性能加速最高可达28倍!这个NLP工具包太NB了!

开箱即用的产业级NLP预置任务能力Taskflow:八大经典场景一键预测。
预训练时代的微调新范式应用:三行代码显著提升小样本学习效果。
高性能预测加速:文本生成任务28倍加速效果。
传送门:
GitHub项目: https://github.com/PaddlePaddle/PaddleNLP
PaddleNLP是飞桨生态的自然语言处理开发库,旨在提升文本领域的开发效率,为开发者带来模型构建、训练及预测部署的全流程优质体验。

PaddleNLP项目自发布以来,就受到广大NLPer的关注。在2021年6月PaddleNLP官方直播打卡课中,有7000+ 用户参加PaddleNLP的项目学习和实践,加速了自身科研和业务实践进程,同时也带动PaddleNLP多次登上GitHub Trending榜单。

1. 开箱即用的产业级NLP预置任务能力——Taskflow
本次Taskflow升级覆盖自然语言理解(NLU)和生成(NLG)两大场景共八大任务,包括中文分词、词性标注、命名实体识别、句法分析、文本纠错、情感分析、生成式问答和智能写诗。
这些高质量模型的背后,一方面聚合了百度在语言与知识领域多年的业务积淀和领先的开源成果:如词法分析工具LAC、句法分析工具DDParser、情感分析系统Senta、文心ERNIE系列家族模型、开放域对话预训练模型PLATO、文本知识关联框架解语等;另一方面也涵盖了开源社区优秀的中文预训练模型如CPM等。
未来Taskflow会随着PaddleNLP的版本迭代不断扩充技能,如开放域对话、文本翻译、信息抽取等能力,以满足更多NLP开发者的需求。
如下图所示,通过PaddleNLP Taskflow,只需要一行代码,传入任务名称即可自动选择最优的预置模型,并且以极致优化的方式完成推理,开发者可以方便地集成到下游的应用中。

▲ 图:Taskflow使用示意图
2. 预训练时代的微调新范式应用:三行代码提升小样本学习效果
结合最新的Prompt Tuning的思想,PaddleNLP中集成了三大前沿FSL算法:
(1)EFL (Entailment as Few-Shot Learner)[1],将 NLP Fine-tune任务统一转换为二分类的文本蕴含任务。
(2)PET (Pattern-Exploiting Training)[2],通过人工构建模板,将分类任务转成完形填空任务。
(3)P-Tuning[3]:自动构建模板,将模版的构建转化为连续参数优化问题。
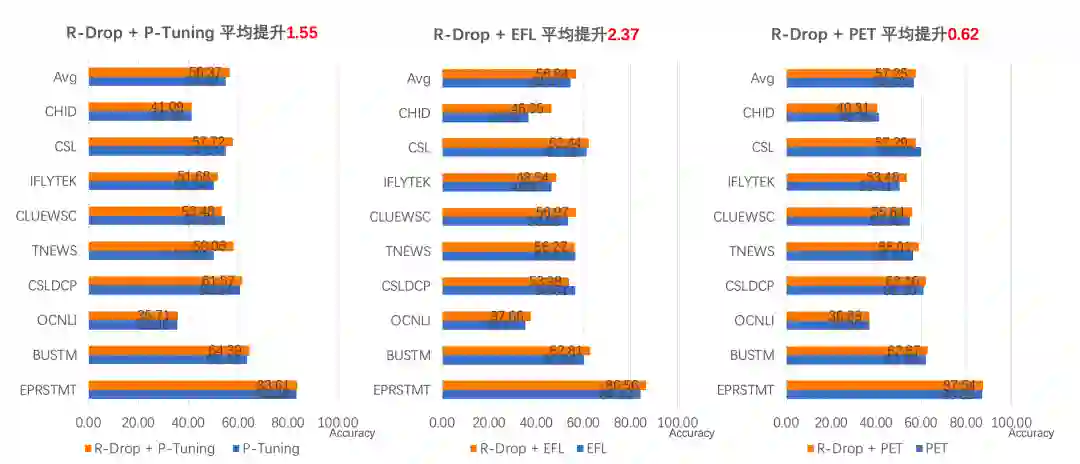
使用小样本学习策略,仅仅32条样本即可在电商评论分类任务上取得87%的分类精度[4]。此外,PaddleNLP集成 R-Drop 策略作为 API,只需要增加三行代码即可在原任务上快速涨点,如图所示:
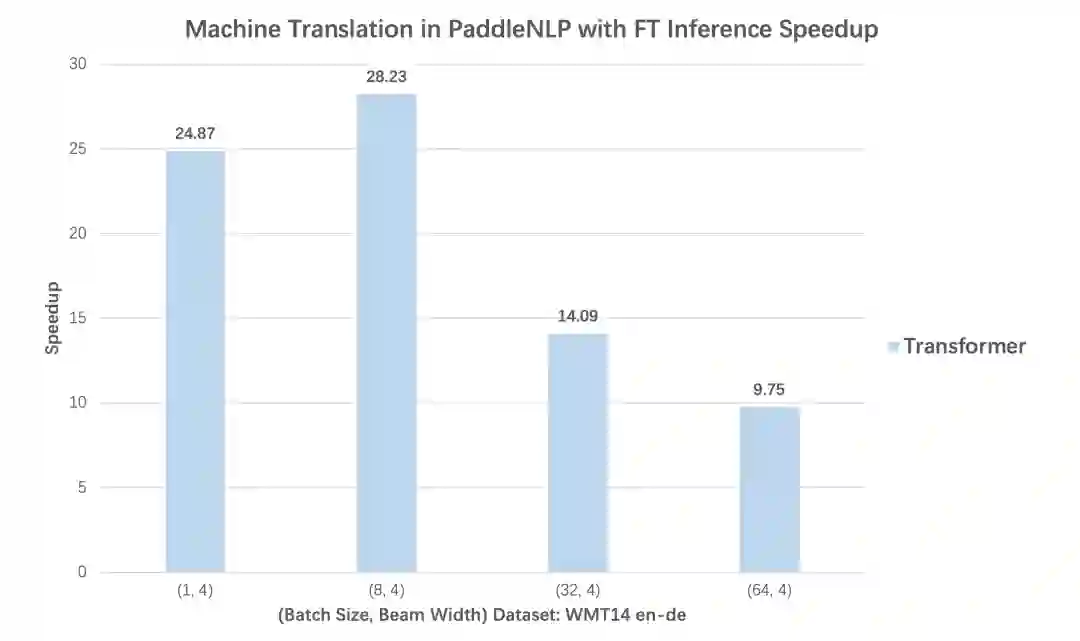
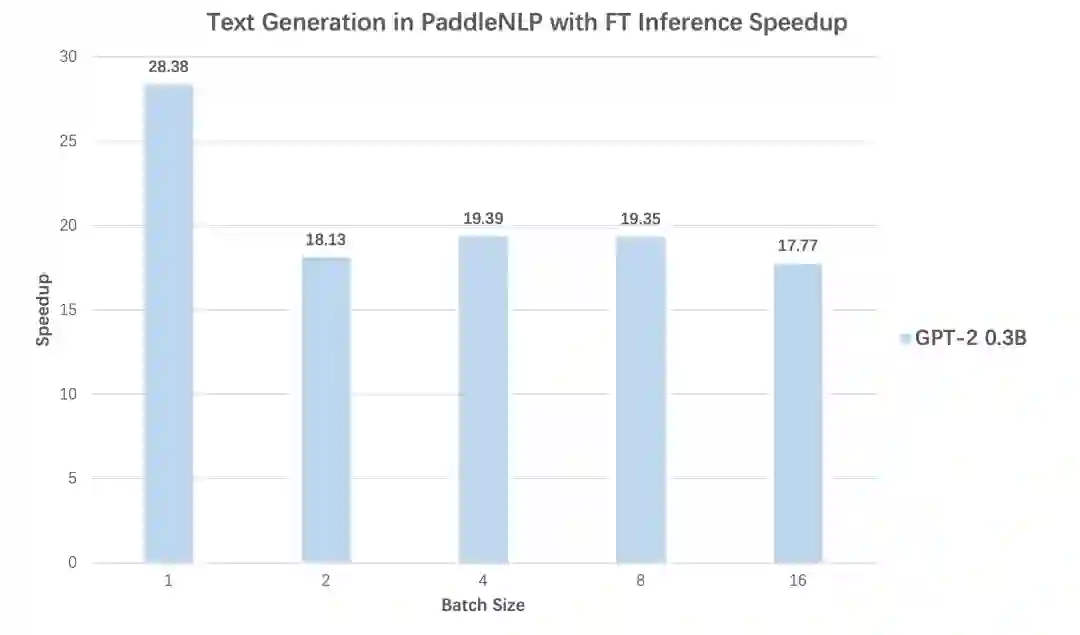
3. 高性能预测加速:文本生成场景高达28倍加速效果
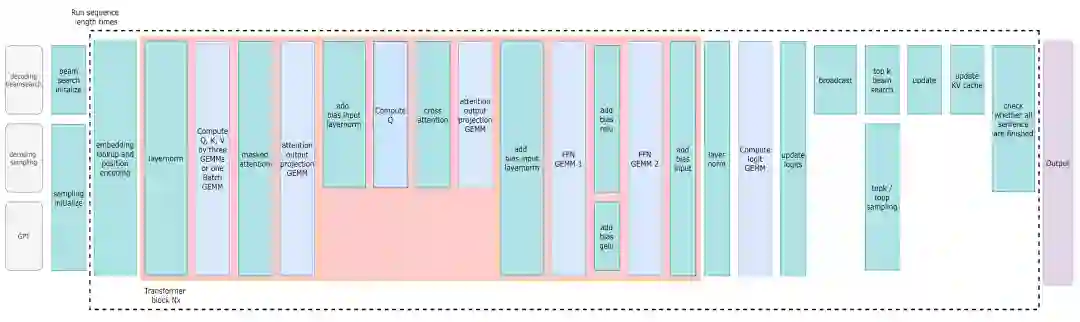
▲ FasterTransformer Decoding Workflow


(2)支持丰富的经典解码策略

更多PaddleNLP加速使用文档可以参考:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/advanced_guide/fastertransformer.rst
别的不需要多说了,大家访问GitHub点过star之后自己体验吧:
https://github.com/PaddlePaddle/PaddleNLP


除了重磅发版以外呢,我们还为大家精心准备了配套课程,在10月13-15日,连续三天PaddleNLP技术精讲课程,百度飞桨的明星讲师们历时一个月呕心沥血打磨的三日课,小伙伴们速度扫码报名,快速get PaddleNLP最新技能点!


官网地址:https://www.paddlepaddle.org.cn
PaddleNLP 项目地址:
GitHub: https://github.com/PaddlePaddle/PaddleNLP
Gitee: https://gitee.com/paddlepaddle/PaddleNLP

参考文献
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧






