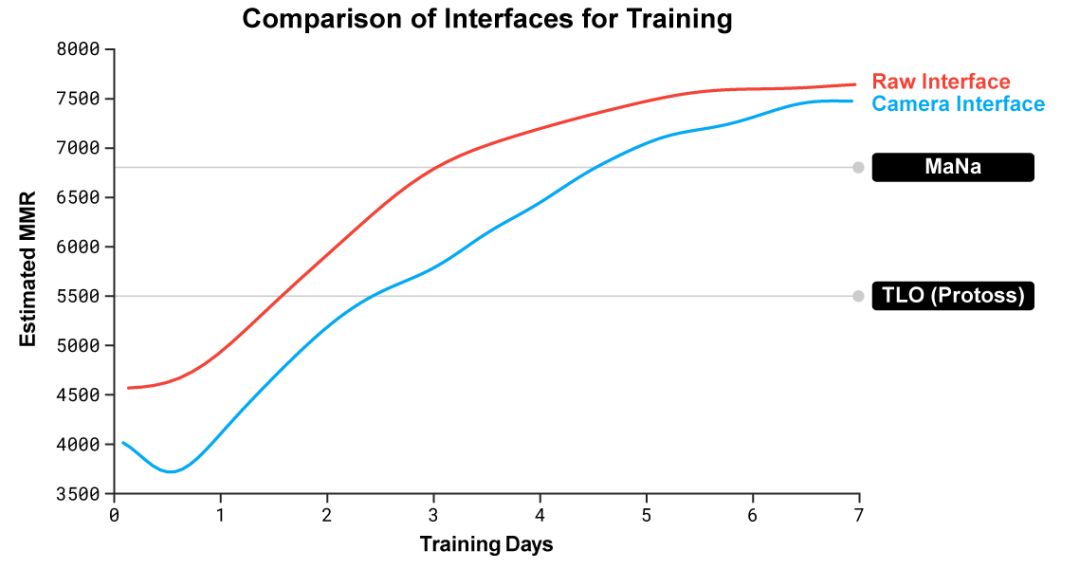
不过,这个版本的智能体原型还是在今天的直播中输给了MaNa,成为了10-1里的1。
DeepMind对他们的AI仍然充满信心,他们在博客中说,这个智能体只训练了7天,希望能在不久的将来,能测试一个完全训练好了的视野版智能体。
现在,AlphaStar还只能玩神族。DeepMind说,他们为了在内部测试中减少训练时间和变量,决定先只玩一个种族。
不过,这不代表它就学不会其他种族。同样的训练流程,换个种族还是一样用。
星际界的樊麾和带路党
这次人机大战背后,有很多人的努力,我们这次重点介绍三个人。
首先是AlphaStar的两个人类对手。
TLO是一位德国职业星际2选手,原名Dario Wünsch,1990年7月13日出生。现在效力于职业游戏战队Liquid。
之前TLO有个称号:随机天王。星际2的公测阶段,他使用哪个种族都得心应手,不过后来,TLO开始逐渐专攻于虫族。
根据官方公布的数据,TLO在2018 WCS Circuit排名:44。

国内关于TLO的资料,不少都是几年前的对战,现在TLO应该已经在自己职业生涯的末期,可以算是一位久经沙场的老将。
MaNa是一位出生于波兰的职业星际2选手,原名Grzegorz Komincz,1993年12月14日出生,目前也效力于Liquid。
与TLO相比,MaNa是一个正值当打之年的选手。
而且,他更擅长的是神族。尽管他打出GG的速度更快……
MaNa去年获得WCS Austin的第二名。根据官方公布的数据,他在2018 WCS Circuit排名:13。

MaNa和TLO和AlphaStar的对战,发生在去年12月。地点在伦敦,就是DeepMind的总部。这不禁让人想起当年AlphaGo的故事。
AlphaGo名不见经传时,也是悄悄把樊麾请到了伦敦,然后把樊麾杀得有点怀疑“棋”生。然后开始向全世界公布突破性的进展。
TLO和MaNa,应该就是星际2界的樊麾了吧。
第三个是AlphaStar的教父:Oriol Vinyals。
他是DeepMind星际2项目的核心负责人。我们在此前的报道里介绍过他。1990年代,十几岁的Oriol Vinyals成了西班牙《星际争霸》全国冠军。
他之所以玩这款科幻策略游戏,是因为比其他打打杀杀的游戏更需要动脑子。维纽斯说:“没上大学之前,这款游戏就让我在生活中怀有更强的战略思维。”
Vinyals的战略思维的确获得了回报:在巴塞罗那学习了电信工程和数学之后,维纽斯去过微软研究院实习,获得了加州大学伯克利的计算机博士学位,接着加入谷歌大脑团队,开始从事人工智能开发工作,然后又转入谷歌旗下DeepMind团队。
他又跟“星际争霸”打起了交道。
但这一次不是他亲自玩,而是教给机器人怎么玩。在人工智能成为全球最优秀的围棋选手后,星际成为了下一个攻克目标。
AI打星际的意义
早在2003年人类就开始尝试用AI解决即时战略(RTS)游戏问题。那时候AI还连围棋问题还没有解决,而RTS比围棋还要复杂。
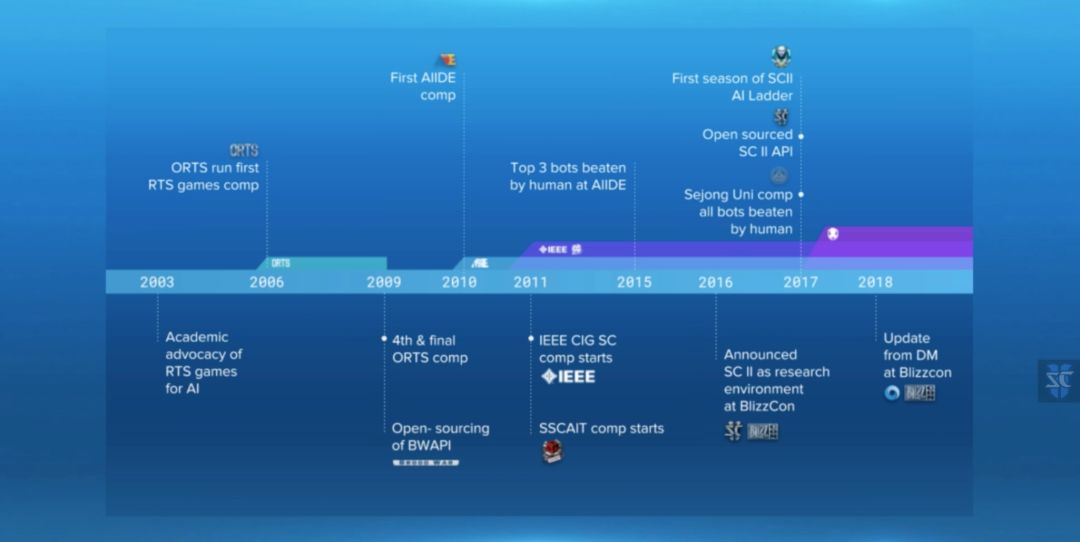
直到2016年,“阿尔法狗”打败了李世石。DeepMind在解决围棋问题后,很快把目光转向了《星际2》。
与国际象棋或围棋不同,星际玩家面对的是“不完美信息博弈”。
在玩家做决策之前,围棋棋盘上所有的信息都能直接看到。而游戏中的“战争迷雾”却让你无法看到对方的操作、阴影中有哪些单位。
这意味着玩家的规划、决策、行动,要一段时间后才能看到结果。这类问题在现实世界中具有重要意义。
为了获胜,玩家必须在宏观战略和微观操作之间取得平衡。
平衡短期和长期目标并适应意外情况的需要,对脆弱和缺乏灵活性的系统构成了巨大挑战。
掌握这个问题需要在几个AI研究挑战中取得突破,包括:
博弈论:星际争霸没有单一的最佳策略。因此,AI训练过程需要不断探索和拓展战略知识的前沿。
不完美信息:不像象棋或围棋那样,棋手什么都看得到,关键信息对星际玩家来说是隐藏的,必须通过“侦察”来主动发现。
长期规划:像许多现实世界中的问题一样,因果关系不是立竿见影的。游戏可能需要一个小时才能结束,这意味着游戏早期采取的行动可能在很长一段时间内都不会有回报。
实时:不同于传统的棋类游戏,星际争霸玩家必须随着游戏时间的推移不断地执行动作。
更大的操作空间:必须实时控制数百个不同的单元和建筑物,从而形成可能的组合空间。此外,操作是分层的,可以修改和扩充。
为了进一步探索这些问题,DeepMind与暴雪2017年合作发布了一套名为PySC2的开源工具,在此基础上,结合工程和算法突破,才有了现在的AlphaStar。

除了DeepMind以外,其他公司和高校去年也积极备战:
4月,南京大学的俞扬团队,研究了《星际2》的分层强化学习方法,在对战最高等级的无作弊电脑情况下,胜率超过93%。
9月,腾讯AI Lab发布论文称,他们构建的AI首次在完整的虫族VS虫族比赛中击败了星际2的内置机器人Bot。
11月,加州大学伯克利分校在星际2中使用了一种新型模块化AI架构,用虫族对抗电脑难度5级的虫族时,分别达到94%(有战争迷雾)和87%(无战争迷雾)的胜率。
下一步
今天AI搞定了《星际2》,DeepMind显然不满足于此,他们的下一步会是什么?
哈萨比斯在赛后说,虽然星际争霸“只是”一个非常复杂的游戏,但他对AlphaStar背后的技术更感兴趣。其中包含的超长序列的预测,未来可以用在天气预测和气候建模中。
他还透露将在期刊上发表经过同行评审的论文,详细描述AlphaStar的技术细节。一起期待吧~
近期精选





