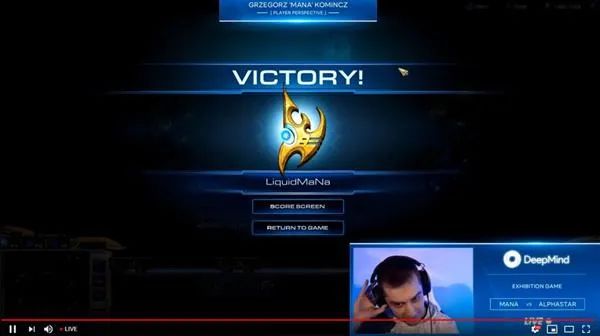
Deepmind AI在《星际争霸2》血虐99.8%人类,登顶宗师段位
新智元报道
新智元报道
来源:PC Gamers等
编辑:啸林
【新智元导读】虽然IBM一直在做与人类辩论的AI,Deepmind团队一直执着于创造在游戏中血虐人类玩家的AI。这是为什么?新一代AI何以登顶星际争霸2战网天梯宗师?「新智元急聘主笔、高级主任编辑,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」



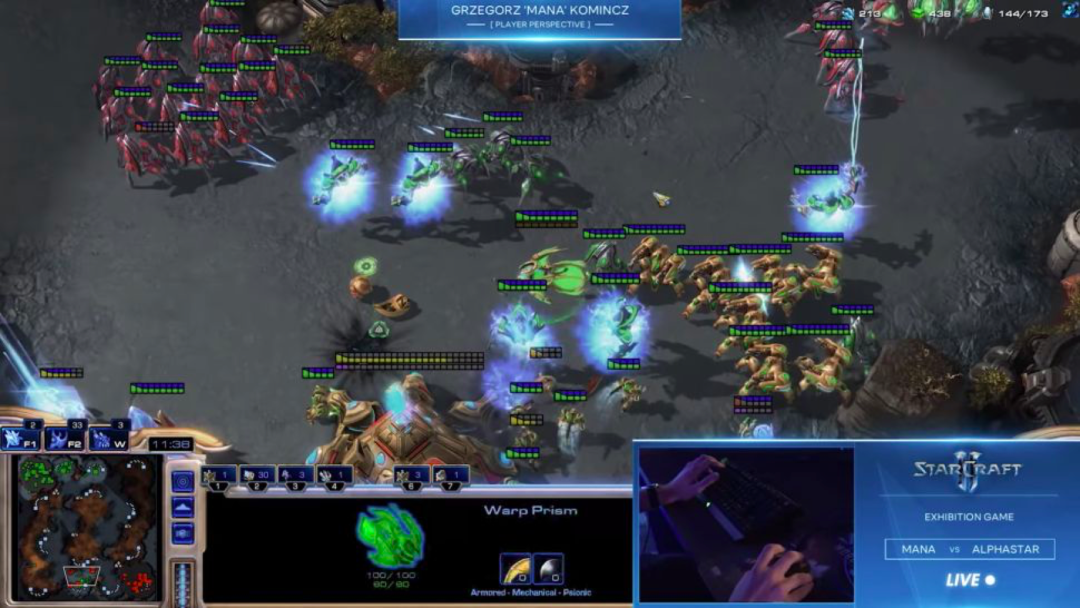
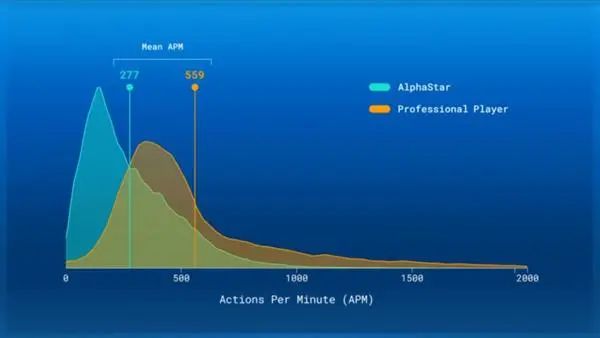




AI研究人员如何应对《星际争霸2》中的所有新手
更多关于AI玩星际争霸2的硬核技术介绍,请移步:
新智元:AlphaStar 称霸星际争霸2!AI史诗级胜利,DeepMind再度碾压人类

登录查看更多
相关内容
Arxiv
6+阅读 · 2018年1月21日


相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2018年1月21日