AI新领地—打通图像增强和视觉识别的“任督二脉”
众所周知,深度学习算法已经占领很多计算机视觉任务的制高点,在图像识别等任务上的精度已然超过了人类的平均水平。然而,绝大多数深度学习算法只有在高质量的图像上才能取得高性能。实际图像采集过程中,存在各种降质因素,导致图像质量和视觉效果下降,深度学习算法的性能也随之降低。
研发和评估新的机器学习算法,增强图像质量的同时,又可以提升物体识别精度,打通图像增强和视觉识别的“任督二脉”,显得尤为重要。小编带来的这篇论文《Bridging the Gap Between Computational Photography and VisualRecognition》也许会给我们带来很多启示,这篇论文的主要创新点在于:
1. 提出了
http://www.ug2challenge.org/dataset18.html,从地面、无人机、滑翔机三个场景拍摄了理想情况和存在多种图像降质情况的大量视频,并且对其中的多数视频帧进行了标注,包括物体的包围框和大类(super-classes)标签;
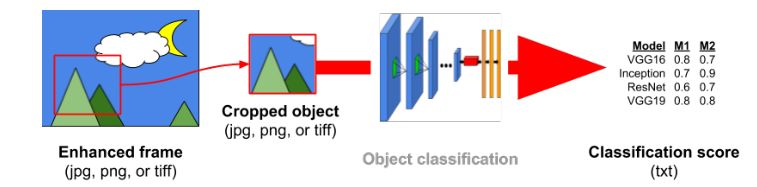
2. 提出了一套新的图像增强评价体系,既可以从人的主观角度评价图像增强效果,又可以对增强后的图像进行视觉识别任务进行评估;
3. 在
4. 介绍了CVPR2018
5. 图像增强和视觉识别应该关注的研究趋势,在非理想和非受控的环境中采集图像,可以对场景进行更好地理解。
一套新的图像增强评价体系
(A New Evaluation Regime for Image Restoration and Enhancement)
1. 图像增强以更好地适应人的视觉感观(Enhancement to Facilitate Manual Inspection)

2. 图像增强来提升物体识别精度(Enhancement to Improve Object Recognition)
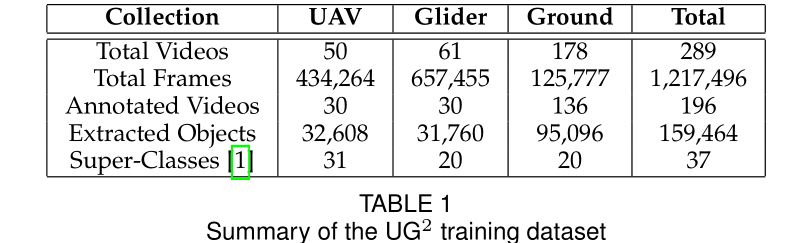
UG2(UAV,Glider and Ground)数据集
从地面(Ground Video Collection)、无人机(UAV Video Collection)、滑翔机(Glider Video Collection)三个场景拍摄了理想情况和存在多种图像降质情况的大量视频,并且对其中的多数视频帧进行了标注,包括物体的包围框和大类(super-classes)标签。

6种新的图像增强算法以及评价
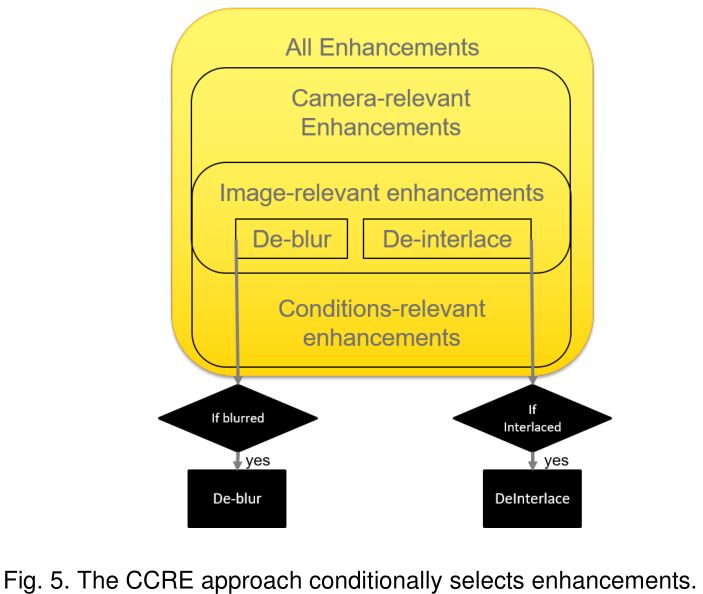
1. Camera and Conditions-Relevant Enhancements (CCRE)
主要根据不同的采集环境参数和相机硬件参数,创建一个增强参数集合,为每张图像选择一个合适的增强参数子集(a smaller subset of enhancements)来进行图像增强。
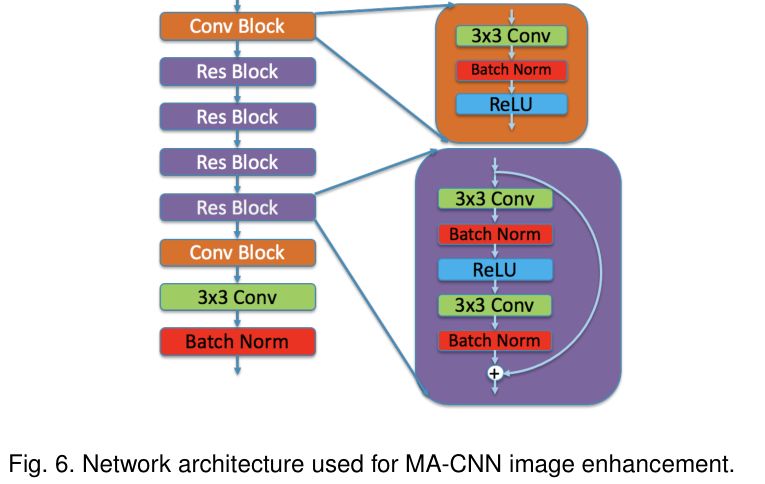
2. Multiple Artifact Removal CNN (MA-CNN)
主要思路是通过一个独立的网络模型解决blur\noise\compression等多种问题,MA-CNN是一个全卷积网络(fully convolutional neural network),网络中使用了短连接(skip-connections)。
3. Cascaded Degradation Removal Modules (CDRM)
主要思路是使用级联的降质去除模块,包括对数据来源进行分类、使用DeblurGAN\RRN-SR\直方图均衡化等模型和操作。
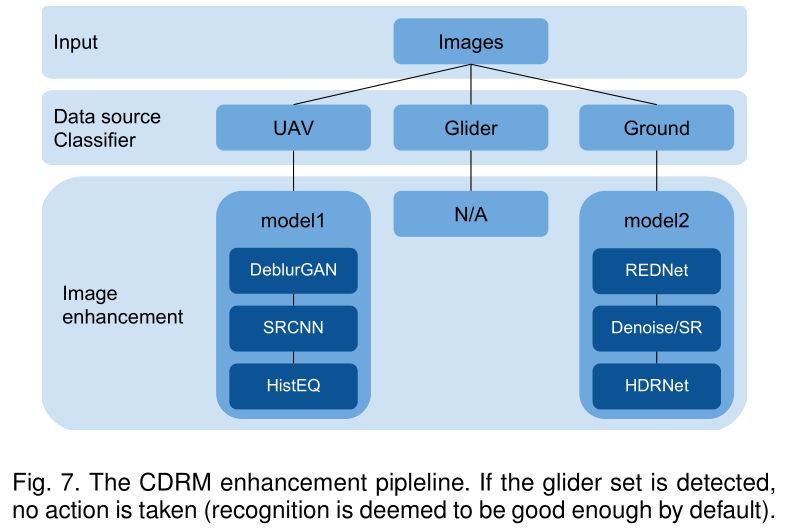
4. Tone Mapping Deep Image Prior (TM-DIP)
主要思路是使用深度图像先验,对来自同一个传感器的数据进行图像先验建模。
5. Satellite Images Super-Resolution (SSR)
主要想法是使用卫星图像集进行训练。

6. Style-Transfer Enhancement Using GANs (ST-GAN)
主要是参考借鉴了CycleGAN和LSGAN的思路。
实验结果与分析
1. 图像增强以适应人的视觉感观Enhancement to Facilitate Manual Inspection (UG2 Evaluation Task 1)
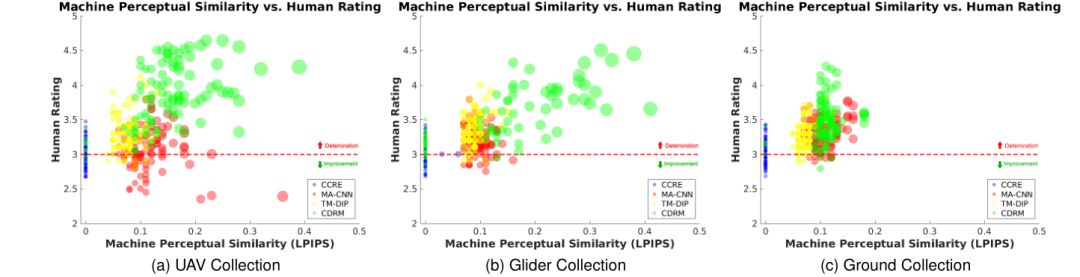

2. 图像增强用于提升物体识别精度Evaluation of Object Recognition Performance (UG2 Evaluation Task 2)
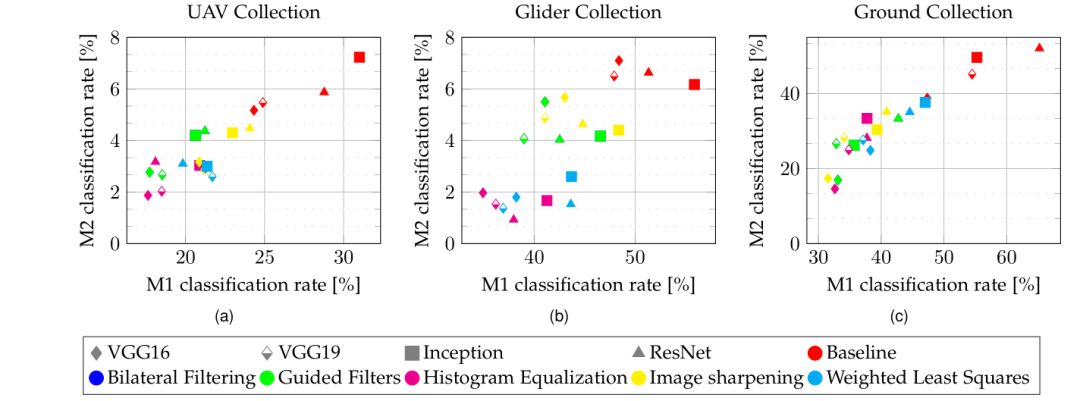
结论与展望
首先可以确定的是,图像增强算法对于图像质量的提升,远没有解决物体识别的问题。在上述介绍的图像增强算法中,没有一种可以同时在UG2数据集的多个场景中都取得比其他算法更好的识别提升。而且像MA-CNN和CDRM等算法想用一个网络框架解决多种降质因素,往往对图像的质量有损害,而且对提升识别精度也无益。当多种增强手段配合使用时,往往可以取得很好的效果。
Reference
1. Bridging the Gap between Computational Photography and Visual Recognition. arXiv:1901.09482

点击下方图片或点击文末阅读原文,了解课程详情

历史文章推荐:
CVPR2019 | 专门为卷积神经网络设计的训练方法:RePr
深度神经网络模型训练中的最新tricks总结【原理与代码汇总】
基于深度学习的艺术风格化研究【附PDF】
最新国内大学毕业论文LaTex模板集合(持续更新中)
基于深度学习的图像超分辨率最新进展与趋势【附PDF】
t-SNE:最好的降维方法之一
年龄估计技术综述
钱学森:再谈开放的复杂巨系统
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
点击下方阅读原文了解课程详情↓↓
若您觉得此篇推文不错,麻烦点点好看↓↓

