百万骑手“火速送达”背后的人工智能应用实践!
大部分人都点过外卖,现在外卖成了中国人吃饭的另一种方式,今天分享的主题是人工智能在 “饿了么” 的应用实践。

今天的内容主要分为三个部分:
“饿了么” 简介。
AI 在“饿了么” 的应用场景。
运筹优化与机器学习的应用实例。
关于“饿了么”
大部分人都点过外卖,现在外卖成了中国人吃饭的另一种方式。点外卖是什么样的量级,说起来吓大家一跳。
中国最大领域是电商,淘宝、京东,其次就是出行行业,滴滴、UBER,紧接着是共享单车,这几家公司加起来是一天两三千万的订单量左右。
而在外卖行业,到今天为止已经每天达到 2500 万单,可以看到这个行业正在飞速发展。
为什么数据和算法能起到那么大的作用?因为我们都知道在“互联网+”的背景下,有这么大的订单量,至少是在数据行业我们有非常多事情要做。
2500 万订单量里面 “饿了么” 是什么样的场景?我们把手机 APP 打开,可以找到自己喜欢的餐厅,大家选择一个餐厅,选择喜欢吃的东西,这个行为虽然是点一个菜,但是实际上跟大家在淘宝买衣服和在携程买机票是一样的。
前面是电商交易平台所交易的食品,现在不仅是食品,还可以在上面买鲜花、买药品,同时还有本地的帮买帮送等等。所以电商只是第一部分,电商到了什么规模?
“饿了么”C 端注册用户 2.6 亿,B 端商家目前已经是 130 万,每年是千万级别的定单情况,这个是我们外卖行业的一部分,基于电商交易平台。

第二部分就是大家可以看见上图中骑手小哥拿着箱子,要么走路或者骑着电动车,这就是本地物流平台。
为什么要强调本地,因为我们行业的特殊性跟其他物流行业不一样。他们几天时间到达,我们这个行业的本地物流是希望 30 分钟能送到用户手里。
所以我们在设计这个架构的时候就有很大的挑战,这个有一些不同,一会儿讲到算法模型的时候就清楚了,我们是做一些本地的物流,所以时间上有非常严格的限制。
到今天为止,我们配送员已经达到 300 万,平均每天在任何时刻,全国都有 30 万到 40 万的骑手活跃线下,随时准备接单。这个跟滴滴是一样的运营模式,现在已经覆盖了全国 2 千多个城市。
AI 在“饿了么”的应用场景
外卖这个行业为什么需要人工智能呢?作为本地生活的平台,我们都知道衣食住行是非常需要的。
在每个方向都有很多大的商家,他们在技术上的挑战有什么不同,一定取决于他们的业务形态。

首先是淘宝,淘宝是大家在线上买东西最常用的一个平台,里面主要是以用户和商户为主,线下是同城当日达,更多定单是走开放平台。
大家下了定单,东西送到大家的手里,这个是三通一达。也可以是菜鸟或者顺丰,它们是开放平台,最重要的一点是时效性,通常以天来计算,超时不会有所谓的赔偿,这个是淘宝的情况。
我们再看携程,它可以定旅馆、酒店,线上以用户和商户为主,不会有线下的订单。
跟外卖行业特别接近的就是滴滴,从业务形态来讲,像滴滴这类出行和外卖是非常接近的。
滴滴线下线上始终是用户和司机,定单形式也是众包的形式,要么通过加盟商,要么通过司机网上注册来承担运力,超时也不会惩罚司机。
因为谁也不会预料到会不会出现车祸,这个时效没有保证,所以说它和饿了么是极其相似的。
最后提到 “饿了么” 和外卖行业。首先线上以用户和商户为主,线下订单部分比较多,蓝色骑手有一部分是 “饿了么” 的员工,就是自营,还有团队和加盟商的形式,当然还有一种是众包。
比如说今天开一个会,下午还有四个小时,我可以送几单,这是一种众包的形式。
时效性是以分钟来计算的,我们的目标在很长时间已经做到了,全国平均半个小时可以把订单送到手里。
还有超时赔付,如果 30 分钟之后超过 10 分钟没有送到,就有一个红包的赔偿,超时赔付的压力是比较大的,不过这样做对客户来说算是一种服务不足的补偿。
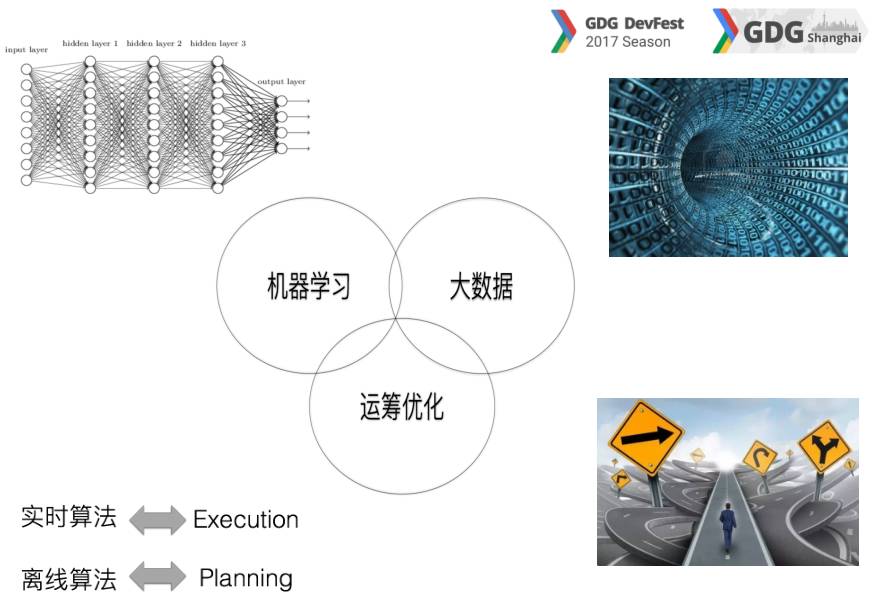
根据上面所述,我们进入了一个大的框架,就是在外卖这个行业是三个大框架,一个是机器学习,一个是大数据,再一个运筹优化跟机器学习也是密不可分的。
讲到运筹优化,大数据作为运筹优化的基础起到了非常关键的作用,现在大家看这个图挺有意思,我会多花两分钟讲一讲在业务中的算法问题,大概有三个层面。
底层的外卖行业希望 30 分钟把食物送到用户手里,不可能送到二十或者三十公里之外,除非你会飞,否则半个小时不可能送 10 公里。
基于这种情况,所有行业都是基于当前打开 APP 的位置,定位可能 3 公里或者 5 公里的半径,LBS 保证在运营商网络做各种推荐或者搜索为基础,再往上两层就是机器学习和优化,所以具体讲一下这三部分。
交易
如下图,大家可以看到中间这个模块是用户商户分层,推荐搜索以及智能补贴,这几个大的方向是任何电商都必须做的。
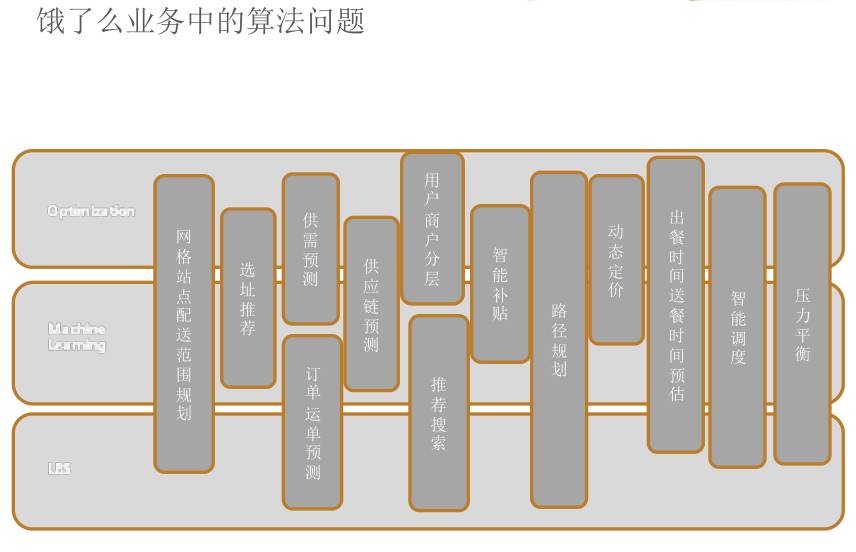
在有很精细的用户画像体制上,我们希望对用户和商户的生命周期做严格的管理,在这个基础上我们做相应的推荐、搜索、补贴。
比如说有一个用户进入沉睡期,我们会通过一定的方式对客户进行刺激。
线下
当交易行为发生时,我们希望 30 分钟将外卖送到用户手里,这里面涉及到机器学习的规划,我会详细讲智能的调度,也会详细讲到出餐时间和送餐时间的预估,以及动态定价等这几个模块。
智能调度是调度的一部分,我们这 30 分钟包括了准备的时间和路上的时间,甚至保证了送到楼下,等电梯到你手上的时间等等。所以这 30 分钟有很多不可预估的东西。
那么压力平衡是什么意思?大家都知道,线上交易和我们物流是矛盾的,对于线上交易来说我们当然希望订单越多越好,我们希望有上千万的用户几秒钟一下子全进来。
但是 30 分钟内把订单全部送出去,这个是不太可能一下子解决的问题,为了达到压力平衡,就要保证交易和物流、配送等保持平衡,既达到交易质量,也不损失用户的积极性。
底层
讲到交易和线下这两个之后就是一些底层的东西,现在让我们看上面那张图,左边包括选址推荐等等。
刚才讲到配送是本地,当一个商家定下准备配送的地方就会画一个圈,比如说我送一个圆圈或者六边形,这个不是随便画的。
首先有可能这个地方是高速路或者高架桥,不是每个人的平台都是一样的,有的用户也有可能老是定便宜订单,我们在网格和站点规划的时候会考虑所有因素。
这个涉及很多运筹优化的问题,最后一个例子就会讲到选址和网格规划的问题。
下面简单讲一下我们在人工智能方面所有的一些尝试,这对我们业务是非常重要的。
运筹优化与机器学习的应用实例
这一部分我会分两种来说:
机器学习的应用案例。
机器学习应酬优化的案例。
案例 1 : 出餐时间预估
第一个是出餐时间的预估,我在这里用滴滴做比较,什么是等待时间预估。
比如我们在滴滴场景下下了一个订单,说我想去浦东机场,它会告诉你这个车离这里两公里,3 分钟会到,这个3 分钟就是等待时间预估。
“饿了么” 相当于下了一个单,大概 20 分钟才能做好,我们希望的是来的早不如来的巧。
作为我们平台的骑手刚好在 20 分钟就到,如果早了骑手等在那儿是浪费,但是去晚了,就可能订单超过了时间。
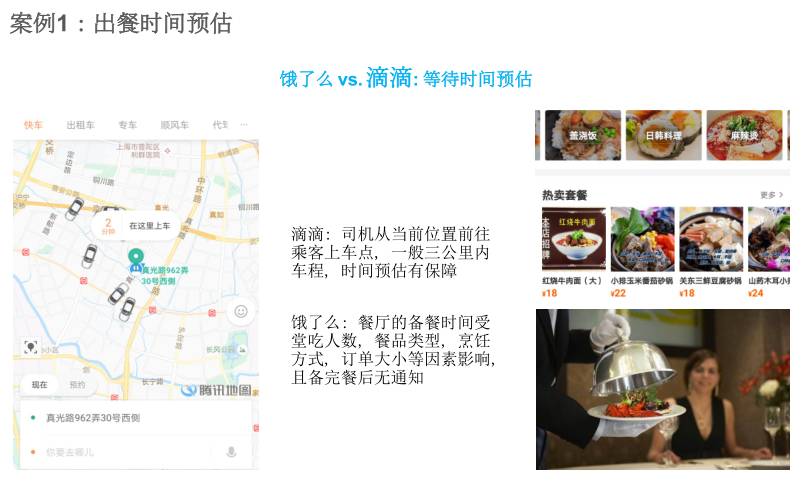
这个出餐时间的准确性是关键,当订单完成之后,怎么知道订单花多长时间完成?
这个餐厅受很多因素的影响,餐厅的备餐时间和食堂吃的用户数、餐品类型、烹饪方式、订单大小等且备完餐后无通知。
比如说餐厅客户特别多,平时可能 5 分钟做出来,可能人多了就 5 分钟做不出来。
还有产品品类的问题,甚至包括一天的天气各种原因,包括餐厅的出勤率,餐厅厨师请假突然少了几个人,这些都是造成预估不准确的原因之一。
我们想过为什么不让餐厅做好了后直接告诉我们,然后我们就去取餐,这个理论是可行。
但是大家想象一下在餐厅场景里面,厨房是什么样的情况?你想象一下一个厨师满手都是油,出来点一下这个订单好了,然后看下一个订单,这个是很难想象的事情,我们没有得到这方面的数据。
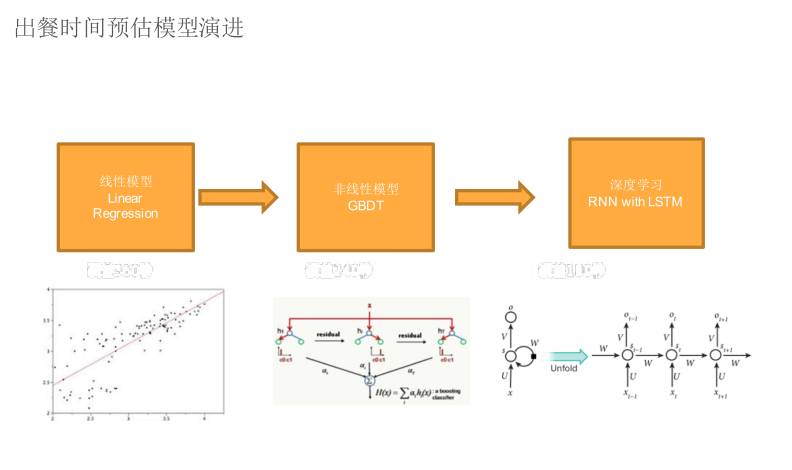
这个是一个前提,我们的解决方案毫无疑问是机器学习,最简单版本就是线性模型。
一开始效果不是特别好,但逐渐演进到后面的 GBDT ,在场景下做到平均不是特殊平均,加上出餐时间是 10 分钟,我们可以固定 7 分钟到 13 分钟,这个准确率比较高。
我强调是平均,因为有很多特殊场景,如果厨师出了什么事情,我们也不知道,因为机器学习只能根据过去的事情来预测将来。
在突发事件有一些产品的方案,比如说看到这个餐厅出餐量和订单量并没有呈线性的增长,前面出现了堵塞情况,我们根据数据对平台进行实时调整。
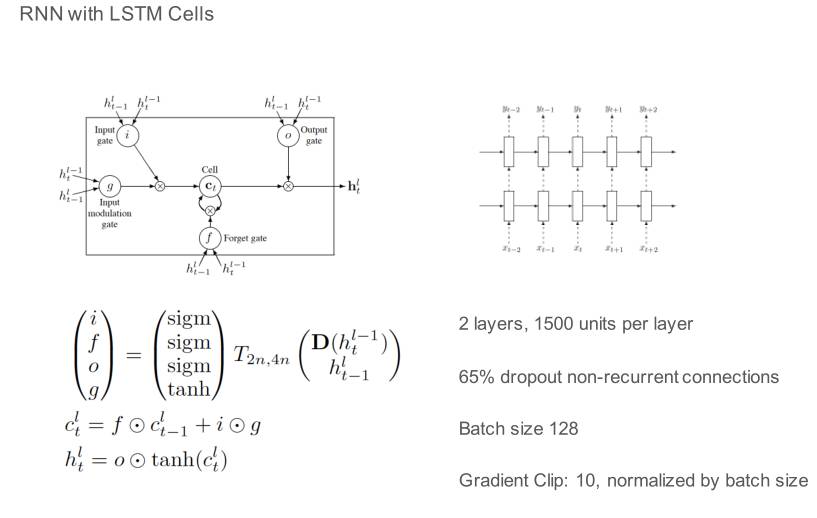
最后我们的方法是深度学习,用的是 LSTM。我们通过时间相关性把预测做的更加准确,毫无疑问出餐时间一定会跟过去订单有关系,这个不用解释。
但是为什么跟未来有关系,我们预估未来 3 到 5 分钟有新的订单,但是跟现有的订单有共同之处,有可能是同样的菜品,有可能是共同的地方,同样的菜品对厨房是一个订单,可以把菜一起做。
我们学到了,通过这个模型也可以捕捉这些特征,对订单分配有一定的帮助,同样对订单打包也有一定的帮助。
案例 2 :行程时间预估
行程时间的预估就是当订单完成了以后,骑手把订单拿到手里,他会跑到办公室或者家里也好,这个是行程时间的预估。
例如滴滴从 A 点到 B 点,交通方式肯定就是车,而且有大量的地图数据,像高德或者谷歌地图或者百度地图,这些数据会实时上传给服务器。

在这种交通情况预测已经是比较准确的,但是相对 “饿了么” 场景远远没有那么多的信息。
首先骑手可能步行,走电梯、走上下楼梯、骑电动车或者换交通工具,这个直接造成了我们的数据搜集是极不准确的,还有一点在楼宇内的交通复杂,这个数据很难获取。
我们上班的时候,餐厅和顾客都是在大楼里面,大楼里面没有 GPS 信号或者信号不大好,我们收到的数据或者定位误差高达几百米。
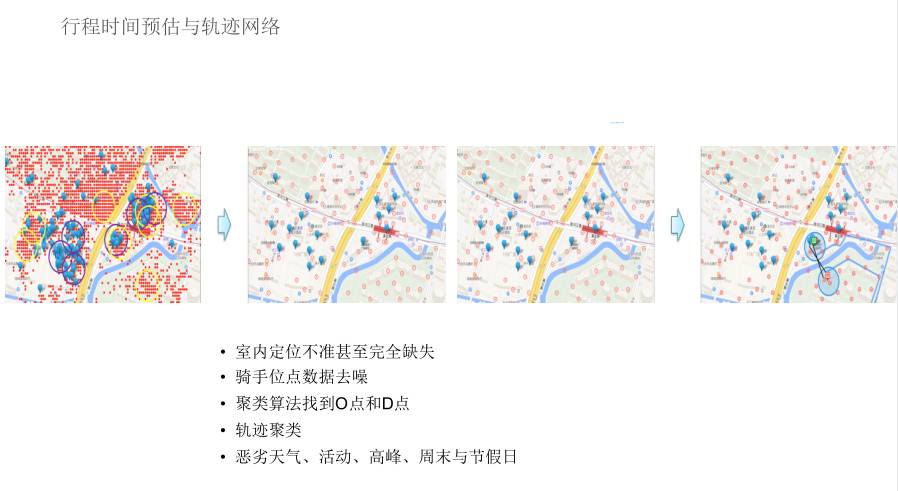
所以提前时间预估,我们需要把轨迹建立起来,因为时间预估在高德地图或者腾讯百度地图是基于历史数据的。
我们第一步做的是历史数据清洗,室内定位不准甚至完全缺失,这个情况下我们想了各种各样的办法,我们用 WiFi 信号,GPS 信号或者大家互相定位,最大程度减少定位缺失的问题。
其次,即使定位有了,它的位点也是有 GPS 轨迹的,也有很多的噪音,所以需要去噪。我们通过定位的算法把相关的时间,把 O 点和 D 点合起来,最后进行轨迹聚类。
案例 3 :智能分单
滴滴与我们的分单难度不一样,滴滴场景下要配一个司机,最多接两三单。
在 “饿了么” ,一个骑手一个包同时背 5 到 10 单,而且订单之间有时间限制,涉及大量的时效要求。

我讲两个方案,第一个方案是路径规划的问题,很传统的 VIP。
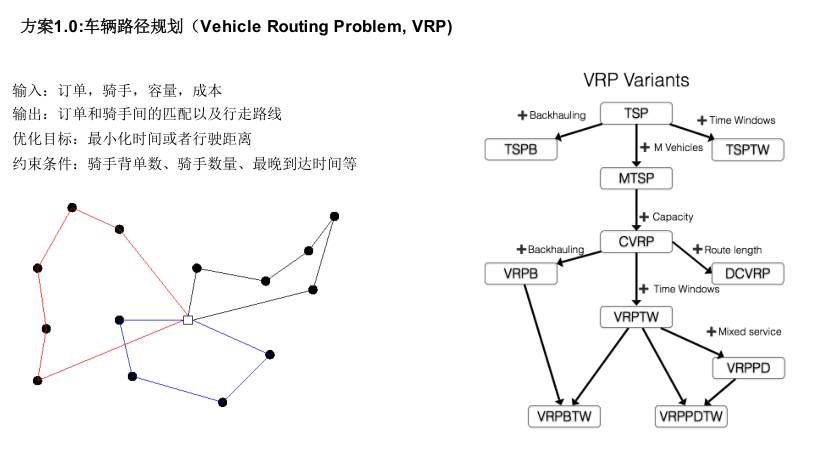
当你给一个订单,在骑手容量和成本固定的情况下,我们需要找到匹配的线路,每个订单承诺时间是不一样的,就是保证不能超时。
默认模式下, 一个骑手可以同时送 5 到 10 单, 每单都有严格的时效要求, 并且订单在午间高峰爆发式增加。
方案 1 就是车辆路径规划:
输入:订单,骑手,容量,成本。
输出:订单和骑手间的匹配以及行走路线。
优化目标:最小化时间或者行驶距离。
约束条件:骑手背单数、骑手数量、最晚到达时间等。
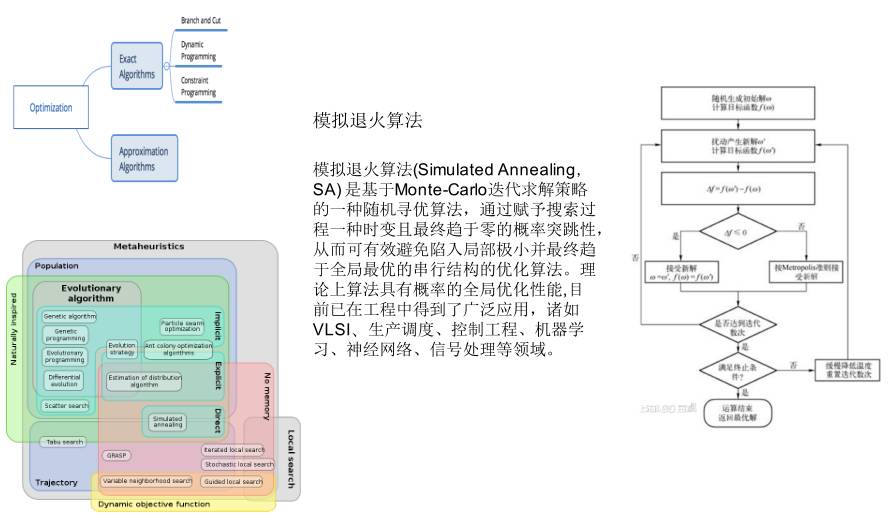
我们用了模拟退火算法,模拟退火算法 ( Simulated Annealing,SA ) 是基于 Monte-Carlo 迭代求解策略的一种随机寻优算法。
通过赋予搜索过程一种时变且最终趋于零的概率突跳性,从而可有效避免陷入局部极小并最终趋于全局最优的串行结构的优化算法。
从理论上来说这个算法具有概率的全局优化性能,目前已在工程中得到了广泛应用,诸如 VLSI ,生产调度、控制工程、机器学习、神经网络、信号处理等领域就是用它来做订单的分配。
但是最后结果不是特别好,因为时间预估存在不准备性,在路径规划的时候,先走 A 单还是 B 单,在时间一旦出现误差的情况下,这个路径规划会非常差。

最后用的是第二个算法,也是一种基于大量函数的组合算法。
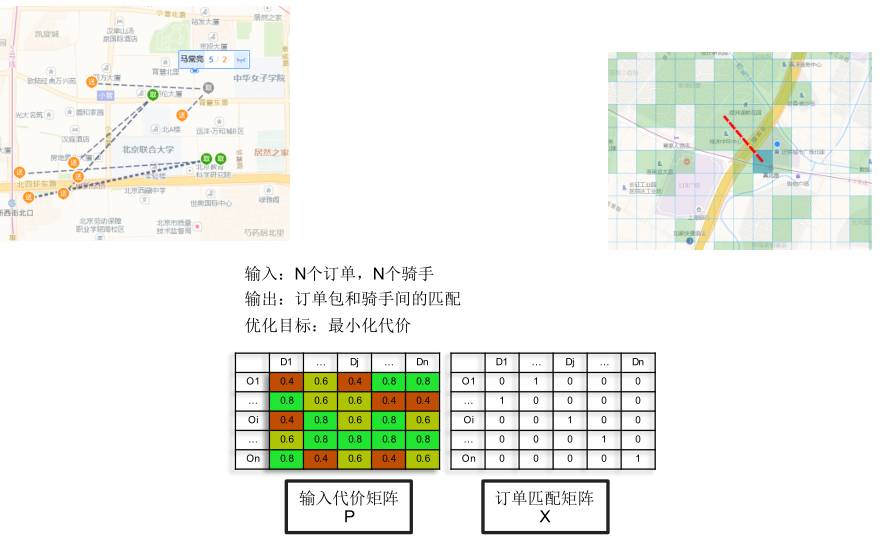
左下角是个矩阵,每一行是一个订单,每一列是一个骑手,我们希望通过一些规则和一些机器学习的算法算出来,右边是一个定单匹配的结果。
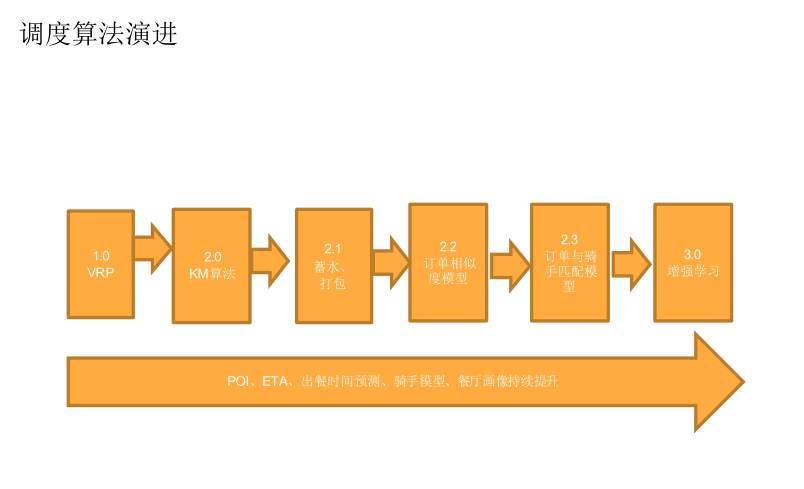
最优匹配就是 KM 算法,调度算法的演进最早是 VRP。
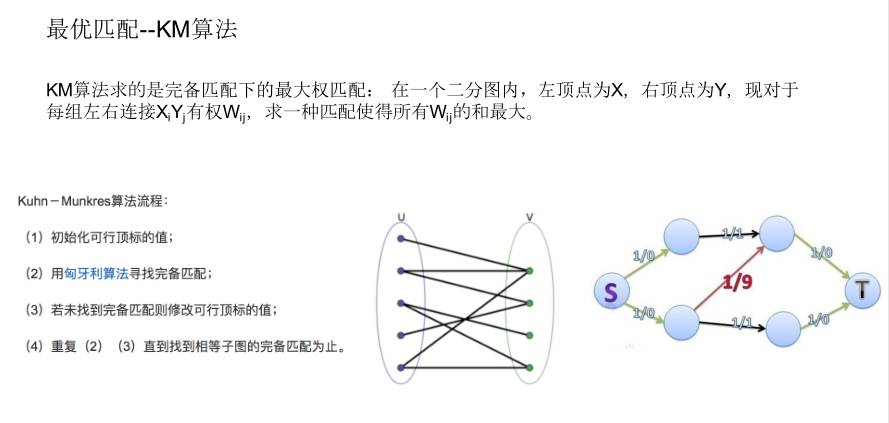
后来采用的是 KM 算法,但是这个基础框架界定了以后,还有很多工作需要做。
订单实际上有相似性,因为订单是可以打包的,一个人稍微等几分钟,也许这个订单出来跟那个订单很相似的性质,就是去同一个地方,就可以把订单给同一个人拿走。
所以订单打包和吸水是我们做的第一件事情,但是订单靠什么规则在高峰期和非高峰期的时候是不一样的,这里存在两个方向的路和两个方向的夹角不一样的地方,所以定单匹配模型是在 2.2 版本之上做出来的。
用机器学习通过历史数据来训练,在这里我们也碰到一些挑战,由于在不同的站点配送员习惯不一样,我们推广的时候会遇到一个问题,在 A 站点大家觉得是 OK,但是在 B 站点不行。
我们现在做到千站千面的东西,根据类似的站点历史过去分担一些情况,我们把这些模型用来做训练,做到类似的站点它有类似分单的方式。
所以不会出现说你特别不喜欢这个分单的方式,多多少少有一点类似性,后来做到了 2.3 这个版本。
现在做的版本就是增强学习,我们根据实时的情况来进行动态地调整。
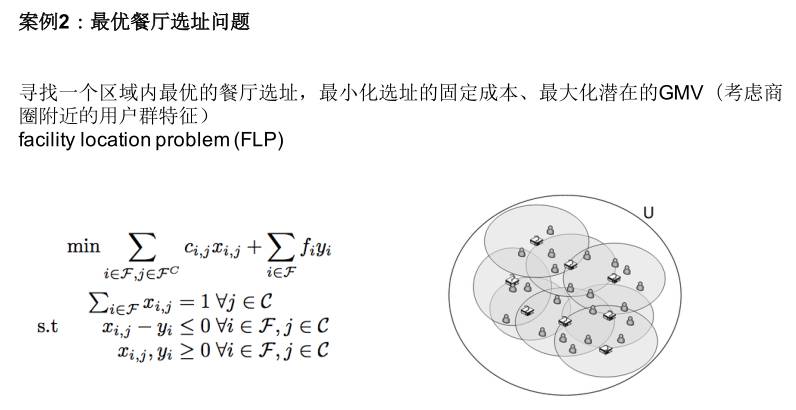
餐厅选址就不详细讲了,我们也和商家开始合作开一些餐厅,我们都希望选最好的地方,餐厅覆盖最多的用户,菜品不一样,用户群不一样,所以这个选址是很重要的。
总结

我做机器学习十几年,个人感受,工作挑战是来自于基础数据的完整性和准确性。
刚才讲到数据不准确,餐厅不规则的情况,我们无法知道一些准确的情况,我们花了大量时间来做基础数据的调整。
第二点我讲到算法的提升和对人的行为的理解比较重要,因为在外卖行业都需要人去执行,以前人工分配通过打电话,有大量沟通在里面。
现在机器一下子分摊了,他们难以理解,而且机器考虑全局最优而不是局部最优,人是做不到这点。
在算法提升和产品运营综合起来,才能把这个事情最后推下去让大家形成习惯。
第三点优化算法与机器学习在我们行业是相辅相成的,不仅是机器学习,更重要的是我们在这么短时间怎么样把人力分布最好,在最少的时间情况下把订单完成。
微信后台回复关键词“饿了么”,即可下载完整版PPT资料
作者:张浩
编辑:陶家龙、孙淑娟
来源:转载自GDG微信公众号,本文为作者在上海GDG DevFest 2017上的演讲。

张浩,饿了么技术副总裁,曾任滴滴研究院高级总监,美国 Uber 大数据部、LinkedIn 搜索与分析部资深数据科学家、Microsoft 语音识别组高级数据工程师,现负责饿了么人工智能与大数据建设,带领团队将机器学习应用在物流调度、压力平衡、推荐搜索等场景,通过数据挖掘建立完整的数据运营体系,提高运营效率,用数据和智能驱动业务发展,拥有十余年机器学习、数据挖掘、分布式计算的实际经验。

精彩文章推荐:




