大数据和云计算技术周报(第107期)
导语
“大数据” 三个字其实是个marketing语言,从技术角度看,包含范围很广,计算、存储、网络都涉及,知识点广、学习难度高。
本期会给大家奉献上精彩的:spark、知识图谱、MongoDB、全链路压测、ES、数据库原理、redis、Kylin、数据。全是干货,希望大家喜欢!!!
#大数据和云计算技术社区#希望通过坚持定期分享能帮助同学在大数据学习道路上尽一份微博之力。相信长期坚持认真阅读周报的同学,在技术的道路上一定会日益精进!感谢编辑们的长期坚持!也请同学们继续打赏,支持社区,支持编辑们持续奉献高质量知识!
#大数据和云计算技术社区#长期招募有兴趣参与社区编辑和运营的同学,欢迎扫描文末二维码联系(参与社区工作,收获知识和进步,还有红包哦)。
特别提醒,文末有惊喜!
以下是正文,限于众编辑水平有限,不保证大家都喜欢。(如果链接不能点开 请用二维码 谢谢)
1Spark
Spark应用中,Shuffle服务的可靠性和性能直接影响了Spark应用的执行效率,来自Facebook的Brian Cho与Dmitry Borovsky在今年4月份旧金山举行的Spark AI峰会上,分享了他们为Spark/Hive Shuffle优化做的工作,这些工作中的很大部分已经应用于Facebook的大数据平台生产环境,对于超大规模的Spark数据处理优化,有一定的参考借鉴价值。
Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。
https://mp.weixin.qq.com/s/crDp5SvrkbnZ7DPQ50tpIA
2Elastic
使用ignore-malformed功能解决数据类型不一致无法写入问题
https://www.elastic.co/guide/en/elasticsearch/reference/current/ignore-malformed.html?nsukey=ncpozAvRJ%2BukDWJfqu9E1Qrme7lz294tqUX78G2VjntuwepgXfEBl612xi%2BVh%2B4nzoeMTkan330f6ANw7mgEHTmbDmRzqFYIjECV2eY8EwyckVdWG5CaABMC0rc9X7z7Rdv51H5KfIXbpjCXHMaDnNIH9Z9cskj5%2Bs7V%2FUdoaxh8vwUOgVLq6%2BQ7%2F2yVPyUcTTjBSQmHUAbY6ZA16SNu%2Bg%3D%3D

3ProxySQL
ProxySQL是一个高性能的MySQL中间件,拥有强大的规则引擎。
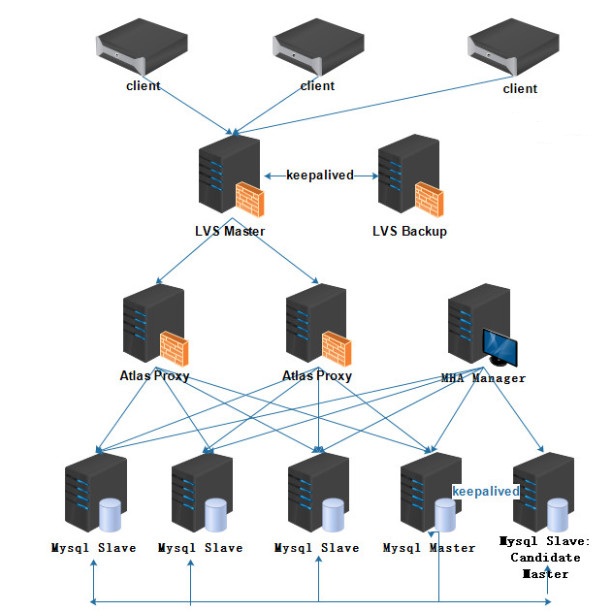
ProxySQL提供强大的路由规则。当应用程序自身不支持读写分离时,DBA可以通过配置路由规则为应用程序提供透明的读写分离,使用Keepalived + ProxySQL + Orchestrator为主从提供高可用时,能够有效的避免keepalived + 双主结构 由于keepalived脑裂而造成数据被写错乱的痛点。
https://mp.weixin.qq.com/s/RwupNscnTKJgLuIfMqda3A4数据库
X-Engine团队撰写的论文"X-Engine: An Optimized Storage Engine for Large-scale E-Commerce Transaction Processing",详细讲述了阿里在数据库存储引擎上所做的原创性工作,今年早些时候已经被SIGMOD'19 Industrial Track接收
https://mp.weixin.qq.com/s/XkG7ikHzf3IdEltv3YmvSA
5MongoDB
本文讲述了MongoDB WiredTiger存储引擎中的底层时间戳的实现使得从节点读取不会被复制更新中断,复制回滚,保证多文档ACID事务正确性。
http://www.mongoing.com/archives/26700

6系统架构
在创业公司,没有大公司那些完善的基础设施,需要我们从开源界,从云服务商甚至有些需要自己去组合,去拼装,去开发一个适合自己的组件或系统以达成目标。
https://mp.weixin.qq.com/s/CzZZcjkiyLh7k6o-3gP3Ag
7知识图谱
本文介绍将知识图谱作为辅助信息引入到推荐系统中可以有效地解决传统推荐系统存在的稀疏性和冷启动问题.
https://mp.weixin.qq.com/s/ZYLM3pt5w2gJXr0VUbNXSA
8Data
如今,大数据如火如荼,抛开数据谈大数据服务就是瞎扯,没有数据作支撑的大数据平台就是一个空壳,那这些数据的来源在哪呢?
9Kylin
Apache Kylin 在今年 4 月 18 日发布了 3.0.0 Alpha 版本,本文主要围绕 Release notes 内提到的三个功能展开介绍,即:基于 Curator 的作业调度器,使用 Apache Livy 提交 Spark 任务,实时 OLAP。
https://mp.weixin.qq.com/s/qbRXqCEIW70kXm2RPxeu5Q
10Redis
本文首先通过Redis到底能存储多少个键值对,引出Redis的Hash表实现方式(数组链表)、扩缩容等原理,最后通过一个开脑洞的思考探讨,分析了各种利弊,最终讨论Redis到底存储多少个键值对会比较好(最多千万级别
https://mp.weixin.qq.com/s/Y4DARDPPSkIpme4psMT8Nw11全链路压测
通过对压测实施的具体动作做统一的梳理,在压测各个阶段推进标准化和自动化,尽力提升全流程的执行效率,最终达到常态化的目标
https://mp.weixin.qq.com/s/qeHHTjhEeZ-VskL_8ac0Tg
11开心一刻
程序员爱情观:爱情就是死循环,一旦执行就陷进去了;爱上一个人,就是内存泄漏–你永远释放不了;真正爱上一个人的时候,那就是常量限定,永远不会改变;女朋友就是私有变量,只有我这个类才能调用;情人就是指针用的时候一定要注意,要不然就带来巨大的灾难。
致谢:
周蓬勃、王在道、孙亚飞、冯艺帆、陈少军、邓开表、张少华、薛述强、刘彬、刘超、廖程鹏、董言、吕西金、朱洁、蓝随、黄文辉、郭飞
猜你喜欢
大数据和云计算技术周报(第56期)
加入技术讨论群
《大数据和云计算技术》社区群人数已经6000+,欢迎大家加下面助手微信,拉大家进群,自由交流。

喜欢QQ群的,可以扫描下面二维码:
欢迎大家通过二维码打赏支持技术社区(英雄请留名,社区感谢您,打赏次数超过108+):